
2021. 11. 25. 18:21ㆍETC/ML & DL
Good Deep Learner
내용에 들어가기 전에, 좋은 딥러너가 되기 위한 자격에는 어떤 것이 있을까요?
✔️ Implementation Skills : 실제로 구현할 수 있는 능력 (Tensorflow, Pytorch etc...)
✔️ Math Skills : Linear Algebra, Probability etc
✔️ Knowing a lot of recent Papers
Deep Learning ?

Artificial Inteligence 은 사람의 지능을 모방하는 모든 것들을 의미합니다.
Machine Learning 은 강아지와 고양이를 분류하는 문제를 풀고자 했을 때, 수많은 강아지와 고양이 이미지를 통해 자동으로 분류하는 알고리즘(모델)을 만드는 것이 있습니다.
Deep Learning 은 Maching Learning의 기술에서 Neural Network를 통해 데이터를 학습하는 세부적인 분야를 의미합니다.
Key Components
Deep Learning의 핵심 요소에는 Data, Model, Loss, 그리고 Algorithm이 있습니다. 새로운 논문이나 연구를 봤을 때, 이 네 가지 요소를 확인하면 어떤 장점과 어떤 contribution이 있는지 참고할 수 있어서 그 연구를 더 잘 이해할 수 있습니다. 하나씩 살펴보겠습니다.
Data
The data that the model can learn from
첫 번째로는 학습을 위한 데이터입니다. 위의 예시와 같이 강아지와 고양이를 분류하는 문제가 있을 때, 강아지와 고양이에 해당하는 대량의 데이터가 필요합니다. 혹은 자연어를 처리한다고 하면 말뭉치 데이터가 필요하고, 비디오를 다룬다고 하면 수많은 유튜브와 같은 영상 데이터들이 필요하게 됩니다.
Data depend on the type of the problem to solve.
데이터는 풀고자하는 문제의 유형에 따라 결정됩니다. 여기서 말하는 풀고자 하는 문제 유형에는 아래의 5가지가 있습니다.

✔️ Classification
: 강아지와 고양이를 분류하는 문제와 같이 개체를 분류하는 문제
✔️ Semantic Segmentation
: 각 이미지의 각 픽셀이 어느 클래스에 속하는지 (도로, 사람, 동물 - dense classification을 구별하는 문제) 를 분류하는 문제
✔️ Detection
: Semantic Segmentation과 비슷하지만 물체에 대한 바운딩 박스를 찾아내는 문제
✔️ Pose Estimation
: 한 사람의 3차원(혹은 2차원) skeleton 정보
✔️ Visual QnA
: 질문이 던져졌을 때 그 답을 말할 수 있는 문제
Model
The model how to transform the data
데이터를 통해 무엇인가를 학습하는 모델이 필요합니다. 강아지를 분류하는 문제가 있을 때 강아지 이미지를 입력으로 넣으면 '강아지'라는 Label이 출력되게끔 만드는 거죠. 즉, 이미지를 라벨로 변경해주는 모델이 필요하게 됩니다. 이 모델을 정의하고 학습하는 것이 중요합니다.

모델은 이미지가 주어지거나 텍스트, 단어 등이 주어졌을 때 직접적으로 알고싶은 것(라벨 등) 바꿔줍니다.
같은 데이터나 테스크가 주어져도 모델의 성질에 따라서 성능이 정해지고 더 나은 성능을 위해 테크닉들을 추가하고 그 테크닉들을 살펴보도록 해야합니다.
Loss
The loss function that quantifies the badness of the model
모델을 학습하기 위한 loss function이 필요합니다.
The loss function is a proxy of what we want to achieve
모델과 데이터가 정해져있을 때, 모델을 어떻게 학습할지를 나타냅니다.
학습을 하면서 결국 Neural Network형태를 가지게 됩니다.
각각 weight와 bias로 이루어져 있을텐데 그 weight의 각각 파라미터를 어떻게 업데이트할 것인지를 판단하도록 합니다.
문제 유형에 따라 아래와 같은 Loss Function를 자주 사용하곤 합니다.
✔️ Regression Task
$MSE = \frac{1}{N} \sum_{i=1}^{N} \sum_{d=1}^{D} (y_i^{(d)}-\hat{y}_i^{(d)})^2 $
출력값과 Target점의 제곱을 최소화(일반적인 목표) - 제곱을 평균해서 줄이는 Mean Squared Error
✔️ Classification Task
$CE = -\frac{1}{N} \sum_{i=1}^{N} \sum_{d=1}^{D} y_i^{(d)} \log \hat{y}_i^{(d)}$
CE는 Crossentropy Loss의 약자
✔️ Probabillistic Task
$MLE = \frac{1}{N} \sum_{i=1}^{N} \sum_{d=1}^{D} \log \mathcal{N}( y_i^{(d)} ;\log \hat{y}_i^{(d)}, 1) \ \ {\scriptsize (=MSE)}$
확률적인 모델을 사용한다면, 값에 대한 평균과 분산 등을 사용한다면 Maximum Likelihood Estimation 사용
사실 Loss function이 줄어든다고 해서 우리가 원하는 결과를 얻는다고는 할 수 없습니다.
예를 들어 MSE를 사용해서 큰 에러 값이 나올 때 전체 학습률을 줄어드는 영향을 줄 수 있습니다. 그래서 절댓값을 주어주는 등의 어떻게 해결해나아갈지를 알아보는 것이 중요히죠.
대부분은 맞지만 회귀라고해서 항상 MSE로 푼다는 것 아니고, 상황에 맞는 Loss Function을 적용하면 됩니다.
optimization Algorithm
The algorithm to adjust the parameters to minimize the loss
loss function을 최소화하기 위한 알고리즘이 필요합니다.

