
2022. 7. 1. 23:13ㆍSpring
Spring Batch에서 데이터 처리하는 방법을 알아보고 활용하는 것이 본 포스팅의 목표입니다.
이번 포스팅에서는 지난 포스팅에 이어 데이터 저장과 관련된 주제입니다.
하지만, 다루는 내용이 아예 다른데요.
지난 번에는 JobRepository를 다루며 DB와 밀접한 Persistent 데이터를 다루었다면,
이번에는 각 Job이나 Step마다 데이터 공유하는 방법에 대해 다룹니다.
각 Step 마다 데이터를 공유하는 경우가 적지 않기 때문에 한 번쯤 알아두면 좋을 듯 합니다.
------------------- 📌 Spring Batch Series 📌 -------------------
Spring Batch, 제대로 이해하기 (1) - 개념 이해
Spring Batch, 제대로 이해하기 (2) - 동작 원리
Spring Batch, 제대로 이해하기 (3) - 데이터 처리
✏️ Spring Batch, 제대로 이해하기 (4) - 데이터 처리 활용
Spring Batch, 제대로 이해하기 (5)
- MultiResourceItemReader
----------------------------------------------------------------
데이터 처리 활용에 대한 직접적인 활용에 앞서,
선수 지식으로 Scope 개념을 알아봅시다.
꽤 중요한 개념이니 넘기지 확실히 가져갑시다 〰️
@JobScope, @StepScope
SpringFramework에서 기본 Scope는 Singleton입니다.
클래스의 인스턴스를 생성할 때 단 하나만을 생성한 다음 곳곳에서 쓰겠다는 뜻입니다.
인스턴스를 생성할 때마다 새로운 빈을 생성한다면 메모리 효율이 좋지 못하겠죠.
@JobScope 와 @StepScope의 의미는 이 빈 객체를 애플리케이션 실행 시점이 아닌
해당 어노테이션이 붙은 메소드의 실행까지 지연시킨다는 의미입니다.
이것을 Late Binding이라고 부릅니다.
그렇다면 왜 지연을 시켜야 할까요?
✔️ 할당 지연
애플리케이션의 실행 시점에는 존재하지 않고 비즈니스 로직 상 생성되는 객체를 사용해야할 때 유용합니다.
A라는 객체가 B라는 객체를 속성으로 갖고 있고 실제 B 구현체는 비즈니스 상에서 생성된다면,
A라는 빈을 생성할 때 에러가 납니다.
이해가 안된다면 아래를 한 번 쭉 읽어본 후, 해당 어노테이션 제거 후 실행시켜 에러를 한 번쯤 직면해보세요!
✔️ 안전한 병렬 처리
병렬적으로 처리되는 Step의 경우 동시성 문제가 발생할 수 있는데요.
@StepScope은 각 Step에서 별도의 Tasklet을 생성하고 관리하기 때문에 서로의 상태를 침범할 일이 없습니다.
결론은, 만약 해당 객체가 Job이 실행되는 시점에 생성되게끔한다면 @JobScope를 붙여주면 되고
특정 Step 시점에 생성되게 만들고 싶다면 @StepScope를 붙이면 됩니다.
ExecutionContext
배치 처리에서는 각 Job마다, 혹은 각 Step마다 공유되어야 하는 상태나 데이터가 있습니다.
이 데이터들은 안전하게 데이터베이스와 같은 지속가능한 형태로 유지되어야겠죠.
ExecutionContext는 Job을 실행하면서 필요한 데이터를 지속가능한 상태로(데이터베이스 등) 저장할 수 있도록 Spring Batch Framework에서 지원하는 key/value 데이터를 담는 공간입니다.
재미있게도 Spring에서는 " ExecutionContext를 각각의 실행 동안 유지되어야하는 사용자 데이터의 property bag 속성 가방"라고 표현합니다. Spring Batch는 범위에 따라 두개의 ExecutionContext를 지원합니다.
