
2021. 11. 17. 17:51ㆍETC/ML & DL
Deep Neural Networks
딥러닝은 머신 러닝의 한 분야입니다.
머신러닝을 하면서 예측이나 분류에 대한 문제를 선형회귀와 논리회귀를 이용하여 1차 함수를 통해 문제를 해결했습니다.
하지만, 현실의 문제를 풀기에는 직선으로 설명할 수 없는 문제들이 훨씬 많습니다.
예를 들어 딥러닝을 이끌어낸 XOR 문제 등이 있어요. 궁금하시다면 따로 찾아보길 권장합니다 ~

선형 회귀를 통해 풀 수 없는 문제들을 풀기 위해 비선형이 되는 학습 모델을 정하게 되었습니다.
비선형의 형태를 만들려면 어떻게 해야할까요?
기존 방식의 선형 회귀를 여러 번 사용한다고 해서 비선형이 되지는 않아요.
그래서 선형 회귀를 사이에 비선형을 만들어주는 층들을 쌓아 올리기 시작합니다.

위와 같이 층을 여러개 쌓으니 실제로 기대만큼의 동작을 했고, 층 Layer 을 깊게 Deep 쌓는다고 해서 딥러닝이라고 부르기로 했습니다. 각각의 Layer들은 서로 연결이 되어 있는데요. 이런 구조들을 생물학적 신경망의 뉴런의 구조와 비슷하다고 해서 Deep Neural Networks, MultiLayer Perceptron이라고도 부릅니다.

Perceptron은 위 그림의 구조를 띄는, 여러개의 input layer을 가중치와 계산해서 output layer로 도출해내는 구조입니다. 수식으로 나타내면 아래와 같죠.
$y=w_0+w_1x_1+w_2x_2$
Layer
딥러닝에서 네트워크의 구조는 크게 3가지로 나누어집니다.
Input Layer
입력층. 네트워크의 입력 부분.
우리가 학습시키고 싶은 x 값입니다.
Output Layer
출력층. 네트워크의 출력 부분.
우리가 예측한 결과 값 y 입니다.
Hidden Layers
은닉층. 입력층과 출력층을 제외한 모든 중간 층.
인공 신경망에서는 성능을 높이기 위해 입력데이터에 대해 연속적인 학습을 진행합니다. 이 연속적인 학습을 위해 입력층과 출력층 사이에 밀집층을 추가합니다. 입력층과 출력층 사이에 있는 모든 층을 밀집층 = 은닉측 이라고 부릅니다.
입력층과 출력층의 모양은 정해져 있고, 따라서 우리가 신경써야할 부분은 은닉층입니다. 은닉층은 완전연결 계층 (Fully connected layer = Dense layer)으로 이루어져 있지요. 기본적인 DNN에서는 보통 은닉층의 중간 부분을 넓게 만드는 경우가 많은데요. 은닉층의 뉴런 개수를 정하는 것은 특별한 기준이 없지만, 은닉층의 뉴런이 출력층의 뉴런보다 적으면 부족한 정보가 전달되겠죠. 그래서 층을 구성하는데에는 상당한 경험이 필요합니다.
예를 들면 아래와 같이 노드의 개수가 점점 늘어나다가 줄어드는 방식으로 구성합니다.
입력층의 노드 개수 4개
첫 번째 은닉층 노드 개수 8개
두 번째 은닉층 노드 개수 16개
세 번째 은닉층 노드개수 8개
출력층 노드개수 3개
성능을 위해서는 활성화 함수의 위치도 중요한데요. 대부분 모든 은닉층 바로 뒤에 위치합니다.
여기서 말하는 활성화 함수가 무엇일까요?
Activation functions
활성화 함수라고 해서 어려워 보이지만, 유래를 알아보면 단번에 익힐 수 있어요.
위에서 딥러닝은 다른 이름으로 MLP(MultiLayer Perceptron)라고 불린다고 했어요. 겹겹히 쌓인 레이어가 복잡하게 연결되어 있는 구조입니다. 이 구조는 수많은 뉴런들이 서로 빠짐없이 연결되어 있는 모습과 비슷한데요. 실제로 활성화 함수는 뇌의 뉴런이 다음 뉴런으로 전달할 때 보내는 전기신호의 특성에서 영감을 받아 만들어졌어요.
