
2022. 6. 22. 23:34ㆍSpring
Spring Batch에서 데이터 처리하는 방식을 이해하고 주요 클래스/객체를 분석하는 것이 본 포스팅의 목표입니다.
안녕하세요. 지난 포스팅에서 Spring Batch를 도장깨기 진행 중이라고 했는데요.
도장을 깨는건지 제가 도장에 깨지는건지 약간 의문인데 일단 뭐든 깨고는 있어요.
이번에는 데이터 저장에 대해 깨보려 합니다.
이번 포스팅은 Spring Batch 시리즈의 세 번째 편으로 데이터를 처리하는 방식을 다룹니다.
해당 포스팅은 ExecutionContext의 내용이 데이터 활용 편으로 분리될 예정입니다.
------------------- 📌 Spring Batch Series 📌 -------------------
Spring Batch, 제대로 이해하기 (1) - 개념 이해
Spring Batch, 제대로 이해하기 (2) - 동작 원리
✏️ Spring Batch, 제대로 이해하기 (3) - Meta Data
Spring Batch, 제대로 이해하기 (4) - 데이터 처리 활용
Spring Batch, 제대로 이해하기 (5)
- MultiResourceItemReader
----------------------------------------------------------------
ExecutionContext
배치 처리에서는 각 Job마다, 혹은 각 Step마다 공유되어야 하는 상태나 데이터가 있습니다.
이 데이터들은 안전하게 데이터베이스와 같은 지속가능한 형태로 유지되어야겠죠.
ExecutionContext는 Job을 실행하면서 필요한 데이터를 지속가능한 상태로(데이터베이스 등) 저장할 수 있도록 Spring Batch Framework에서 지원하는 key/value 데이터를 담는 공간입니다.
재미있게도 Spring에서는 " ExecutionContext를 각각의 실행 동안 유지되어야하는 사용자 데이터의 property bag속성 가방"라고 표현합니다. Spring Batch는 범위에 따라 두개의 ExecutionContext를 지원합니다.

Job ExecutionContext
JobExecution 내에서 사용되며, 각 Step에서 접근하면서 공유할 수 있습니다.
JobExecution 클래스의 executionContext 필드를 확인할 수 있는데, 아래와 같이 접근하고는 합니다.
ExecutionContext jobExecutionContext = jobExecution.getExecutionContext();
jobExecutionContext.put("key", "value");
JobRepository를 통해 저장되는 데이터 예시입니다.
mysql> select * from BATCH_JOB_EXECUTION_CONTEXT;
+-----------------+-----------------------+---------------------+
| STEP_EXEC_ID | SHORT_CONTEXT | SERIALIZED_CONTEXT |
+-----------------+-----------------------+---------------------+
| 1 | {key=value} | null |
+-----------------+-----------------------+---------------------+
1 row in set (0.00 sec)
Step ExecutionContext
Step의 ExecutionContext은 JobExecutionContext와 사용하는 방식은 동일합니다.
다만, 적용하는 범위만 다릅니다.
A Step에서만 사용할 데이터를 B Step에서 사용하고 싶지 않을 때 유요하겠죠.
만약 FlatFile을 불러오는 Reader를 예시로 든다면, 읽어오는 commit point를 아래와 같이 지정할 수 있습니다.
executionContext.putLong(getKey(LINES_READ_COUNT), reader.getPosition());
위의 코드는 어떻게 반영될까요? JobRepository에 있는 BATCH_STEP_EXECUTION_CONTEXT에 아래와 같이 저장됩니다.
mysql> SELECT * FROM BATCH_STEP_EXECUTION_CONTEXT;
+-----------------+-----------------------+---------------------+
| STEP_EXEC_ID | SHORT_CONTEXT | SERIALIZED_CONTEXT |
+-----------------+-----------------------+---------------------+
| 1 | {piece.count=40321} | null |
+-----------------+-----------------------+---------------------+
1 row in set (0.00 sec)
Store Data
ExecutionContext에 데이터가 저장될 때에는 JSON형식으로 변환하여 json문자열을 DB에 보관합니다.
예전에는 Xstream 프레임워크를 이용했는데, 3.0.7 버전 부터 Jackson2을 사용하기 시작했습니다.
Spring Batch 4에서 Xstream은 deprecate되고 Jackson2를 사용하기 시작했습니다.
Serialize
Java 객체를 JSON 형태로 Serialize해서 보관하고 Deserialize해서 가져오는 형식이죠.
기본적으로 사용하는 Serializer는 ExecutionContextSerializer를 구현한 Jackson2ExecutionContextStringSerializer입니다.
public class Jackson2ExecutionContextStringSerializer
extends java.lang.Object
implements ExecutionContextSerializer
여기서 주의할 점은, JSON 형식으로 Serialize할 수 없는 객체는 기본적인 설정으로는 저장할 수 없다는 것입니다.
만약 추가적인 기능이 필요하다면 ExecutionContextSerializer를 구현하여 사용할 수 있습니다.
이는 JobRepository를 생성할 때 (JobRepositoryFactoryBean) 설정할 수 있는데요.
참고차 StackOverflow를 확인하셔도 도움이 될것 같네요.