최적화 방법 ? 네트워크를 어떻게 줄일지를 판단합니다. SGD와 같이 first order method - 1차 미분한 정보를 활용합니다. 학습이 오히려 잘 안되게 하는 방법을 추가하기도 하는데, 그 이유는 loss function을 무식하게 줄이는 것보다 학습하지 않은 데이터에서 잘 동작하는 것이 목적이기 때문입니다.
Overview
2012 - AlexNet

인공지능의 Classification 대회인 ILSVRC에서 2012년에 당시 오차율 16.4%로 다른 모델들을 압도하고 우승한 모델입니다.
쉽게 말해 2024 x 2024 이미지가 들어왔을 때 분류하는 것이 목표인 대회에서 AlexNet이 1등을 합니다. 이전에는 고전적인 머신러닝의 조합이 1등을 했는데, AlexNet은 딥러닝을 사용해서 1등을 하고 나서 black magic ~
2013 - DQN

DQN은 AI의 최강자인 Google Deepmind에서 개발한 알고리즘입니다.
Deepmind 알파고 개발사로 유명하죠.
2014 - Encoder / Decoder

input Sequence를 다른 언어에 해당하는 output Sequence로 바꿔는 것을 연구합니다.
예를 들어 중국어 단어 Sequence를 영어 단어 Sequence로 변환하는 작업이 있습니다.
2014 - Adam Opimizer
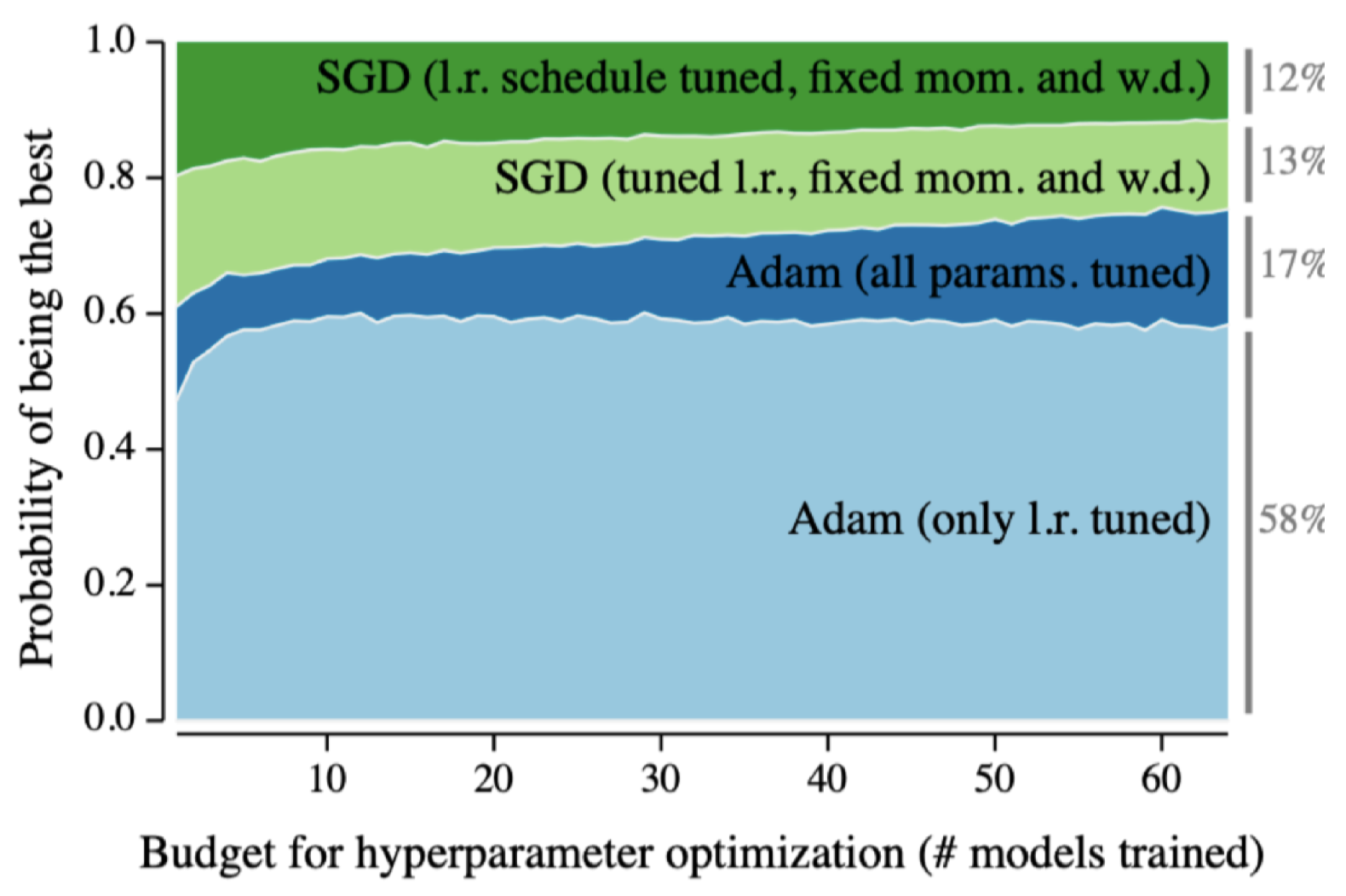
아담은 아주 많이 사용하는 옵티마이저입니다.
왜 아담을 사용할까? 이유는 결과가 잘나와서. 일반적인 딥러닝 논문을 읽다보면 희한한 짓을 하는데 대부분 어떤 언급없이 아담을 쓰곤 합니다. 그렇게 하지 않으면 같은 결과가 복원이 안될 수도 있기 때문! (더 안좋은 성능이 나올 수 있음) ..
즉, 웬만하면 잘된다.
2015 - GAN
Generative Adverdarial Network