뉴런들은 전기 신호의 크기가 특정 임계치(Threshold)를 넘어야만 다음 뉴런으로 신호를 전달하도록 설계되어 있습니다. 연구자들은 뉴런의 신호전달 체계를 흉내내는 함수를 수학적으로 만들었는데, 전기 신호의 임계치를 넘어야 다음 뉴런이 활성화 한다고해서 활성화 함수라고 부릅니다.
활성화 함수가 바로 딥러닝에서 사용하는 비선형 함수입니다. 위에서 선형 회귀만으로는 풀 수 없어서 비선형 함수를 중간중간에 넣어준다고 했을 때, 그 비선형함수죠. 비선형 함수의 대표적인 예가 바로 시그모이드 함수입니다. 시그모이드 함수는 지난 포스팅에서 다루었는데, 궁금하다면 확인해보세요!
활성화 함수는 아래와 같이 여러 종류가 있습니다.
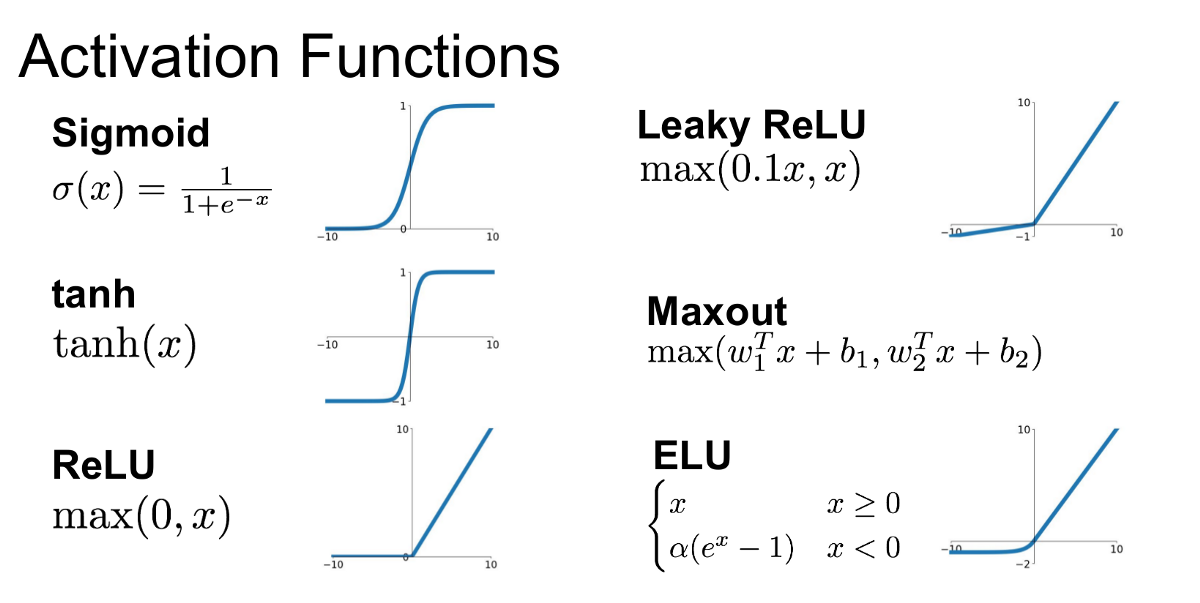
딥러닝에서 가장 많이 사용하는 활성화함수는 ReLU(렐루) 입니다. 다른 활성화 함수에 비해 학습이 빠르고, 연산 비용이 적고, 구현이 간단하기 때문입니다.
ReLU 함수
대부분 딥러닝 모델을 설계할 때는 ReLU를 기본적으로 많이 쓰고, 여러 활성화 함수를 교체하는 노가다를 거쳐 최종적으로 정확도를 높이는 작업을 동반합니다. 이 과정을 모델 튜닝이라고 부릅니다.
Practice
kaggle에서 제공하는 데이터셋을 사용해서 실제로 딥러닝을 실습해보겠습니다.