저도 이 부분으로 고생을 좀 해서 ,,, ㅎㅎ
추가로, Jackson2ExecutionContextStringSerializer의 TrustedTypeIdResolver라는 InnerClass을 참고하세요.
private static final Set<String> TRUSTED_CLASS_NAMES = Collections.unmodifiableSet(new HashSet(Arrays.asList(
"javax.xml.namespace.QName",
"java.util.UUID",
"java.util.ArrayList",
"java.util.Arrays$ArrayList",
"java.util.LinkedList",
"java.util.Collections$EmptyList",
"java.util.Collections$EmptyMap",
"java.util.Collections$EmptySet",
"java.util.Collections$UnmodifiableRandomAccessList",
"java.util.Collections$UnmodifiableList",
"java.util.Collections$UnmodifiableMap",
...
)));
Capacity
ExecutionContext는 결국 데이터베이스에 저장되는데요.
이 때, 주의 사항은 데이터의 사이즈입니다.
아래서 다루는 JobRepository의 BATCH_JOB_EXECUTION_CONTEXT나 BATCH_STEP_EXECUTION_CONTEXT에서 허용하는 데이터 사이즈도 확인해볼 필요가 있겠죠.
mysql> describe BATCH_JOB_EXECUTION_CONTEXT;
+--------------------+---------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------------+---------------+------+-----+---------+-------+
| JOB_EXECUTION_ID | bigint(20) | NO | PRI | NULL | |
| SHORT_CONTEXT | varchar(2500) | NO | | NULL | |
| SERIALIZED_CONTEXT | text | YES | | NULL | |
+--------------------+---------------+------+-----+---------+-------+
3 rows in set (0.01 sec)
위와 같이 2500으로 되어 있기 때문에 저장되는 데이터 사이즈를 반드시 확인해보시길 바랍니다.
그렇다면, 이렇게 데이터베이스를 통해 지속적으로 유지되어야 하는 데이터를 어떻게 관리할까요?
이와 관련한 내용을 알아보겠습니다.
Persistent Meta-Data
위에서 언급된 JobRepository와 그와 관련된 JobOperator, JobExplorer 객체로 쉽게 관리할 수 있습니다.
이제부터 이 관계와 그 속성에 대해 자세히 알아보도록 하겠습니다.
Big Picture
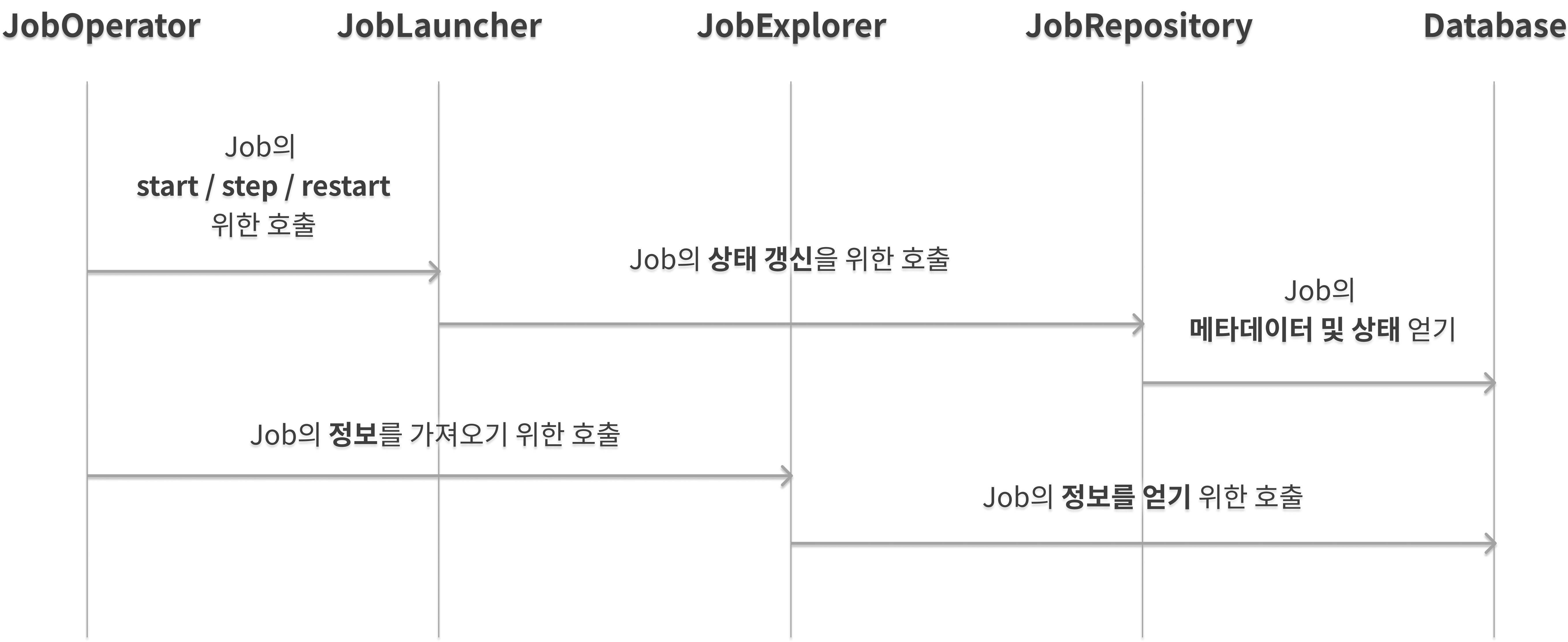
JobLauncher와 JobRepository는 간단한 Batch의 Domain Object를 사용해 CRUD를 통해 job을 launch합니다.
