
2020. 11. 29. 21:55ㆍBACKEND/Database
안녕하세요 〰️
오늘은 SQLD 공부를 하면서 처음 접했던,
Window Function에 대해 정리 겸 포스팅 하겠습니다.
***************** INDEX *****************
1부
🚀 Window Function ❓
🎯 Window Funciton 구조
💼 Window Funciton 사용
********************************************
🚀 Window Function ❓
윈도우 함수는 무엇을 의미할까요 ?
윈도우 함수는 행과 행 간의 관계를 정의하기 위해 제공되는 함수입니다.
즉, 행들을 함수를 사용해서 이것저것 도출해낼 수 있는 것이죠.
예를 들어 순위, 합계, 평균, 행 위치 등을 조작할 수 있습니다.
그런데, 이런 부분은 Aggregate function과 비슷한 것 같지 않나요❓
Aggregate 함수는 single result로 한 행의 결과값을 도출합니다.
이제부터 어떻게 사용하는지 알아보도록 하겠습니다.
🎯 Window Function 구조
자 이제 Window Function를 어떤 식으로 사용하는지 알아볼까요 ?

위의 쿼리문이 조금 낯설죠...?
하나씩 보겠습니다.
✔️ Window Function ( )
가장 먼저, WINDOW_FUNCTION 구문을 볼 건데요.
WINDOW_FUNCTION는 순위, 집계, 행 순서, 비율 등과 관련된 함수들입니다.
이 WINDOW_FUNCTION는 용도에 따라,
순위 함수,
집계 함수,
행 순서 관련 함수,
비율 관련 함수
로 나눌 수 있습니다.
이제부터 하나씩 알아볼게요 !
순위 함수
순위 함수는 특정 항목과 파티션에 대해 순위를 계산할 수 있습니다.
SQLD 시험에도 자주 출현하는 함수죠 ㅎㅎ
| 순위 함수 | 설명 |
| RANK | 동일한 순위는 동일한 값을 부여 |
| DENSE_RANK | 동일한 순위는 동일한 값을 부여하되, 동일한 순위를 하나의 건수로 계산 |
| ROW_NUMBER | 동일한 순위에 대해서 고유의 순위를 부여 |
위의 세 함수는 특정 항목 및 파티션에 대해 순위를 계산한다는 것은 동일하지만, 순위를 매기는 방법이 조금 다릅니다.
아래 그림을 같이 볼게요!