Colab의 jupyter notebook 은 링크를 통해 확인할 수 있습니다.
MNIST
Modified National Institute of Standards and Technology database.
실습할 데이터셋 MNIST는 (Modified National Institute of Standards and Technology database, 수정된 미국 국립표준기술연구소 데이터베이스)입니다.
MNIST 데이터베이스는 손으로 쓴 0-9까지의 숫자 이미지 모음입니다. 기계 학습 분야의 트레이닝 및 테스트에 널리 사용되며, 다양한 화상 처리 시스템을 트레이닝하기 위해 일반적으로 사용됩니다.
Modified NIST
NIST의 테스팅 데이터셋이 기계 학습 실험에 딱 적합하지는 않아 변경되었다고 합니다.
MNIST Dataset
60,000개의 트레이닝 이미지와 10,000개의 테스트 이미지를 포함합니다.
Kaggle에서 Dataset 받아오기
kaggle에서 데이터를 받아오려면 API key를 발급받아야 합니다.
Using Kaggle's beta API, you can interact with Competitions and Datasets to download data, make submissions, and more via the command line.
- kaggle 회원가입/로그인
- kaggle profile > Account Tab
- API - Create New API Token Button 선택
- kaggle.json 확인
{"username":"kaggle_name","key":"api_key"}
참고로 json 파일은 크롬에 끌어넣으면 쉽게 확인할 수 있습니다!
import os
os.environ['KAGGLE_USERNAME'] = 'kaggle_username'
os.environ['KAGGLE_KEY'] = 'api_key'
Dataset Download
!kaggle datasets download -d oddrationale/mnist-in-csv
!unzip mnist-in-csv.zip
