
2021. 9. 8. 16:33ㆍETC/ML & DL
안녕하세요. 오늘은 예전에 배운 pandas를 다시 쓸 일이 생겨서 복습할 겸 올리는 포스팅입니다.
pandas의 내용이 많아서 꽤 길어질지도 모르겠네요 🥲
간단히 적자는게 또 욕심이 커져서 ipynb 파일까지 만들었네요,,,🤦🏻♀️
아래의 코드는 Colab link를 통해 확인할 수 있습니다.
***************** INDEX *****************
🐼 pandas?
📖 Series
📊 DataFrame
📚 Stacking
📌 Pivoting
********************************************
🐼 pandas ?
Pandas는 데이터 조작 및 분석을 위해 python 프로그래밍 언어로 작성된 소프트웨어 라이브러리입니다.
특히 시계열이나 테이블을 조작하기 위한 데이터 구조와 연산을 제공하는데요.
시계열 데이터이란, 시간에 따라서 변하는 데이터를 의미합니다.
Pandas는 이런 데이터를 다루기 위한 Series Class와 DataFrame Class를 제공합니다.
Pandas 자료구조
Pandas의 자료구조인 Series와 DataFrame은 이 포스팅에서 메인으로 다룰 내용들인데요.
✔️ Series는 1차원 배열 구조
✔️ DataFrame은 2차원 배열 구조 (테이블 형식)
라는 것을 짚고 가면 도움이 될 것 같네요.
이해를 돕기위해 엑셀과 비교하자면 아래의 그림과 같습니다.