쉽게 말하면 Database에 접근할 객체를 생성해 DB와의 질의로 Job을 실행한다는 의미입니다.
JobLauncher는 JobRepository를 사용해서 새로운 JobExecution을 생성합니다.
JobLauncher에 대한 내용을 지난 포스팅을 참조해주세요.
기본적으로 Job과 Step이 실행될 때에는 동일한 하나의 JobRepository를 사용해서 같은 상태를 유지합니다.
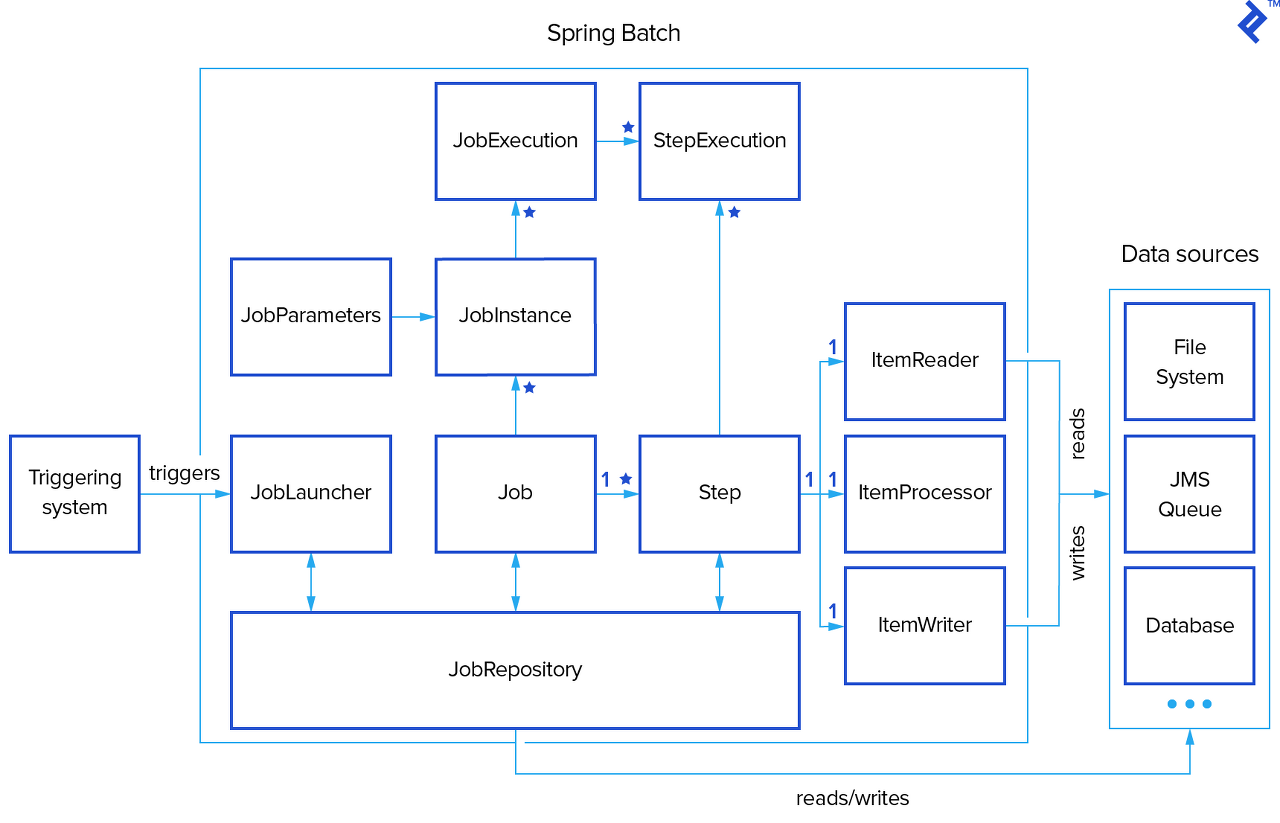
JobRepository는 Launcher, Job, 그리고 Step에 걸쳐 사용하고 있는 것을 확인할 수 있습니다.
이제 세부 내용을 확인해보도록 할게요.
JobRepository
스프링 배치는 Job 실행 시의 상태나 데이터 관리를 위해 해당 정보들을 JobRepository를 통해 저장하고 관리합니다.
실제로, Job이나 Step을 실행하는 것을 보면 계속해서 실행되는 Job이나 Step의 상태를 저장하고 있습니다.
예를들어 Job이 처리되는 데 걸리는 시간, 혹은 각 STEP에서 읽어들인 chunk의 수 등이 포함됩니다.
각 Step, Listener나 Item에서 데이터를 공유해야하는 복잡한 기능을 구현해야 할 때나 Job의 논리적인 실행을 조작해야 할 때,
Repository에 개발자가 필요한 데이터를 CRUD해서 효과적으로 활용할 수도 있죠.