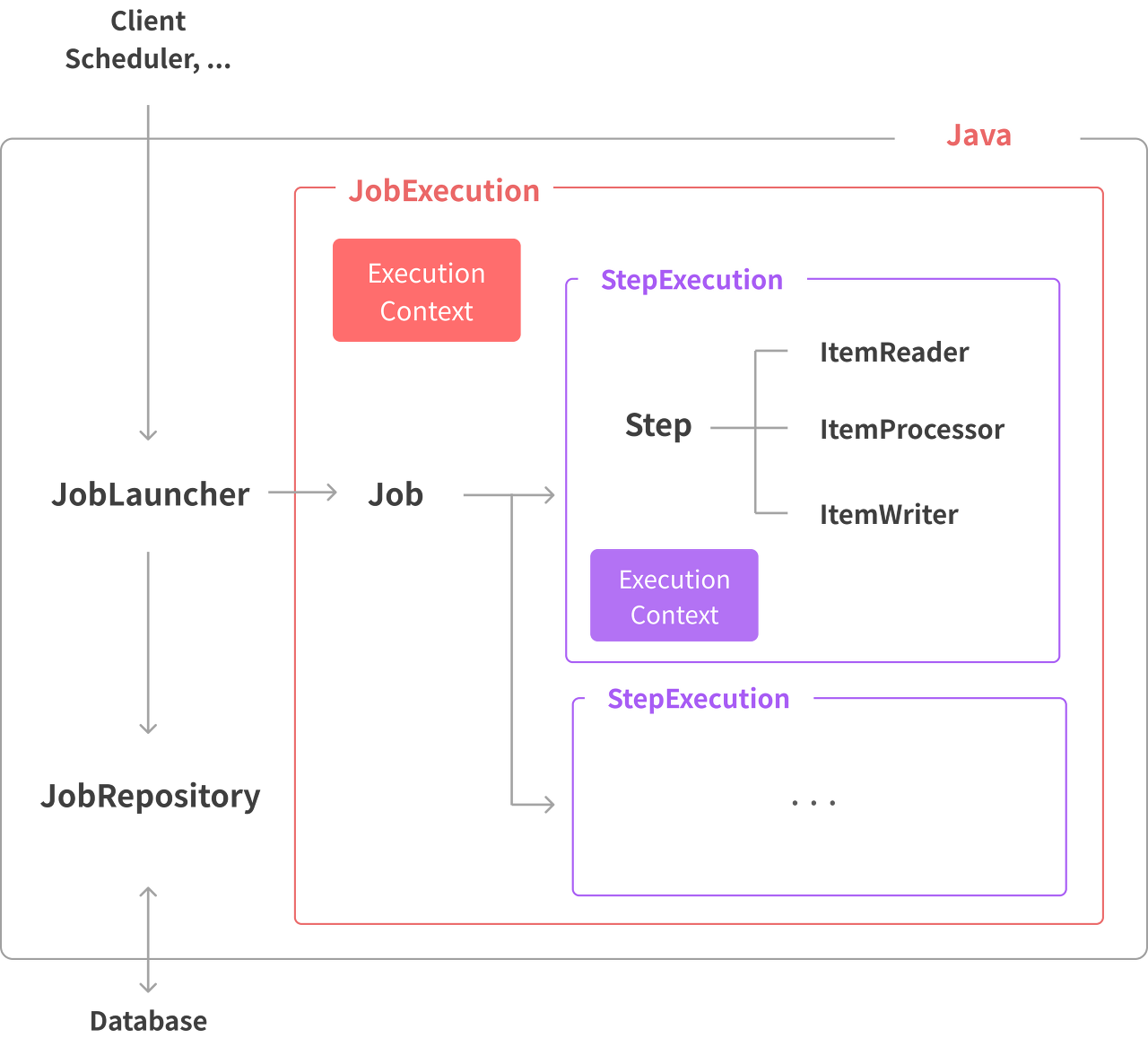
Job ExecutionContext
JobExecution 내에서 사용되며, 각 Step에서 접근하면서 공유할 수 있습니다.
JobExecution 클래스의 executionContext 필드를 확인할 수 있는데, 아래와 같이 접근하고는 합니다.
ExecutionContext jobExecutionContext = jobExecution.getExecutionContext();
jobExecutionContext.put("key", "value");
지난 포스팅에서 다룬 JobRepository를 확인해보면,
BATCH_JOB_EXECUTION_CONTEXT 에 저장되는 데이터 예시입니다.
mysql> select * from BATCH_JOB_EXECUTION_CONTEXT;
+-----------------+-----------------------+---------------------+
| STEP_EXEC_ID | SHORT_CONTEXT | SERIALIZED_CONTEXT |
+-----------------+-----------------------+---------------------+
| 1 | {key=value} | null |
+-----------------+-----------------------+---------------------+
1 row in set (0.00 sec)
조금 더 자세하게 Tasklet에서 사용하는 예시를 볼까요?