Dataset Load
pandas.read_csv() : csv를 읽어서 pandas의 자료구조인 DataFrame으로 변환해줍니다.
train_df.head([N]) : DataFrame의 상위 데이터 N개를 보여줍니다. (default는 5)
import pandas as pd
train_df = pd.read_csv('mnist_train.csv')
test_df = pd.read_csv('mnist_test.csv')
Dataset 확인
그래프로 데이터가 어떻게 분포되었는지 확인해볼게요.
Package
matplotlib 은 아주 유명한 Python 데이터 시각화 패키지입니다. 다양한 그래프를 아주 손쉽게 그릴 수 있습니다.
자세한 내용은 matplotlib 문서 를 확인해보세요!
seaborn 은 Matplotlib을 기반으로 다양한 색상 테마와 통계용 차트 등의 기능을 추가한 시각화 패키지입니다.
Dataset
0-9 까지의 숫자로 이루어져있으며, label은 이미지의 정답 데이터입니다.
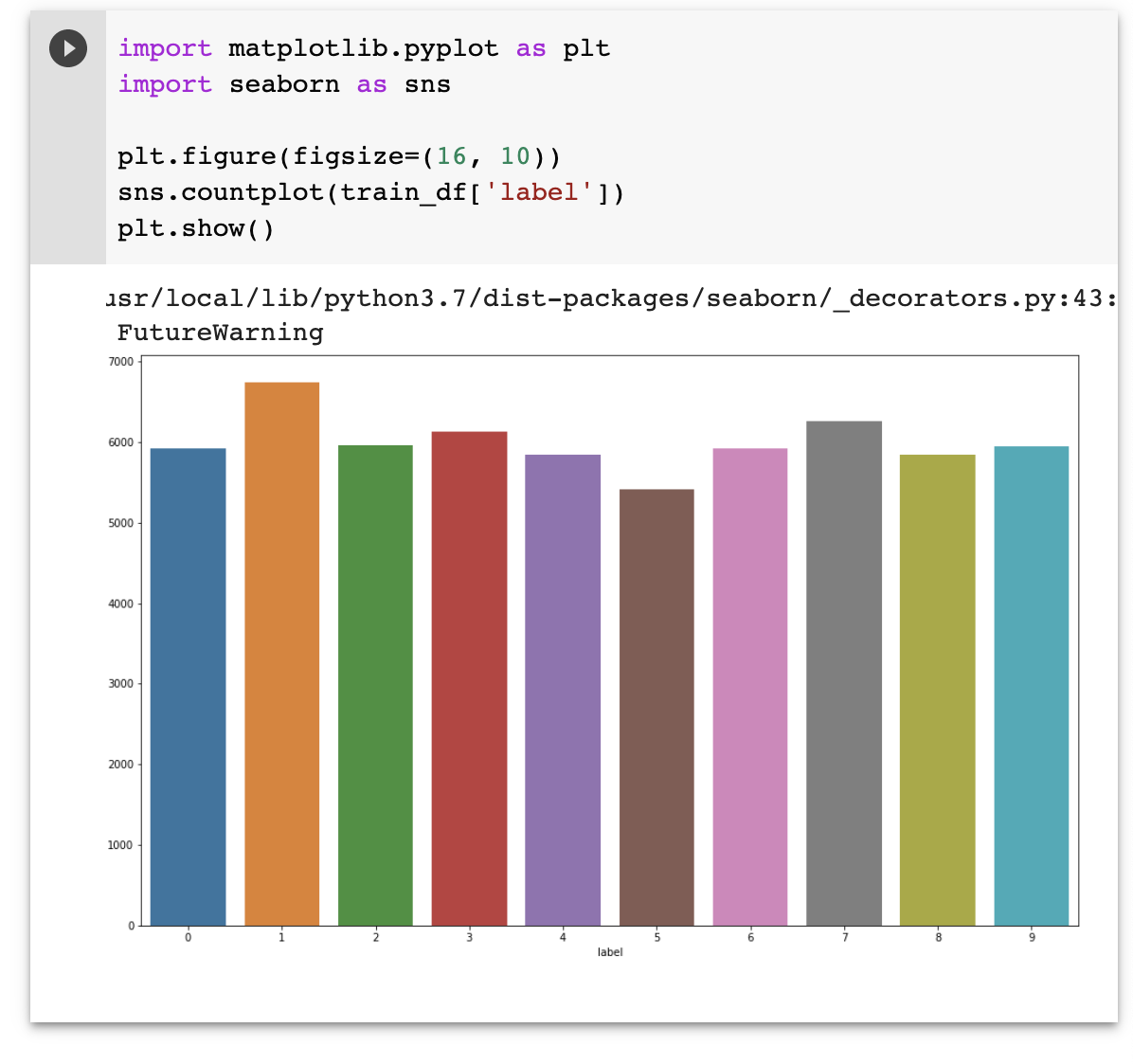
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(16, 10))
sns.countplot(train_df['label'])
plt.show()
데이터 전처리
먼저 데이터를 분류해주겠습니다.
import numpy as np
# float32 형으로 변환
# label열 제외한 train set 와 label열만 가져온 train set
train_df = train_df.astype(np.float32)
x_train = train_df.drop(columns=['label'], axis=1).values
y_train = train_df[['label']].values
test_df = test_df.astype(np.float32)
x_test = test_df.drop(columns=['label'], axis=1).values
y_test = test_df[['label']].values
이미지를 한 번 확인해볼까요?