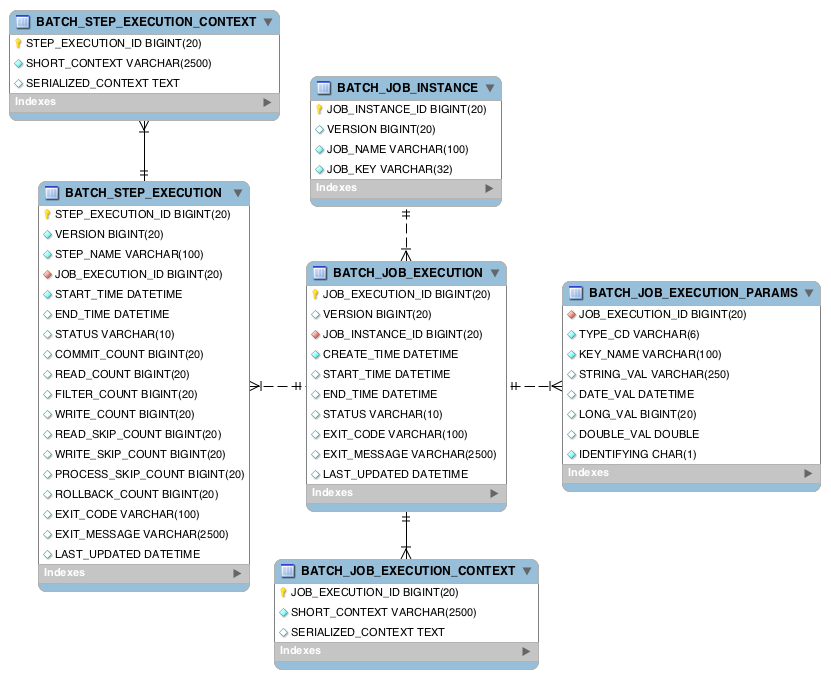
BATCH_JOB_INSTANCE
Job을 시작하면 가장 먼저, BATCH_JOB_INSTANCE에 Instance 정보가 등록됩니다.
JobInstance 레코드는 Job의 논리적 실행을 나타냅니다.
수행할 Job의 이름과 유저가 설정한 Job Parameter를 기반으로 생성되는 JOB_KEY를 저장하게 됩니다.

✔️ JOB_INSTANCE_ID : JobInstance의 식별값으로, PK에 해당. JobInstance에서 getId 메서드를 통해 얻을 수 있음
✔️ VERSION : Optimistic locking에 사용되는 Version
✔️ JOB_NAME : Instance의 구분을 위한 Job의 이름
✔️ JOB_KEY : Job Name과 Job Parameter의 해시값, Job instance를 고유하게 식별하는 값
* Optimistic locking: Version을 체크하며 Transaction에 적용되는 동시성 제어 방식 (낙관적 락)
예시 데이터
mysql> SELECT * FROM BATCH_JOB_INSTANCE;
+-----------------+---------+-----------+----------------------------------+
| JOB_INSTANCE_ID | VERSION | JOB_NAME | JOB_KEY |
+-----------------+---------+-----------+----------------------------------+
| 1 | 0 | importJob | b219dbf43c2905493d932edbab1f9117 |
+-----------------+---------+-----------+----------------------------------+
1 row in set (0.00 sec)
BATCH_JOB_EXECUTION_PARAMS
Job이 실행될 때마다 사용되는 JobParameter의 데이터들을 저장합니다.
실행된 Job에 전달된 파라미터가 레코드로 추가됩니다.
레코드는 0개 혹은 그 이상의 key/value 페어로 형성됩니다.

BATCH_JOB_INSTANCE의 JOB_KEY를 생성할 때 JobParameter와 같이 해시를 한다고 했는데요, 이때 기여한 파라미터 값에 해당하는 데이터는 IDENTIFYING 값을 true로 줍니다.
여기서 의심스러운 컬럼이 보입니다.
STRING_VAL, DATE_VAL, LONG_VAL, DOUBLE_VAL 값인데요.
해당 부분은 각각의 타입으로 분리하는 것보다 비정규화를 하는 것이 합리적이라고 판단이 되었나봐요.
각 타입으로 비정규화를 한 부분입니다.
✔️ JOB_EXECUTION_ID: BATCH_JOB_EXECUTION 테이블의 FK
매개 변수 항목이 속한 작업 실행 ID값을 참조합니다. 이 때, 이 값은 PK나 Unique가 아닙니다. 또한, 이 값과 매핑되는 Value도 중복될 수 있습니다.
✔️ TYPE_CD: JobParameter의 타입
이 값을 통해서 Value의 타입을 String, Date, Long, Double 값 중 하나로 체크하여 4개의 필드 중에 어디서 데이터를 가져올지 체크합니다. 그래서 당연히 절대 Null이면 안됩니다.