@Bean
public Step testStep() {
return stepBuilderFactory
.get("testStep")
.tasklet(new Tasklet() {
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
// JobExecution Level의 ExecutionContext를 다루는 방식
ExecutionContext jobExecutionContext = chunkContext.getStepContext().getStepExecution().getJobExecution().getExecutionContext();
// 데이터 추가
jobExecutionContext.put("resourceMetaMap", resourceMetaMap);
// 데이터 조회
String targetMonth = (String)jobExecutionContext.get("targetMonth");
// ...
}
}).build();
}
}
Job과 Step, Chunk 단위의 ExecutionContext를 다루는 것을 이해한다면 금방 활용하실 수 있을 거예요.
Step ExecutionContext
Step의 ExecutionContext은 JobExecutionContext와 사용하는 방식은 동일합니다.
다만, 적용하는 범위만 다릅니다.
A Step에서만 사용할 데이터를 B Step에서 사용하고 싶지 않을 때 유용하겠죠.
만약 FlatFile을 불러오는 Reader를 예시로 든다면,
읽어오는 commit point를 아래와 같이 지정할 수 있습니다.
executionContext.putLong(getKey(LINES_READ_COUNT), reader.getPosition());
위의 코드는 어떻게 반영될까요?
JobRepository에 있는 BATCH_STEP_EXECUTION_CONTEXT에 아래와 같이 저장됩니다.
mysql> SELECT * FROM BATCH_STEP_EXECUTION_CONTEXT;
+-----------------+-----------------------+---------------------+
| STEP_EXEC_ID | SHORT_CONTEXT | SERIALIZED_CONTEXT |
+-----------------+-----------------------+---------------------+
| 1 | {piece.count=40321} | null |
+-----------------+-----------------------+---------------------+
1 row in set (0.00 sec)
생성자 주입
파라미터 뿐만 아니라 Scope으로 빈 주입을 늦춘다면 사실상 당연하게 생성자 주입이 가능합니다.
@Component
@StepScope
public class TestTasklet implements Tasklet {
@Value("#{jobParameters[targetMonth]}")
private String targetMonth;
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
// some logic ..
return RepeatStatus.FINISHED;
}
}
이는 아래에서 다룰 JobParameters도 동일합니다.
이 내용 - Scope & Bean 생성 - 을 알고 있다면 데이터 처리가 매우 쉬워지니 정확히 알고 가면 좋을 듯합니다.
Serialize
ExecutionContext에 데이터가 저장될 때에는 JSON형식으로 변환하여 json문자열을 DB에 보관합니다.
예전에는 Xstream 프레임워크를 이용했는데, 3.0.7 버전 부터 Jackson2을 사용하기 시작했습니다.
Spring Batch 4에서 Xstream은 deprecate되고 Jackson2를 사용하기 시작했습니다.
Java 객체를 JSON 형태로 Serialize해서 보관하고 Deserialize해서 가져오는 형식이죠.
기본적으로 사용하는 Serializer는 ExecutionContextSerializer를 구현한 Jackson2ExecutionContextStringSerializer입니다.
public class Jackson2ExecutionContextStringSerializer
extends java.lang.Object
implements ExecutionContextSerializer
여기서 주의할 점은, JSON 형식으로 Serialize할 수 없는 객체는 기본적인 설정으로는 저장할 수 없다는 것입니다.
만약 추가적인 기능이 필요하다면 ExecutionContextSerializer를 구현하여 사용할 수 있습니다.
이는 JobRepository를 생성할 때 (JobRepositoryFactoryBean) 설정할 수 있는데요.
참고차 StackOverflow를 확인하셔도 도움이 될것 같네요.