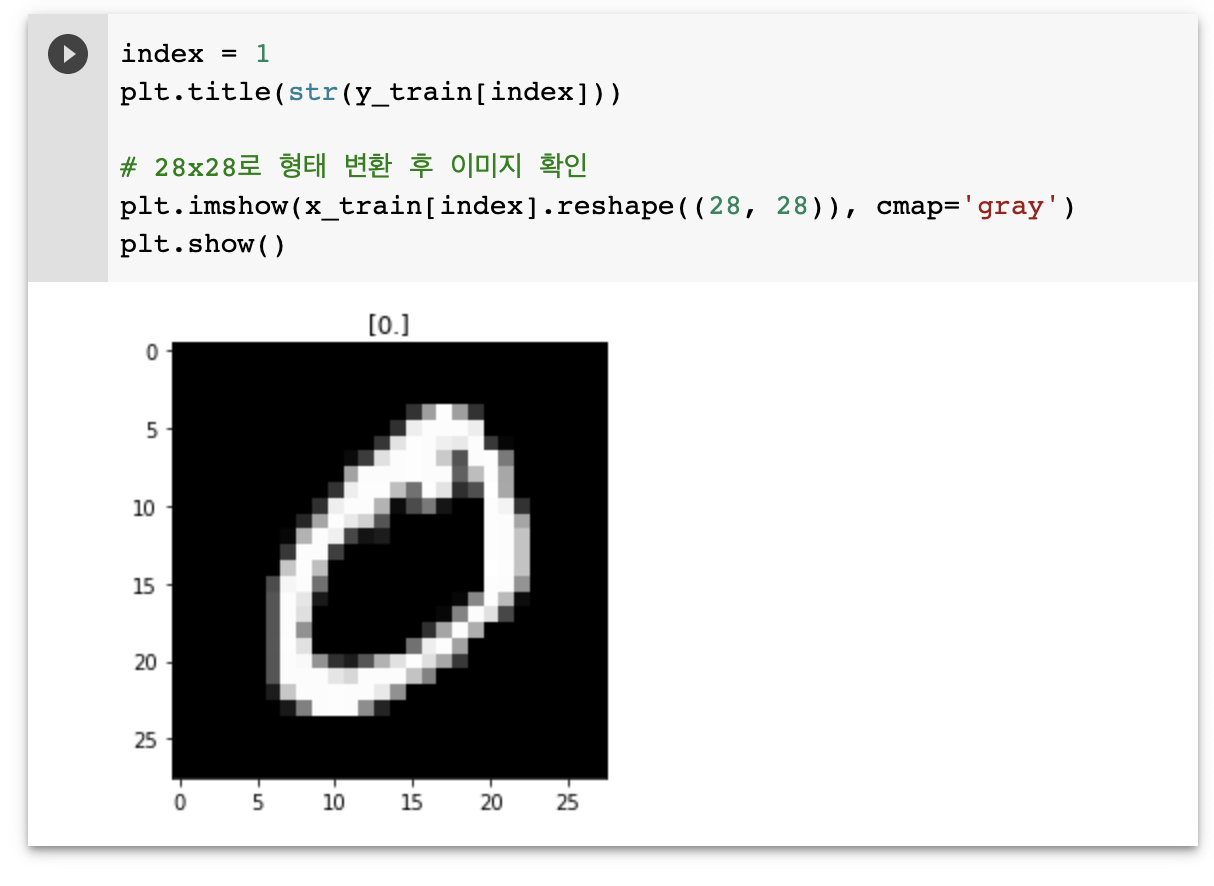
# 첫 번째 데이터
index = 1
plt.title(str(y_train[index]))
# 28x28로 형태 변환 후 이미지 확인
plt.imshow(x_train[index].reshape((28, 28)), cmap='gray')
plt.show()
이제 전처리를 진행합니다.
One Hot Encoding은 지난 포스팅에서 보았으니 생략할게요.
이미지 데이터는 픽셀이 0-255 사이의 정수이기 때문에 255로 나누어서 0-1 사이의 소수점 데이터(float32)로 바꿔서 일반화 진행합니다.
from sklearn.preprocessing import OneHotEncoder
# 전처리 - OneHotEncoder
encoder = OneHotEncoder()
y_train = encoder.fit_transform(y_train).toarray()
y_test = encoder.fit_transform(y_test).toarray()
# 전처리 - 일반화
# 이미지 데이터는 픽셀이 0-255 사이의 정수(unsigned integer 8bit = uint8)
# 0-1 사이의 소수점 데이터(float32)로 바꿔서 일반화 진행
x_train = x_train / 255.
x_test = x_test / 255.