✔️ KEY_NAME: Parameter의 Key
✔️ STRING_VAL: String 타입을 갖는 Parameter의 Value
✔️ DATE_VAL: Date 타입을 갖는 Parameter의 Value
✔️ LONG_VAL: Long 타입을 갖는 Parameter의 Value
✔️ DOUBLE_VAL: Double 타입을 갖는 Parameter의 Value
✔️ IDENTIFYING: JobInstance를 생성 시 Hash에 값이 참여했는지의 여부
예시 데이터
mysql> SELECT * FROM BATCH_JOB_EXECUTION_PARAMS;
+------------------+---------+--------------------+--------------------------------------------------------------------------------------------------------------------+----------------------------+----------+------------+-------------+
| JOB_EXECUTION_ID | TYPE_CD | KEY_NAME | STRING_VAL | DATE_VAL | LONG_VAL | DOUBLE_VAL | IDENTIFYING |
+------------------+---------+--------------------+--------------------------------------------------------------------------------------------------------------------+----------------------------+----------+------------+-------------+
| 1 | STRING | customerUpdateFile | file:///Users/gyeongseon/Git/Gngsn-Spring-Lab/src/main/resources/data/customer_update.csv | 1970-01-01 00:00:00.000000 | 0 | 0 | Y |
+------------------+---------+--------------------+--------------------------------------------------------------------------------------------------------------------+----------------------------+----------+------------+-------------+
1 row in set (0.01 sec)
BATCH_JOB_EXECUTION
그 다음으로 BATCH_JOB_EXECUTION 테이블에 배치 잡의 실제 실행 기록을 저장합니다.
Job이 실행 될때마다 새로운 레코드가 테이블에 생성되며, Job이 진행되는 동안 주기적으로 업데이트됩니다.
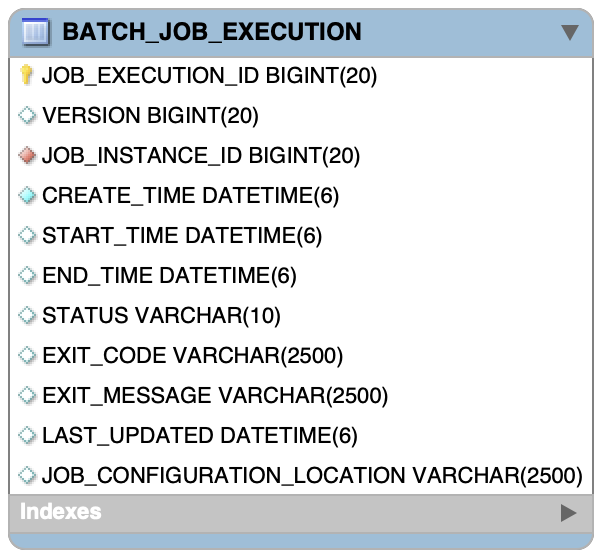
✔️ JOB_EXECUTION_ID : 해당 테이블(BATCH_JOB_EXECUTION)의 PK.
이 값은 JobExecution 객체의 getId 메서드를 통해 얻을 수 있습니다.
✔️ VERSION: Optimistic locking에 사용되는 Version
✔️ JOB_INSTANCE_ID : BATCH_JOB_INSTANCE의 FK
해당 데이터는 BATCH_JOB_INSTANCE 에 대해 여러개의 컬럼 값을 가질 수 있습니다. (1:N)
✔️ CREATE_TIME : 레코드 생성 시간
✔️ START_TIME : Job 실행 시작 시간
✔️ END_TIME :Job 실행 완료 시간
성공/실패에 관계없이 실행이 완료된 시간을 나타내는 타임스탬프입니다. 작업이 현재 실행되고 있지 않을 때 해당 값이 비어 있으면 오류가 발생해서 실패 전에 마지막 저장을 수행하지 못했음을 나타냅니다.
✔️ STATUS: Job 실행의 배치 상태
이 값은 Java BatchStatus Enum 값 중 하나로 들어갑니다.
✔️ EXIT_CODE : Job 실행의 종료 코드 (Character String)
command-line job의 경우 number로 변환가능합니다.
✔️ EXIT_MESSAGE : EXIT_CODE와 관련된 메시지나 stack trace
Job이 종료 내용을 서술하는데, 만약 오류가 발생했다면 오류 메세지가 추가됩니다.
✔️ LAST_UPDATED : 레코드의 마지막 갱신 시간
✔️ JOB_CONFIGURATION_LOCATION
예시 데이터
mysql> SELECT * FROM BATCH_JOB_EXECUTION;
+------------------+---------+-----------------+----------------------------+----------------------------+----------+---------+-----------+--------------+----------------------------+----------------------------+
| JOB_EXECUTION_ID | VERSION | JOB_INSTANCE_ID | CREATE_TIME | START_TIME | END_TIME | STATUS | EXIT_CODE | EXIT_MESSAGE | LAST_UPDATED | JOB_CONFIGURATION_LOCATION |
+------------------+---------+-----------------+----------------------------+----------------------------+----------+---------+-----------+--------------+----------------------------+----------------------------+
| 1 | 1 | 1 | 2022-06-19 14:03:46.055000 | 2022-06-19 14:03:46.155000 | NULL | STARTED | UNKNOWN | | 2022-06-19 14:03:46.170000 | NULL |
+------------------+---------+-----------------+----------------------------+----------------------------+----------+---------+-----------+--------------+----------------------------+----------------------------+
1 row in set (0.00 sec)
BATCH_JOB_EXECUTION_CONTEXT
위에서 살펴본 Batch Job의 ExecutionContext에 대한 정보를 저장하는 테이블입니다.
이 정보는 배치가 여러번 실행해야 하는 상황에서 유용하게 쓰입니다.