저도 이 부분으로 고생을 좀 해서 ,,, ㅎㅎ
추가로, Jackson2ExecutionContextStringSerializer의 TrustedTypeIdResolver라는 InnerClass을 참고하세요.
private static final Set<String> TRUSTED_CLASS_NAMES = Collections.unmodifiableSet(new HashSet(Arrays.asList(
"javax.xml.namespace.QName",
"java.util.UUID",
"java.util.ArrayList",
"java.util.Arrays$ArrayList",
"java.util.LinkedList",
"java.util.Collections$EmptyList",
"java.util.Collections$EmptyMap",
"java.util.Collections$EmptySet",
"java.util.Collections$UnmodifiableRandomAccessList",
"java.util.Collections$UnmodifiableList",
"java.util.Collections$UnmodifiableMap",
...
)));
Capacity
ExecutionContext는 결국 데이터베이스에 저장되는데요.
이 때, 주의 사항은 데이터의 사이즈입니다.
아래서 다루는 JobRepository의 BATCH_JOB_EXECUTION_CONTEXT나 BATCH_STEP_EXECUTION_CONTEXT에서 허용하는 데이터 사이즈도 확인해볼 필요가 있겠죠.
mysql> describe BATCH_JOB_EXECUTION_CONTEXT;
+--------------------+---------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------------+---------------+------+-----+---------+-------+
| JOB_EXECUTION_ID | bigint(20) | NO | PRI | NULL | |
| SHORT_CONTEXT | varchar(2500) | NO | | NULL | |
| SERIALIZED_CONTEXT | text | YES | | NULL | |
+--------------------+---------------+------+-----+---------+-------+
3 rows in set (0.01 sec)
위와 같이 2500으로 되어 있기 때문에 저장되는 데이터 사이즈를 반드시 확인해보시길 바랍니다.
JobParamters
JobParamters는 배치 Job 실행 전, 외부에서 데이터를 받아 프로젝트를 실행할 때 데이터를 사용합니다.
말 그대로 Parameter의 역할을 합니다.
단순하게 생각해보면 Batch를 시작하면서 Parameter로 넣는 데이터는 JobParamters를 사용하면되고,
Job 수행 중 필요한 데이터는 ExecutionContext를 사용할 수 있습니다.
사용 예시는 아래와 같습니다.
@Bean
@StepScope
public FlatFileItemReader<String> flatFileItemReader(
@Value("#{jobParameters[resource]}") Resource resource) {
new FlatFileItemReaderBuilder<String>()
.name("flatFileItemReader")
.resource(resource)
.build();
}
Args 는 Job을 실행할 때 실행 인자로 "resource=file://path/to/resource" 를 넘겨줄 수 있습니다.
혹은 생성자 주입을 통해 받을 수 있습니다.
@Configuration
@RequiredArgsConstructor
public class CsvToDbJobConfig {
private final CsvReader csvReader;
@Bean
public Step CSV_STEP() throws Exception {
log.info("************ {} START ************", CSV_STEP);
return stepBuilderFactory
.get(CSV_STEP)
.<String, String>chunk(CHUNK_SIZE)
.reader(csvReader)
.writer(itemWriter)
.build();
}
// ...
}
@Component
@StepScope
@RequiredArgsConstructor
public class CsvReader implements ItemReader<String> {
@Value("#{jobParameters[resource]}")
private final Resource resource;
// ...
}
여기서도 주목할만한 @StepScope Annotation이 보입니다.
JobParameter의 @Value로 값을 받기 위해서는 @JobScope, @StepScope 가 반드시 필요합니다.
ExecutionContext처럼 말이죠.
여전히 다루고 싶은 주제는 많은데 마음만 앞서고 있네요.
얼른 다음 포스팅으로 만나뵙겠습니다.
이상으로 Spring Batch에서의 데이터 활용을 다뤘습니다.
오타나 잘못된 내용은 댓글 부탁드립니다.
감사합니다 ☺️
'Spring' 카테고리의 다른 글
| Spring WebClient, 제대로 사용하기 - retrieve (0) | 2022.08.24 |
|---|---|
| Spring Batch, SEQ ID 제대로 이해하기 (0) | 2022.08.21 |
| JdbcBatchItemWriter VS MyBatisBatchItemWriter (0) | 2022.06.26 |
| Spring Batch, Error Log (1) | 2022.06.23 |
| Spring Batch, 제대로 이해하기 (3) - Meta Data (1) | 2022.06.22 |

Backend Software Engineer
𝐒𝐮𝐧 · 𝙂𝙮𝙚𝙤𝙣𝙜𝙨𝙪𝙣 𝙋𝙖𝙧𝙠