Network : Layer 쌓기
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.optimizers import Adam
# 네트워크 구성
input = Input(shape=(784,))
# relu -> x가 0 이하일 때 y가 0, 0 초과일 때 y=x
hidden = Dense(1024, activation='relu')(input)
hidden = Dense(512, activation='relu')(hidden)
hidden = Dense(256, activation='relu')(hidden)
output = Dense(10, activation='softmax')(hidden)
model = Model(inputs=input, outputs=output)
model.compile(loss='categorical_crossentropy', optimizer=Adam(learning_rate=0.001), metrics=['acc'])
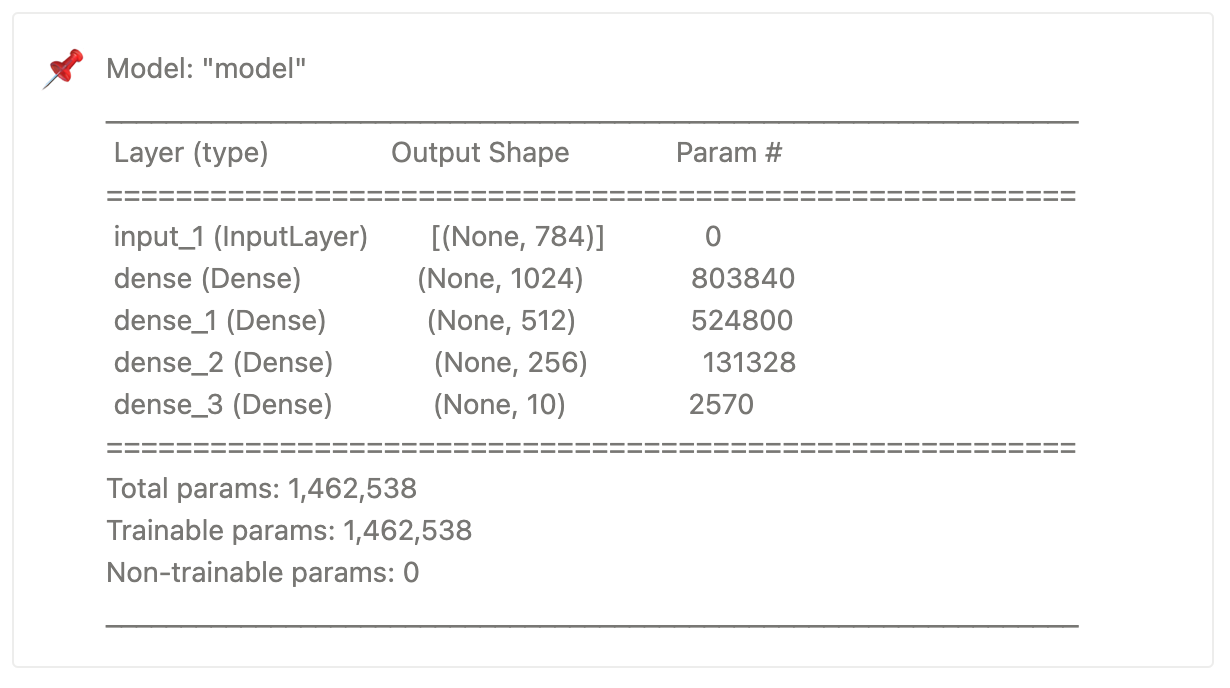
model.summary()
model.summary() 을 통해 생성된 모델을 확인할 수 있습니다.
모델 훈련시키기
네트워크를 구성했으면 이제 훈련을 시켜볼게요.
model.fit() 을 통해 학습을 시킵니다.
