
2020. 6. 15. 14:35ㆍBACKEND/Database
안녕하세요 ❗️ 오늘은 데이터 베이스 정규화를 다뤄볼 예정입니다.
정규화가 어떤 것인지, 왜 사용하는지 그리고 어떻게 하는지 같이 알아가 보도록 하겠습니다 〰️
**************** INDEX *****************
🌈 정규화❓
👻 이상현상
🤖 1차 ~ 3차 정규화
🤡 BCNF
********************************************
첫 번째, 정규화❓
정규화에 대해 들어보지 못한 분들도 계실 것 같아요.
정규화란 무엇일까요?
정규화는 RDB 설계를 논리적이고 직관적으로 만드는 과정입니다.
왜 이러한 정규화를 하게 되는 것일까요❓
일단, 불필요한 데이터 제거하기 때문에 데이터의 중복 최소화시켜 줍니다.
데이터를 다루면서 생기는 이상현상도 방지해주죠.
또, 개발 중 데이터의 변화가 생겨도 설계를 재구성할 필요성 감소합니다.
두 번째, 이상현상 👻
데이터를 다루면서 생기는 이상현상이란 무엇을 의미할까요?
데이터베이스를 생성해서 사용하다가, 생각하지 못한 이상한 현상들이 몇몇 발생하는데요.
다음과 같은 세 부분의 이상현상이 있습니다.
✔️ 삽입 이상 - Insert
" 새 데이터를 삽입하기 위해 불필요한 데이터도 함께 삽입해야 하는 문제 "