엑셀 파일 하나를 Panel, 엑셀 파일 내 하나의 시트를 DataFrame, 시트 내 하나의 열을 Series로 비유할 수 있습니다.
NumPy
참고로, Pandas는 NumPy를 기반으로 만들어진 패키지입니다.
다만 NumPy는
✔️ 데이터에 레이블을 붙이기 번거롭고,
✔️ 누락된 데이터로 작업하기 어려우며
✔️ 요소 단위의 브로드캐스팅을 벗어나는 연산이 어렵기 때문에 (그룹화, 피벗 등)
데이터를 더 쉽게 다루기 위해 Pandas를 사용합니다.
조금 더 깊이 알고 싶다면 NumPy를 같이 알아두면 좋겠죠?
Pandas 설치
# matplotlib도 주로 같이 설치하곤 하지만, pandas소개 글이니 제외했습니다.
# pip로 설치
$ pip install numpy pandas
# conda 로 설치
$ conda install numpy pandas
설치된 pandas를 확인해볼까요?
$ python
Python 3.8.0 (v3.8.0:fa919fdf25, Oct 14 2019, 10:23:27)
[Clang 6.0 (clang-600.0.57)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import pandas as pd
>>> pd.__version__
'1.2.4'
위와 같이 pandas.__version__을 통해 확인합니다.
pandas의 속성이나 메소드를 사용하기 위해서 pandas. 을 계속 사용할텐데,
대부분 import pandas as pd 를 통해 alias를 설정해서 사용합니다.
대부분이 사용하는 관습적인 표기이기 때문에 독자님들도 사용하시길 바랍니다!
📕 Series ?
Series는 NumPy 배열의 확장입니다.
파이썬의 딕셔너리와 판다스의 Series 구조가 비슷하죠.
아래에 언급하겠지만 이해를 위해 적어보자면,
딕셔너리 {키(k): 값(v)}는 시리즈의 인덱스(index)와 데이터 값(value)으로 변환됩니다.
Series 구조
먼저, Series Class는 아래와 같이 선언되어 있습니다.
공식문서에 보기 좋게 정리를 해줘서 공부할 맛 나네요,,ㅎㅎ
파라미터를 정리해봅시다!
class pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
# One-dimensional ndarray with axis labels (including time series).
✔️ data. 실제 값. array-like, Iterable, dict, or scalar value.
👉🏻 Contains data stored in Series. If data is a dict, argument order is maintained.
✔️ index. 데이터를 접근할 정보. array-like or Index (1d)
👉🏻 Values must be hashable and have the same length as data. Non-unique index values are allowed. Will default to RangeIndex (0, 1, 2, …, n) if not provided. If data is dict-like and index is None, then the keys in the data are used as the index. If the index is not None, the resulting Series is reindexed with the index values.
👉🏻 인덱스는 unique하지 않아도 되며, 입력하지 않아도 Default값이 설정됩니다. 만약, 데이터가 Dictionary 형태라면 key값이 index로 설정됩니다.
👉🏻 추가로, 인덱스는 연속적이지 않아도 됩니다.
✔️ dtype. 데이터들의 타입. str, numpy.dtype, or ExtensionDtype, optional
👉🏻 Data type for the output Series. If not specified, this will be inferred from data. See the user guide for more usages.
✔️ name. Series 인스턴스의 이름. str, optional
👉🏻 The name to give to the Series.
✔️ copy. bool, default False
👉🏻 Copy input data. Only affects Series or 1d ndarray input. See examples.
Series 선언
# Python Dictionary -> Pandas Series
pd.Series({'a': 1, 'b': 2, 'c': 3})
# Python List -> Pandas Series
pd.Series(['2021-09-08', 3.14, 'ABC', 100])
# Python Tuple -> Pandas Series
pd.Series(('gngsn', '980812', '여'))
# Python Tuple + index option + name
pd.Series(('gngsn', '980812', '여'), index=['nickname', 'birth', 'gender'], name='Student Data')
말보다 예시가 이해에 더 도움이 될 것 같네요.
위와 같이 선언하면 Series의 구조는 어떻게 보일까요?
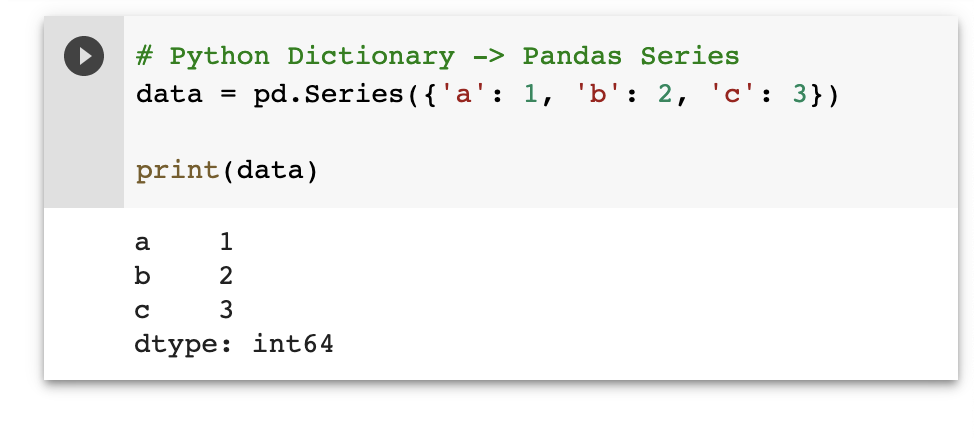
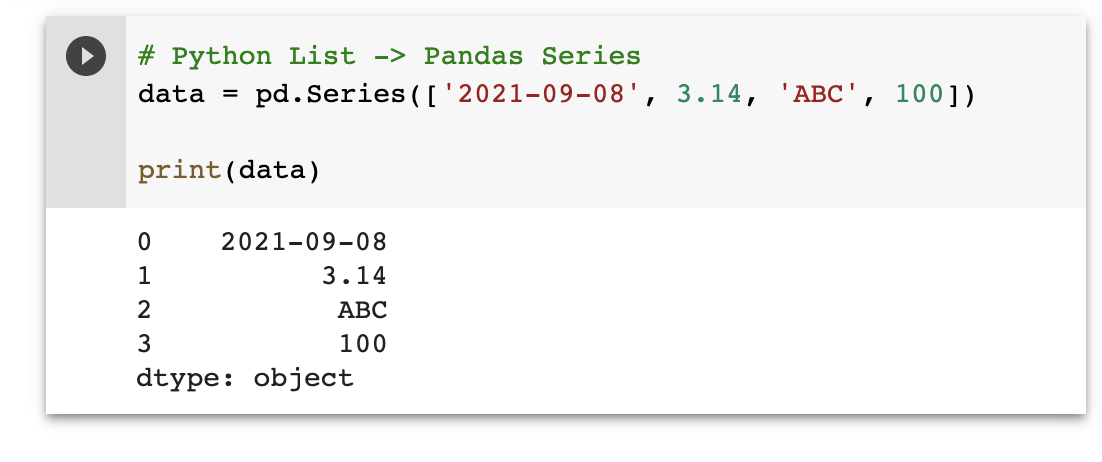