history = model.fit(
x_train,
y_train,
validation_data=(x_test, y_test),
epochs=20
)
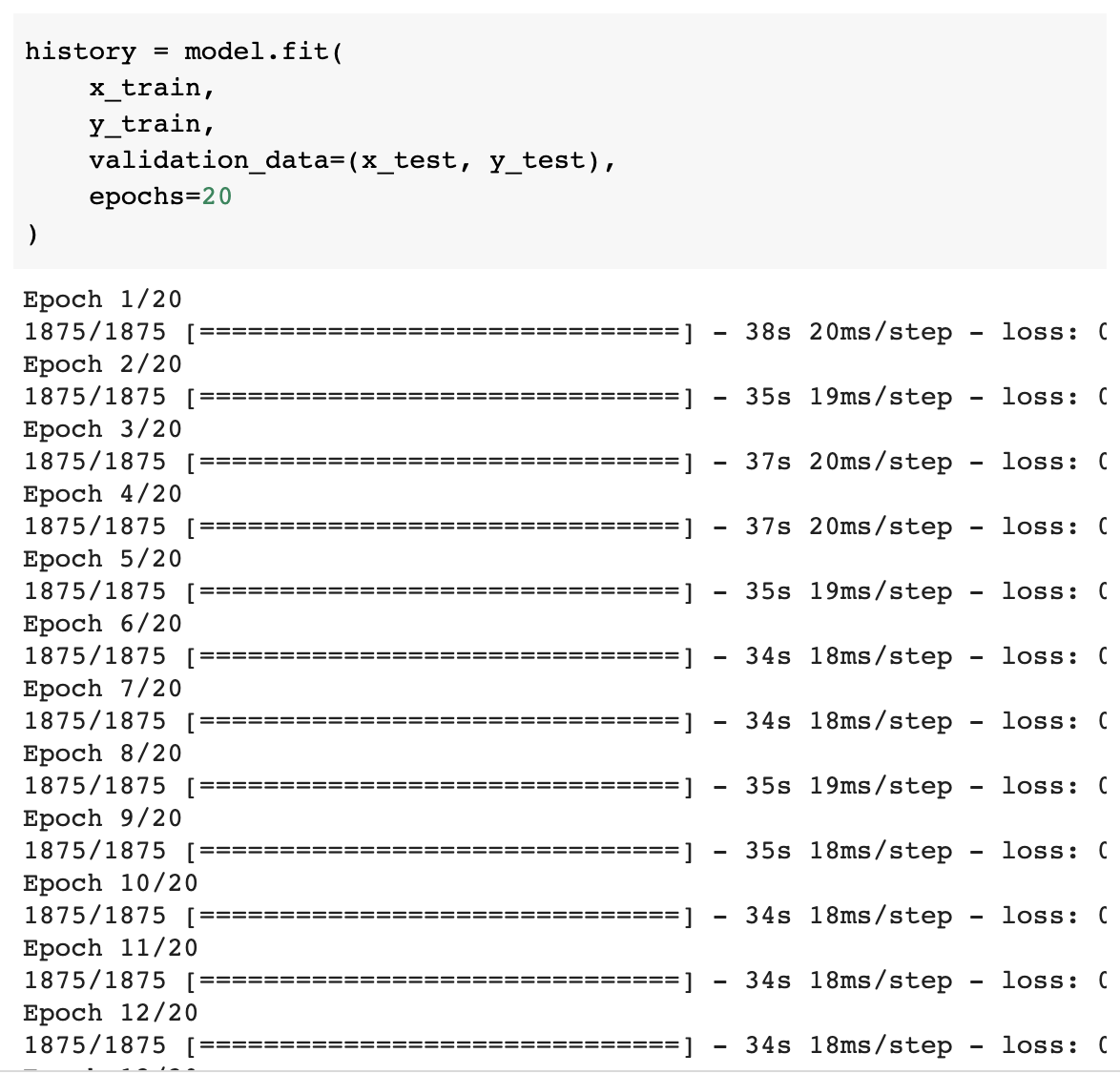
학습을 시키면 위에서 설정한대로 총 20번의 학습을 진행하는데요.
keras에서는 아래의 이미지와 같이 진행상황을 보여줍니다!