만약, 위와 같은 데이터베이스가 있을 때 '김다라'라는 사람이 휴학을 했다고 가정해봅시다.
그럼 수강과목과 학년에는 어떤 값을 넣어야할까요❓
아니면 학생 데이터 자체를 없애야할까요❓
이렇게, 대체할 수 없는 데이터에 대해 임의의 무효한 값을 넣어줄 때가 생길 수 있습니다.
이럴 때를 바로 삽입이상이라고 합니다.
✔️ 갱신 이상 - Update
" 중복 튜플 중 일부만 변경하여 데이터가 불일치하게 되는 모순의 문제 "
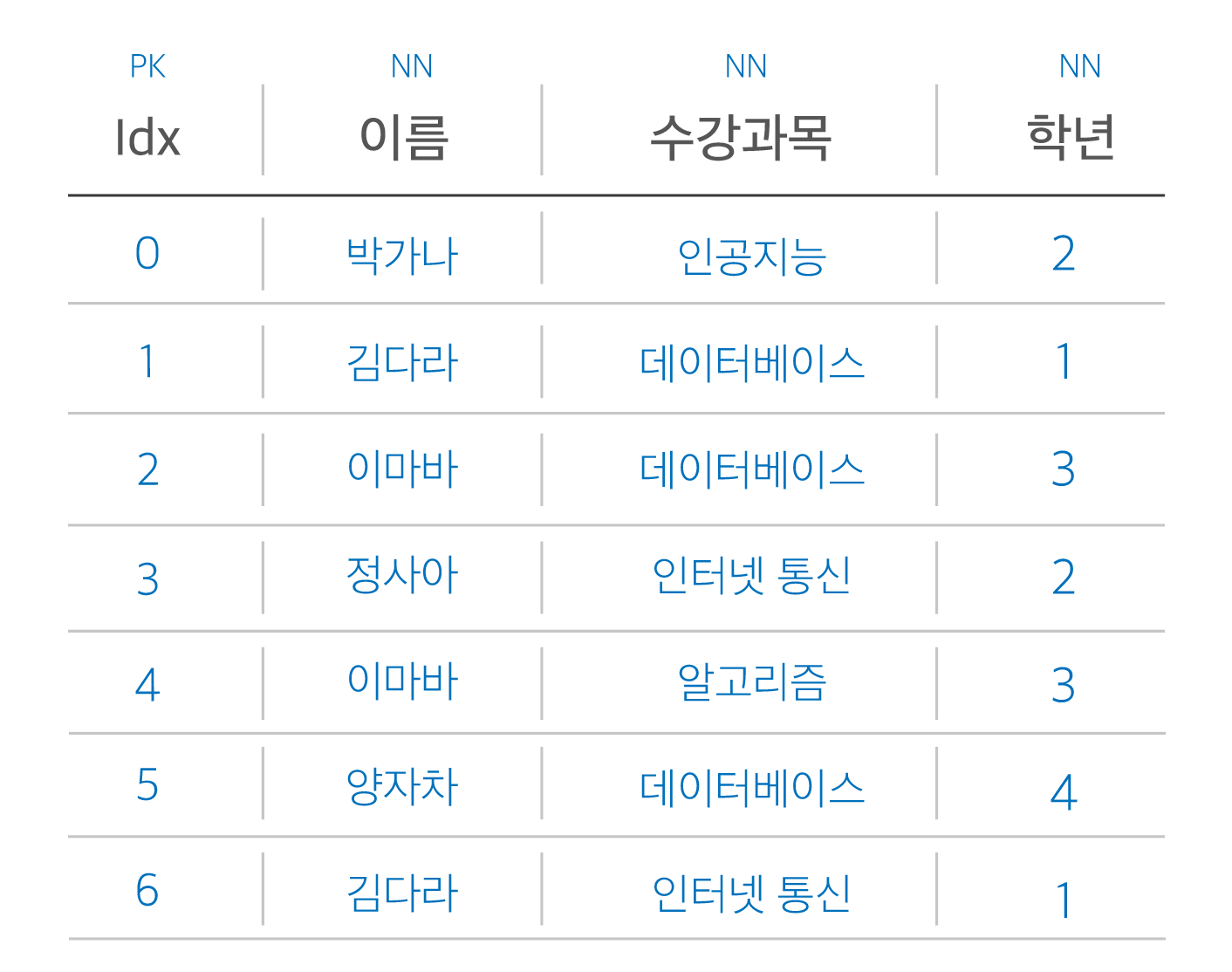
이번에는 갱신이상을 볼까요❓
만약, 김다라가 2학년이 되어서 데이터를 수정해야한다고 가정해봅시다.
그런 Idx가 1번인 데이터와 6번인 데이터를 모두 찾아서 변경해야겠죠❓
이 과정에서 한 행의 데이터라도 변경되지 않으면 데이터의 모순이 되게 됩니다.
간단한 예시라서 별문제 없어보이지만, 복잡한 관계에 있거나 한테이블에서 가지는 데이터의 양이 많다면 어떨지 생각해보세요 !
✔️ 삭제 이상 - Deletion
" 튜플을 삭제하면 꼭 필요한 데이터까지 함께 삭제되는 데이터 손실의 문제 "

만약, 김다라가 데이터베이스 과목을 드랍하고 싶다면, 김다라에 대한 정보가 아예 사라지겠죠.
사라져야할 데이터인 '데이터베이스'뿐만 아니라 꼭 필요한 '김다라'에 대한 정보의 데이터가 손실됩니다.
지금까지 삽입이상, 갱신이상, 삭제이상에 대해 알아보았는데요.
이러한 이상문제를 해결하려고 내놓은 방안이 바로 정규화였습니다.
그럼 이제부터는 정규화를 어떻게 진행하는지 같이 한 번 살펴보겠습니다.
세 번째, 정규화 🤖
✔️ 1차 정규화
데이터는 항상 원자값(분해될 수 없는 값)을 갖음 로우마다 컬럼의 값이 1개씩만 있어야 함

위와 같이 항상 원자값을 갖게끔 데이터를 넣어주어야합니다.
✔️ 2차 정규화
1차 정규화 만족하고 부분 함수적 종속을 제거한다. = 완전 함수적 종속을 만족시킨다
부분 함수적 종속 제거: 기본키 중에 특정 컬럼에만 종속된 컬럼(부분적 종속)이 없어야 한다.
낯선 단어가 맞고, 같이 보면서 어떤 것인지 알아가도록 합시다.