✔️ JOB_EXECUTION_ID : BATCH_JOB_EXECUTION의 FK
✔️ SHORT_CONTEXT : SERIALIZER_CONTEXT의 String Version
✔️ SERIALIZED_CONTEXT : 직렬화된 ExecutionContext
* 이 때 직렬화에는 XStream의 JSON 처리 기능이 사용됐지만 스프링 배치 4부터 Jackson2를 사용하도록 변경되었습니다.
예시 데이터
mysql> SELECT * FROM BATCH_JOB_EXECUTION_CONTEXT LIMIT 1;
+------------------+--------------------------------+--------------------+
| JOB_EXECUTION_ID | SHORT_CONTEXT | SERIALIZED_CONTEXT |
+------------------+--------------------------------+--------------------+
| 1 | {"@class":"java.util.HashMap"} | NULL |
+------------------+--------------------------------+--------------------+
1 row in set (0.02 sec)
BATCH_STEP_EXECUTION
StepExecution 객체의 시작과 완료 상태를 비롯한 모든 정보를 담습니다.
이 테이블은 BATCH_JOB_EXECUTION과 많은 면에서 비슷하며,
항상 하나의 JobExecution엔 적어도 하나의 StepExecution이 존재합니다.
또, 해당 테이블은 분석이 가능하도록 다양한 횟수값(읽기, 처리 등)을 추가로 저장합니다.

✔️ STEP_EXECUTION_ID : 해당 테이블(BATCH_STEP_EXECUTION)의 PK
이 값은 StepExecution 객체의 getId 메서드를 통해 얻을 수 있습니다.
✔️ VERSION : Optimistic locking에 사용되는 레코드의 버전
✔️ STEP_NAME : Step 이름
✔️ JOB_EXECUTION_ID : BATCH_JOB_EXECUTION의 FK
StepExecution이 속한 JobExecution을 가리킵니다.
✔️ START_TIME : Step 실행 시작 시간 (Timestamp)
✔️ END_TIME : Step 실행 완료 시간 (Timestamp)
성공/실패에 관계없이 실행이 완료된 시간을 나타내는 타임스탬프입니다. 작업이 현재 실행되고 있지 않을 때 해당 값이 비어 있으면 오류가 발생해서 실패 전에 마지막 저장을 수행하지 못했음을 나타냅니다.
✔️ STATUS : Step 배치 상태
이 값은 Java BatchStatus Enum 값 중 하나로 들어갑니다.
✔️ COMMIT_COUNT : Step 실행 동안 커밋된 트랜잭션 수
✔️ READ_COUNT : Step 실행 동안 읽은 Item 수
✔️ FILTER_COUNT : Step 실행 동안 ItemProcessor가 null을 반환해 필터링된 아이템 수
✔️ WRITE_COUNT : Step 실행 동안 기록된 아이템 수
✔️ READ_SKIP_COUNT : ItemReader 내에서 예외가 던져졌을 때 건너뛴 아이템 수
✔️ PROCESS_SKIP_COUNT : ItemProcessor 내에서 예외가 던져졌을 때 건너뛴 아이템 수
✔️ WRITE_SKIP_COUNT : ItemWriter 내에서 예외가 던져졌을 때 건너뛴 아이템 수
✔️ ROLLBACK_COUNT : Step에서 롤백된 트랜잭션 수
Retry나 그 때 Retry를 Skip한 것에 대한 롤백을 포함하여 매 롤백마다 포함됩니다.
✔️ EXIT_CODE : Step의 종료 코드 (Character String)
command-line job의 경우 number로 변환가능합니다.
✔️ EXIT_MESSAGE : Step 실행에서 반환된 메시지나 Stack Trace
Job이 종료 내용을 서술하는데, 만약 오류가 발생했다면 오류 메세지가 추가됩니다.
✔️ LAST_UPDATED : 레코드가 마지막으로 업데이트된 시간 (Timestamp)
예시 데이터
mysql> SELECT * FROM BATCH_STEP_EXECUTION;
+-------------------+---------+-----------------------------+------------------+----------------------------+----------+---------+--------------+------------+--------------+-------------+-----------------+------------------+--------------------+----------------+-----------+--------------+----------------------------+
| STEP_EXECUTION_ID | VERSION | STEP_NAME | JOB_EXECUTION_ID | START_TIME | END_TIME | STATUS | COMMIT_COUNT | READ_COUNT | FILTER_COUNT | WRITE_COUNT | READ_SKIP_COUNT | WRITE_SKIP_COUNT | PROCESS_SKIP_COUNT | ROLLBACK_COUNT | EXIT_CODE | EXIT_MESSAGE | LAST_UPDATED |
+-------------------+---------+-----------------------------+------------------+----------------------------+----------+---------+--------------+------------+--------------+-------------+-----------------+------------------+--------------------+----------------+-----------+--------------+----------------------------+
| 1 | 2 | IMPORT_CUSTOMER_UPDATE_STEP | 1 | 2022-06-19 14:03:46.311000 | NULL | STARTED | 1 | 100 | 1 | 99 | 0 | 0 | 0 | 0 | EXECUTING | | 2022-06-19 14:04:32.167000 |
+-------------------+---------+-----------------------------+------------------+----------------------------+----------+---------+--------------+------------+--------------+-------------+-----------------+------------------+--------------------+----------------+-----------+--------------+----------------------------+
1 row in set (0.02 sec)
BATCH_STEP_EXECUTION_CONTEXT
StepExecution 수준의 ExecutionContext를 저장합니다.