SELECT salary ,
RANK() OVER(ORDER BY salary DESC) RANK,
DENSE_RANK() OVER(ORDER BY salary DESC) DENSE_RANK,
ROW_NUMBER() OVER(ORDER BY salary DESC) ROW_NUMBER,
FROM employee;
차이가 보이시나요❓
RANK()는 같은 값에 대해 동일한 순위를 매깁니다.
그리곤, 그 수를 감안하여 다음 순위를 매깁니다.
그래서 RANK를 보면 3,6과 7이 없는 것을 확인할 수 있죠.
DENSE_RANK() 는 RANK() 와 동일하지만,
이름에서 느껴지듯이 촘촘하게 순위를 매깁니다.
그래서 동일한 순위가 같은 순위로 매겨지는 것을 감안하지 않고 연속되게 됩니다.
ROW_NUMBER()은 값에 신경쓰지 않고 순위를 매깁니다.
집계 함수
| 집계 함수 | 설명 |
| SUM | 파티션 별로 합계 계산 |
| AVG | 파티션 별로 평균 계산 |
| COUNT | 파티션 별로 행 수를 계산 |
| MAX / MIN | 파티션 별로 최댓값 / 최솟값을 계산 |
전에 GROUP BY와 같이 사용하던 집계함수와 똑같은 기능을 합니다.
근데, 이 둘은 어떤 차이가 있을까요❓
GROUP BY와 사용하던 집계함수는 행에 대한 가치를 도출해내고 한 행으로 출력하지만,
window function에서 사용하는 집계함수는 행 수의 변화를 주지 않고 출력합니다.
행 순서 관련 함수
| 행 순서 | 설명 |
| FIRST_VALUE | 파티션에서 가장 처음으로 나오는 값을 구합니다. MIN 함수와 같은 결과를 구할 수 있습니다. |
| LAST_VALUE | 파티션에서 가장 마지막으로 나오는 값을 구합니다. MAX 함수와 같은 결과를 구할 수 있습니다. |
| LAG | 이전 행을 가지고 온다. |
| LEAD | 특정 위치의 행을 가지고 온다. 기본값은 1입니다. |
비율 관련 함수
| 비율 함수 | 설명 |
| CUME_DIST | 누적 백분율을 조회. 누적 분포상에 위치를 0~1 사이의 값을 가진다. |
| PERCENT_RANK | 제일 먼저 나온 것을 0으로 제일 늦게 나온 것을 1로 하여 순서별 백분율을 조회 |
| NTILE | argument값으로 데이터를 N등분 |
✔️ PARTITION BY column
파티션을 분리하는 역할을 합니다.
전체 그룹을 기준을 통해 소그룹으로 나누는데요,
어떤 칼럼을 기준으로 파티션을 나눌 것인지를 뒤에 작성하면 됩니다.
✔️ ORDER BY
어떤 것을 기준으로 정렬을 할지 설정합니다.
| 구조 | 설명 |
| ROWS | 부분 집합인 윈도우 크기를 물리적 단위로 행의 집합을 지정 |
| RANGE | 논리적인 주소에 의해 행 집합을 지정 |
| BETWEEN ~ AND | 윈도우의 시작과 끝의 위치를 지정 |
| UNBOUNDED PRECENDING | 윈도우의 시작 위치가 첫 번째 행임을 의미 |
| UNBOUNDED FOLLOWING | 윈도우의 마지막 위치가 마지막 행임을 의미 |
| CURRENT ROW | 윈도우 시작 위치가 현재 행임을 의미 |
💼 Window Function 사용
자 이번에는 마지막으로 간단하게 어떻게 사용되는지 예시를 볼게요.
SELECT
SUM(salary) OVER (ORDER BY salary
ROWS BETWEEN UNBOUNDED PRECENDING
AND CURRENT ROW) total
FROM employee;
위의 예시는 salary의 값을 기준으로 처음 행(UNBOUNDED PRECENDING)부터 현재 행(CURRENT ROW) 까지의 행의 집합(ROWS) 내 salary 값의 합(SUM)을 출력하는 예제입니다.
SELECT
LEAD(salary, 2) OVER (ORDER BY salary DESC) AS pre_salary
FROM employee;
두 번째 예시도 같이 한 번 볼까요 ㅎㅎ
LEAD는 이전 값을 가지고 오는데요.
salary값의 2번 째 전 행을 가져옵니다.
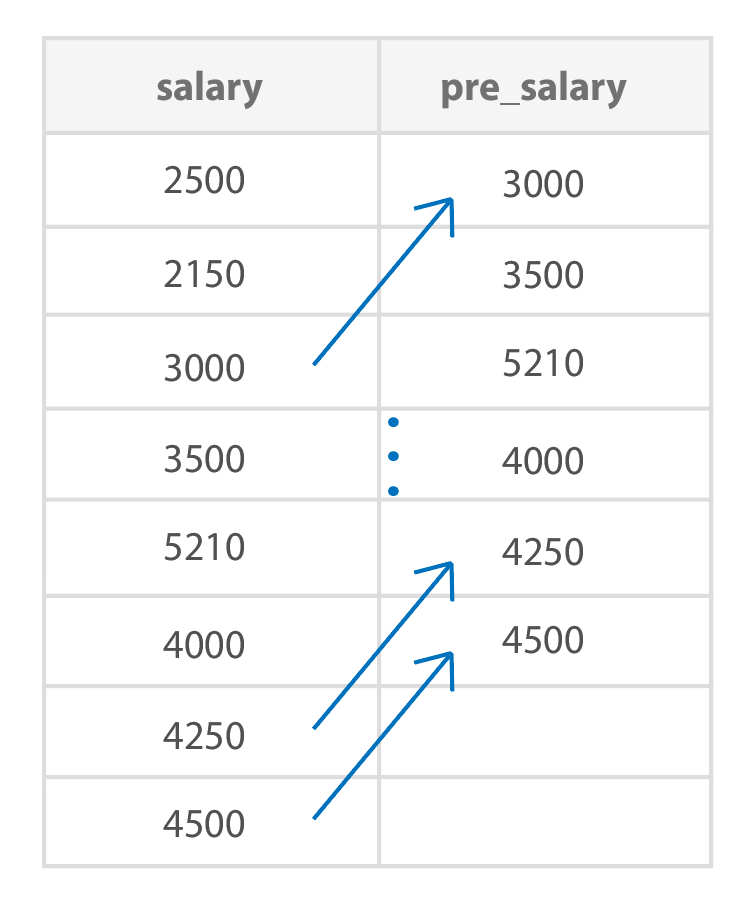
위와 같은 결과가 나옵니다
그럼 여기까지 window 함수에 대해 알아보았습니다 🙌🏻
'BACKEND > Database' 카테고리의 다른 글
| Bulk Insert, 성능 테스트 (6) | 2022.03.05 |
|---|---|
| Database Index, 제대로 알아보기 (4) | 2021.07.30 |
| ERD, 어렵지 않게 만들기 (12) | 2020.06.26 |
| SQL SELECT, 제대로 사용하기 (0) | 2020.06.23 |
| SQL SELECT, 제대로 사용하기 - where 조건절 (0) | 2020.06.20 |

Backend Software Engineer
𝐒𝐮𝐧 · 𝙂𝙮𝙚𝙤𝙣𝙜𝙨𝙪𝙣 𝙋𝙖𝙧𝙠