위와 같은 테이블이 있다고 가정해보고,
함수적 종속을 먼저 찾아내어 제거 해보도록 할게요.
📌 함수적 종속

X의 값을 통해 Y의 값을 바로 식별할 수 있을 때, 혹은 X값에 따라 Y값이 달라질 때 함수적 종속이라고 합니다.
그럼 완전 함수적 종속과 부분 함수적 종속은 무엇일까요?
완전함수적 종속은 모든 column이 하나의 키 값에 의한 종속자인 것을 의미합니다.
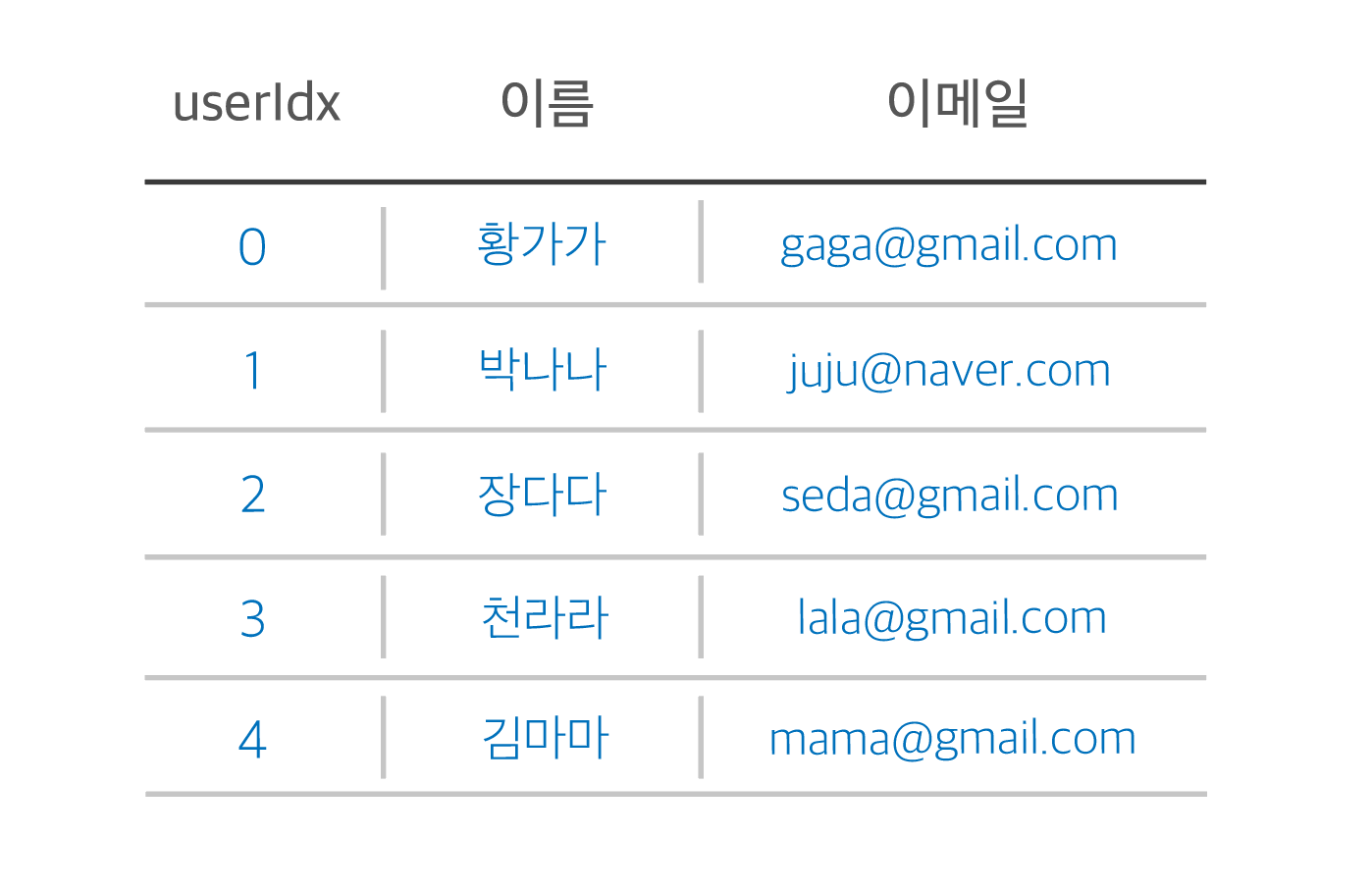
예를 들어 위의 표를 보게되면, userIdx 라는 키 값(X)을 참조하면 이름과 이메일을 확인할 수 있죠?