BATCH_JOB_EXECUTION_CONTEXT 과 구조는 동일하지만, Step 수준의 컴포넌트 저장이라는 점을 구분하셔야 합니다.

✔️ STEP_EXECUTION_ID : BATCH_JOB_EXECUTION의 FK
✔️ SHORT_CONTEXT : SERIALIZER_CONTEXT의 String Version
✔️ SERIALIZED_CONTEXT : 직렬화된 ExecutionContext
예시 데이터
mysql> SELECT * FROM BATCH_STEP_EXECUTION_CONTEXT;
+-------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+
| STEP_EXECUTION_ID | SHORT_CONTEXT | SERIALIZED_CONTEXT |
+-------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+
| 1 | {"@class":"java.util.HashMap","batch.taskletType":"org.springframework.batch.core.step.item.ChunkOrientedTasklet","customerUpdateItemReader.read.count":100,"batch.stepType":"org.springframework.batch.core.step.tasklet.TaskletStep"} | NULL |
+-------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+
1 row in set (0.01 sec)
BATCH_*_SEQ
자세한 내용은 Spring Batch, SEQ ID 제대로 이해하기를 확인해주세요.
위에서 보았던 BATCH_JOB_INSTANCE, BATCH_JOB_EXECUTION 및 BATCH_STEP_EXECUTION에는 각각 _ID로 끝나는 컬럼이 포함되어 있었고, 해당 필드는 각 테이블의 Primary Key 역할을 합니다.
이 ID 값은 도메인 개체 중 하나를 데이터베이스에 삽입한 후, 해당 키가 Java에서도 고유하게 식별될 수 있도록 실제 개체에 설정되어야 하기 때문에 필수적인데요. 최신 데이터베이스 드라이버(JDBC 3.0 이상)에서는 데이터베이스 생성 PK로 사용할 수 있도록 지원하지만, 기본적으로 아래와 같은 시퀀스를 사용하고 있습니다.
CREATE SEQUENCE BATCH_STEP_EXECUTION_SEQ;
CREATE SEQUENCE BATCH_JOB_EXECUTION_SEQ;
CREATE SEQUENCE BATCH_JOB_SEQ;
하지만 SEQUENCE를 지원하지 않는 DBMS가 존재하죠.
대표적으로 MySQL은 SEQUNCE를 지원하지 않아 SEQUNCE 테이블을 생성해서 사용하곤 합니다.
Spring Batch에서도 아래와 같이 테이블을 생성해 사용합니다.
CREATE TABLE BATCH_STEP_EXECUTION_SEQ (ID BIGINT NOT NULL) type=InnoDB;
INSERT INTO BATCH_STEP_EXECUTION_SEQ values(0);
CREATE TABLE BATCH_JOB_EXECUTION_SEQ (ID BIGINT NOT NULL) type=InnoDB;
INSERT INTO BATCH_JOB_EXECUTION_SEQ values(0);
CREATE TABLE BATCH_JOB_SEQ (ID BIGINT NOT NULL) type=InnoDB;
INSERT INTO BATCH_JOB_SEQ values(0);
Customizing
JobRepository는 개발 환경에 맞게 커스텀 할 수 있습니다.
보통은 ApplicationContext에 두 개 이상의 DataSource가 있는 경우에 커스터마이징하는데, 배치 테이블을 따로 관리할 수 있습니다. 아래와 같이 JobRepositoryFactoryBean을 통해 생성할 수 있는데, 등록을 위해 .afterPropertiesSet() 와 getObject() 메서드를 호출해야합니다.
@Configuration
@RequiredArgsConstructor
public class CustomBatchConfig extends DefaultBatchConfigurer {
private final DataSource dataSource;
private final PlatformTransactionManager transactionManager;
private JobRepository createJobRepository() throws Exception {
JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean();
factory.setDataSource(dataSource);
factory.setTransactionManager(transactionManager);
factory.setTablePrefix("GNGSN.BATCH_"); // jobExplorer도 변경해줘야함
factory.afterPropertiesSet();
return factory.getObject();
}
}
JobExplorer
스프링 배치는 내부적으로 여러 DAO를 사용해 JobRepository 테이블에 접근하고 있습니다.
뿐만 아니라, 이 기능을 프레임워크나 개발자가 사용할 수 있도록 API 를 제공하기도 합니다.
그중 JobExplorer 컴포넌트를 사용하면 데이터 저장소(메타데이터)에 접근을 할 수 있습니다.
JobRepository의 readOnly 버전이라고 생각하시면 되는데요. 수정, 삭제는 안되고 읽기만 가능합니다.
public interface JobExplorer {
List<JobInstance> getJobInstances(String jobName, int start, int count);
JobExecution getJobExecution(Long executionId);
StepExecution getStepExecution(Long jobExecutionId, Long stepExecutionId);
JobInstance getJobInstance(Long instanceId);
List<JobExecution> getJobExecutions(JobInstance jobInstance);
Set<JobExecution> findRunningJobExecutions(String jobName);
}
Method
✔️ findRunningJobExecutions(String jobName)
종료 시간이 존재하지 않는 모든 JobExecution을 반환합니다.