Generative Adverdarial Network는 비지도 학습에 사용되는 인공지능 알고리즘으로, 제로섬 게임 틀 안에서 서로 경쟁하는 두 개의 신경 네트워크 시스템에 의해 구현됩니다. 굉장히 중요한 부분입니다.
이 논문의 마지막에는 특이하게 술집 이름이 언급되었다고 해요,,ㅎㅎ 술집에서 술을 마시는데 술이 너무 맛없어서 해당 연구에 대한 생각을 하게 되었다는,,🤣
2015 - Residual Networks
딥러닝의 딥러닝이 가능하게 해줬다고 할 수 있다는...

이 전에는 네트워크 층을 너무 깊게 쌓으면 좋지 않은 성능이 나왔는데, Residual Networks이 나온 다음엔 테스트 데이터의 성능이 좋게끔 만들어주었습니다.
👉🏻 깊게 쌓을 수 있게 만들어준 전환점입니다.
2017 - Transformer

2018 - BERT
fine-tuned NLP models

BERT는 Language Model입니다. fine-tuned NLP models.
이전의 단어로 다음 단어를 예측하는 것입니다. 예를 들어 만약 정말 멋진 뉴스를 쓰고 싶은데 세상엔 뉴스에 대한 데이터가 그렇게 많지 않죠. 이 때, 위키피디아와 같은 대용량 말뭉치 데이터를 사용해서 pretrained를 진행하고 fine tuning을 하는 것입니다.
2019 - BIG Language Models

BERT의 끝판왕이라고 할 수 있습니다. 마찬가지로 Language Model입니다. 아주 큰 파라미터를 가지기 때문에 Big - 이 붙었다고 합니다.
2020 - Self Supervised Learning

2020년도의 트렌드를 하나만 꼽으라면 단연코 "Self Supevised Learning"를 말할 수 있다고 합니다. 이 방법론은 이미지와 분류와 같은 분류 문제를 풀고 싶은데 학습데이터는 한정되어 있는 것에서 시작되었습니다.
학습데이터 외에 라벨을 모르는 데이터를 가지고 학습시키겠다는 것입니다. 예를 들어 구글 이미지 중 라벨을 모르는 이미지들을(그냥 정말 랜덤한 이미지) 가지고 와서 강아지와 고양이를 구별하는 학습하는 것에 추가하겠다는 것입니다.
SimCLR이 굉장히 성공하고 그 이후 많은 연구들이 진행되고 있다고 합니다.
또, 한가지 다른 트렌드로는 이미지가 주어졌을 때 도메인 지식이나 시뮬레이터를 사용해서 데이터셋을 오히려 만들어내는 연구가 진행중이라고 합니다.
참고
'ETC > ML & DL' 카테고리의 다른 글
| Deep Neural Networks, 딥러닝 (0) | 2021.11.17 |
|---|---|
| Logistic Regression (0) | 2021.11.05 |
| Linear Regression (1) | 2021.11.04 |
| DeepSORT, 제대로 이해하기 (8) | 2021.10.08 |
| Pandas, 어렵지 않게 시작하기 2 - Dataframe (0) | 2021.09.15 |

Backend Software Engineer
𝐒𝐮𝐧 · 𝙂𝙮𝙚𝙤𝙣𝙜𝙨𝙪𝙣 𝙋𝙖𝙧𝙠