위의 데이터를 보면, '전공'이라는 데이터들은 'userIdx'로 참조할 수 있도 있겠지만 '전공코드'로 참조할 수도 있습니다.
이럴 때 '전공'은 '전공코드'에 부분함수적이다라는 표현을 사용합니다.
반면, '이메일'이라는 데이터는 'userIdx'에만 종속적이죠.
'userIdx'와 '전공코드'는 전부 '학생 정보'라는 데이터에 완전함수적 종속이며,
'userIdx'와 '전공코드'는 각각 함수적 종속의 결정자의 역할을 하는 부분 함수적 종속관계에 있습니다.
자, 그럼 다시 2차 정규화로 돌아와서 부분함수적 종속을 제거 해보겠습니다.

위와 같이 테이블을 따로 빼주면 해결되겠죠.
✔️ 3차 정규화
2차 정규화 만족하고 이행적 함수 종속을 제거한다.
기본키 외의 Column이 다른 Column을 결정할 수 없음

위의 표를 보면 '학번'을 함조하면 '학과'를 확인할 수 있고,
'학과'를 통해 '학과 전화번호'를 확인할 수 있습니다.
이행적 함수 종속은 조금 더 이해가 쉽습니다.
이행적으로 데이터를 알아낼 수 있을 때, 이행적 함수 종속이라고 합니다.

위의 그림과 같이 말이죠.
이행적 함수 종속을 없애면 어떤 모습이 될까요?

위와 같은 모습을 볼 수 있습니다.
이렇게, 1차 정규화부터 3차 정규화를 살펴보았습니다.
사실 4차~5차 정규화도 있는데 너무 깊이 들어가는 것 같아서 1차~3차만 다루게 되었습니다.
만약, 더 궁금하신 분들은 찾아보셔도 좋을 것 같네요.
정규화를 할 때, 조심해야할 부분은 과도한 정규화를 할 경우에는 오히려 데이터를 조회하거나 수정하는 시간이 더 오래 걸릴 수 있습니다.
이 문제로 인해 등장한 '역정규화'라는 개념도 있으니 참고하시길 바랍니다.
네 번째, BCNF 🤡
이 번엔 마지막으로 BCNF를 알아보겠습니다.
BCNF는 Boyce-Codd Normal Function의 약자입니다.
3차 정규화 만족하고 결정자가 후보 키가 아니면 제거합니다. 모든 결정자가 후보키가 되도록 만드는 것이 바로 BCNF 정규화입니다.
이때, 후보키는 어떤 걸 의미할까요?
후보키 Candidate Key
후보키는 릴레이션을 구성하는 속성들 중에서 튜플을 유일하게 식별하기 위해 사용하는 속성들의 부분집합, 즉 기본키 로 사용할 수 있는 속성들을 말한다.
그래서, BCNF 정규화를 진행한 후 모든 Column은 기본키가 될 가능성이 있는 후보키로만 구성되어있습니다.
자, 이렇게 데이터베이스 정규화 과정을 알아보았습니다.
'BACKEND > Database' 카테고리의 다른 글
| SQL SELECT, 제대로 사용하기 (0) | 2020.06.23 |
|---|---|
| SQL SELECT, 제대로 사용하기 - where 조건절 (0) | 2020.06.20 |
| SQL, 어렵지 않게 사용하기 - Constaint (0) | 2020.05.11 |
| SQL, 어렵지 않게 사용하기 - DML (0) | 2020.05.10 |
| MongoDB, 어렵지 않게 시작하기 (0) | 2020.03.15 |

Backend Software Engineer
𝐒𝐮𝐧 · 𝙂𝙮𝙚𝙤𝙣𝙜𝙨𝙪𝙣 𝙋𝙖𝙧𝙠