아래와 같이 코드로 구조를 확인할 수 있습니다.

⚠️ Dictionary VS Series
위의 그림에서 Series의 데이터가 Dictionary 변환된 것이 보이시나요?
key가 index가 되고, value가 data로 매칭되었습니다❗️
값을 접근할 때도 이 둘은 Hashable하게 접근합니다. (ex. data['a'])
그럼 Dictionary와 Series는 어떤 차이가 있을까요?
Dictionary와 Series 차이점은, Series는 Slicing 연산을 지원한다는 점입니다.
여기서 중요한 점은 숫자 기반의 Slicing과는 다르게 끝 인덱스 값을 포함합니다.


Series Index
Pandas에서의 인덱스는 배열과 유사하게 동작합니다.
Python의 표준 인덱싱 표기법을 사용해서 값이나 슬라이스 처리할 수 있습니다.

그림과 같이 마치 배열과 같이 접근할 수 있습니다.
그래서 슬라이싱으로 접근할 수도 있습니다.
하지만, 직접 접근은 불가능합니다.

또, 집합 연산을 지원해줍니다.
혹시나 마지막 연산을 설명하자면,,,
합집합 - 교집합 = 여집합의 합집합 (배타적 합집합)
입니다.
Series 접근
Series의 접근 방식은 Dictionary의 표현식과 동일합니다.

만약 인덱스를 지정했다면, Default로 주어지는 숫자 기반 접근이 불가능합니다.
당연한게 만약 Index를 숫자로 지정했을 때 접근을 생각해보세요!
이 부분은 명시적 인덱스와 암묵적 인덱스의 이해가 필요한데요.
# 명시적 인덱스? 암묵적 인덱스?

정수 인덱싱을 사용할 때 발생할 혼선을 방지하기 위하여 인덱싱 방식을 명시 가능합니다.
loc: location based indexing. 항상 명시적 인덱스를 참조
iloc: integer-location based indexing. 암묵적인 python 스타일의 인덱스를 참조
ix: 위의 두 가지 속성의 하이브리드 형태
# Index (Key) 값 찾기

만약, Index의 여부를 묻고 싶다면 in 구문을 사용해보세요.
# 상위/하위 데이터 N개 찾기

head(n) 를 통해 상위 n개의 데이터를 가져올 수 있고,
tail(n) 를 통해 하위 n개의 데이터를 가져올 수 있습니다.
DataFrame까지 다루고 싶었는데, 목표했던 포스팅 시간이 훌쩍,,, 지나갔네요 🤣
다음 포스팅으로 DataFrame, Stacking, Pivoting 을 알아봅시다 👊🏻
'ETC > ML & DL' 카테고리의 다른 글
| Deep Neural Networks, 딥러닝 (0) | 2021.11.17 |
|---|---|
| Logistic Regression (0) | 2021.11.05 |
| Linear Regression (1) | 2021.11.04 |
| DeepSORT, 제대로 이해하기 (8) | 2021.10.08 |
| Pandas, 어렵지 않게 시작하기 2 - Dataframe (0) | 2021.09.15 |

Backend Software Engineer
𝐒𝐮𝐧 · 𝙂𝙮𝙚𝙤𝙣𝙜𝙨𝙪𝙣 𝙋𝙖𝙧𝙠