✔️ findJobInstancesByJobName(String jobName, int start, int count)
전달받은 이름을 가진 JobInstance 목록을 반환합니다.
✔️ getJobExecution(Long executionId)
전달받은 ID를 가진 JobExecution을 반환하며 존재하지 않으면 null을 반환합니다.
✔️ getJobExecutions(JobInstance jobInstance)
전달받은 JobInstance와 관련된 모든 JobExecution 목록을 반환합니다.
✔️ getJobInstance(Long instanceId)
전달받은 ID를 가진 JobInstance를 반환하며, 존재하지 않는다면 null을 반환합니다.
✔️ getJobInstances(String jobName, int start, int count)
전달받은 인덱스부터 지정한 개수만큼의 범위 내에 있는 JobInstnace를 반환합니다.
마지막 파라미터는 반환할 최대 인스턴스 개수를 의미합니다.
✔️ getJobInstanceCount(String jobName)
전달받은 잡 이름으로 생성된 JobInstance 개수를 반환합니다.
✔️ getJobNames()
JobRepository에 저장돼 있는 고유한 모든 잡 이름을 알파벳 순서대로 반환합니다.
✔️ getStepExecution(Long jobExecutionId, Long stepExecutionId)
전달받은 StepExecution의 ID와 부모 JobInstance의 ID를 갖는 StepExecution반환합니다.
추가로, JobRepository와 같이 쉽게 Factory Bean을 설정할 수 있습니다.
...
// This would reside in your BatchConfigurer implementation
@Override
public JobExplorer getJobExplorer() throws Exception {
JobExplorerFactoryBean factoryBean = new JobExplorerFactoryBean();
factoryBean.setDataSource(this.dataSource);
// factoryBean.setTablePrefix("SYSTEM.");
return factoryBean.getObject();
}
위의 코드에서 주석처리한 내용이 있는데요.
setTablePrefix입니다.
위의 Customizing에서 JobRepository의 설정 중 tabel prefix를 수정할 수 있는 설정을 지원했습니다.
이 때 JobRepository와 동일한 테이블을 사용하기 때문에 JobExplorer 또한 변경해주어야 합니다.
수정해주지 않으면 BadSqlGrammarException가 발생하겠죠.
JobOperator
하나의 Job에 대해 정지하거나, 재시작하거나, 혹은 요약하는 등의 모니터링을 할 때에는 batch operator에 의해 수행됩니다. Spring Batch에서는 이를 JobOperator인터페이스로 제공합니다.
JobRepository는 meta-data에 대한 CRUD를, JobExplorer는 meta-data에 대한 read-only 동작을 수행할 수 있다고 했는데요. JobOperator가 가진 대부분의 메서드를 보면 JobRepository와 JobExplorer를 사용합니다.
public interface JobOperator {
List<Long> getExecutions(long instanceId) throws NoSuchJobInstanceException;
List<Long> getJobInstances(String jobName, int start, int count)
throws NoSuchJobException;
Set<Long> getRunningExecutions(String jobName) throws NoSuchJobException;
String getParameters(long executionId) throws NoSuchJobExecutionException;
Long start(String jobName, String parameters)
throws NoSuchJobException, JobInstanceAlreadyExistsException;
Long restart(long executionId)
throws JobInstanceAlreadyCompleteException, NoSuchJobExecutionException,
NoSuchJobException, JobRestartException;
Long startNextInstance(String jobName)
throws NoSuchJobException, JobParametersNotFoundException, JobRestartException,
JobExecutionAlreadyRunningException, JobInstanceAlreadyCompleteException;
boolean stop(long executionId)
throws NoSuchJobExecutionException, JobExecutionNotRunningException;
String getSummary(long executionId) throws NoSuchJobExecutionException;
Map<Long, String> getStepExecutionSummaries(long executionId)
throws NoSuchJobExecutionException;
Set<String> getJobNames();
}
메소드들을 조금만 훑어봐도 지금껏 나온 Job관련 객체(JobLauncher, JobRepository, JobExplorer, JobRegistry) 들이 보입니다. JobOperator나 그 구현체인 SimpleJobOperator는 많은 객체의 의존성을 가집니다.
와 이게 끝나네요.
다루고 싶은 주제는 많은데 마음만 앞서고 있어요 ^~^,,
얼른 다음 포스팅으로 만나뵙겠습니다.
이상으로 Spring Batch에서의 데이터 다루는 방법을 다뤘습니다.
오타나 잘못된 내용을 댓글로 남겨주세요!
감사합니다 ☺️
'Spring' 카테고리의 다른 글
| JdbcBatchItemWriter VS MyBatisBatchItemWriter (0) | 2022.06.26 |
|---|---|
| Spring Batch, Error Log (1) | 2022.06.23 |
| Spring Batch, 제대로 이해하기 (2) - 동작원리 (4) | 2022.06.19 |
| Spring Batch, 제대로 이해하기 (1) - 개념이해 (0) | 2022.06.18 |
| XML Unmarshalling, Xstream 어렵지 않게 사용하기 (0) | 2022.06.12 |

Backend Software Engineer
𝐒𝐮𝐧 · 𝙂𝙮𝙚𝙤𝙣𝙜𝙨𝙪𝙣 𝙋𝙖𝙧𝙠