학습 결과 확인
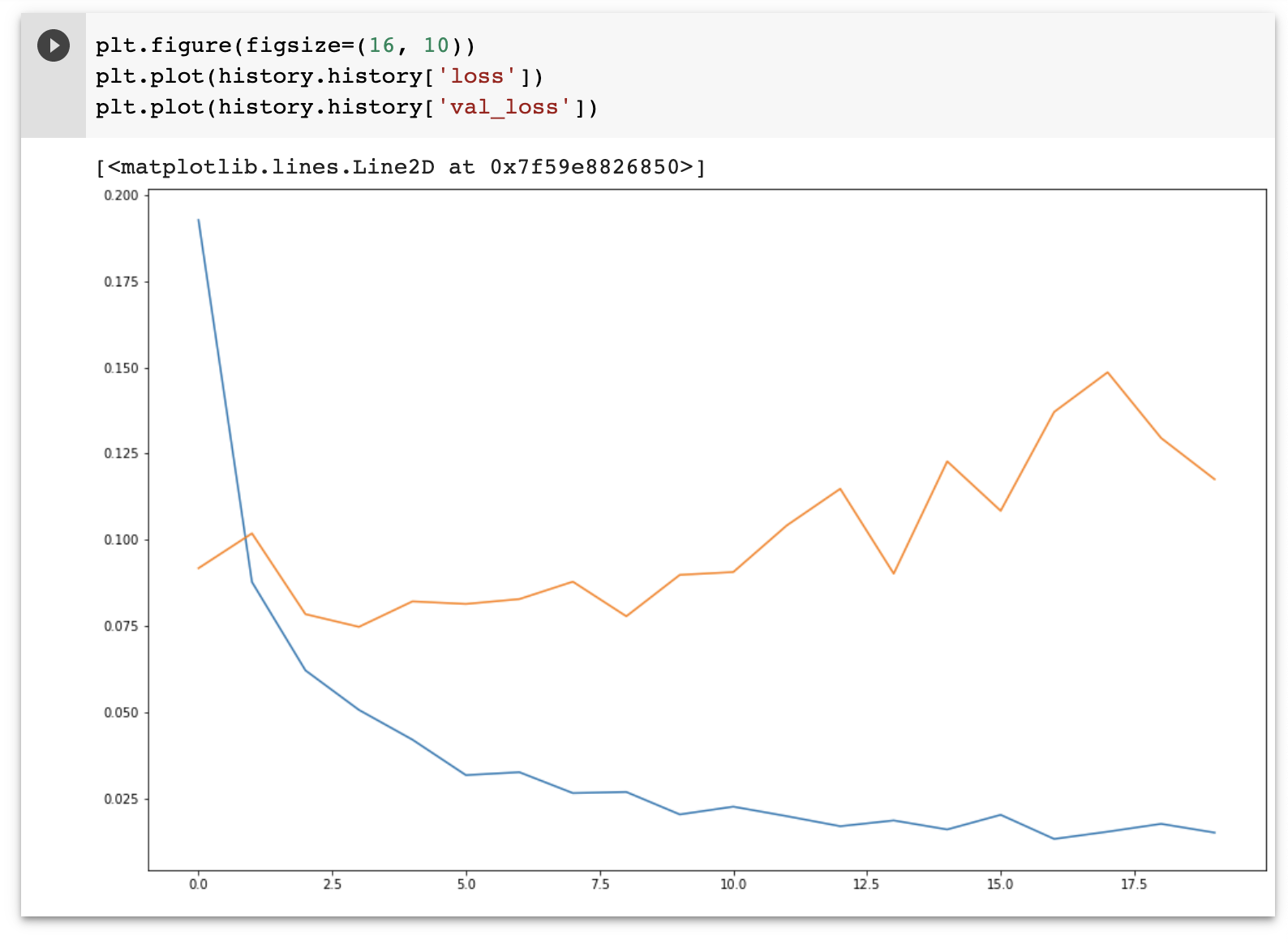
plt.figure(figsize=(16, 10))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
마지막으로, 학습에 대한 결과를 확인해보면 아래와 같은 결과를 확인할 수 있습니다.
그럼 지금까지 딥러닝에 대해 아주...조금 ...ㅎㅎ 알아보았습니다!
피드백이나 토론은 댓글로 남겨주세요 🙌🏻
참고
혼자 공부하는 머신러닝+딥러닝
[스파르타코딩클럽] 가장 쉽게 배우는 머신러닝
'ETC > ML & DL' 카테고리의 다른 글
| Deep Learning, Historical Review (0) | 2021.11.25 |
|---|---|
| Logistic Regression (0) | 2021.11.05 |
| Linear Regression (0) | 2021.11.04 |
| DeepSORT, 제대로 이해하기 (8) | 2021.10.08 |
| Pandas, 어렵지 않게 시작하기 2 - Dataframe (0) | 2021.09.15 |

Backend Software Engineer
𝐒𝐮𝐧 · 𝙂𝙮𝙚𝙤𝙣𝙜𝙨𝙪𝙣 𝙋𝙖𝙧𝙠