
2022. 11. 20. 23:38ㆍBACKEND
Rate limiter의 역할과 강단점을 살펴보고, 구현 알고리즘 5가지를 이해하는 것이 해당 포스팅의 목표입니다.
본 포스팅의 모든 그림은 필자가 직접 그린 것으로 무단 사용을 금하며, 사용 시 출처를 반드시 남겨주시길 바랍니다.
Rate Limiting
Rate Limiting이란 특정 시간 내에 할 수 있는 API 호출 수를 의미합니다. 사용자의 API 호출 수가 Rate Limit값을 초과하면 API 호출이 제한되며 요청이 실패하게 됩니다. 즉, 단어 그대로 API의 속도를 제한합니다. Rate Limiter를 적용하면 고가용성과 안정성을 보장할 수 있습니다. 무차별적으로 인입되는 요청을 받는 서버에서의 불안정성을 생각해보면 RateLimiter의 이 특징을 금방 납득할 수 있습니다.
Why use it?
✔️ Protection against DDos
Distributed Denial of Service(이하 DDos)는 악의적인 의도를 가진 사용자에 의해 대량의 패킷 또는 대량의 요청을 보내 대상 시스템을 마비시키는 공격입니다. DDos 공격으로 인해 시스템이 마비되면 해당 시스템뿐만 아니라, 영향 범위가 같은 서버와 연결된 DB까지 미칩니다. 이 공격은 패킷이나 요청의 크기가 서버가 감당할 수 없게 만들어 CPU 사용량을 급증시키기 때문입니다.
✔️ Server Stability and Consistency
서버 안정성을 보장하고 서버를 유지하는데 용이합니다. 최대 호출 수를 제한하기 때문에 총 호출에 대한 예상이 가능하며, 서버에 무리가 가지 않는 선으로 제한 기준을 설정하기 때문에 서버의 안정적인 관리가 가능합니다.
✔️ Cost Control
요청이나 응답, 혹은 프로세스 중 리소스 사용량이 많은 경우를 따져보았을 때, 해당 요청에 금액적인 부담이 커질 수 있습니다. 가령, 대용량 파일 업로드 기능에 무작위로 들어오는 요청들을 떠올려 볼 수 있습니다. 서비스 운영 비용 관리는 비즈니스의 가장 큰 비중을 두기 때문에 결코 무시할 수 없으며, RateLimit을 설정함으로써 비용에 대한 예상을 하고 비용을 절감할 수 있습니다.
Algorithm
그렇다면, RateLimiter를 어떻게 설정할 수 있을까요? 인입되는 요청을 필터링하는 방식을 생각해봐야 합니다. API 마다의 접근 제한을 적절한 설정 값을 지정해야 하며, 어떤 방식으로 어느정도 제한을 둘지를 고민해야 합니다. 제공하는 API마다 특성이 다릅니다. 가령 깃허브의 레포지토리를 생성하는 API와 삭제하는 API가 존재할 때, 이 둘의 차이가 적지 않을 것을 추측할 수 있는데요. 이 둘의 호출 횟수를 동일하게 설정하면 결국 호출 횟수가 부족하거나 낭비될 수 있습니다. 그럼 적용할 수 있는 알고리즘 5개를 하나씩 살펴보도록 하겠습니다.
Token Bucket
: 요청마다 토큰을 소비하여 버켓 안의 토큰이 모두 소진되면 요청 제한
Token Bucket 알고리즘은 Bucket 안에 Token을 담아두고,
요청이 들어올 때 토큰의 수를 하나씩 감소하여 더 이상 사용할 토큰이 없을 때 요청을 제한합니다.

만약 1분에 5개의 요청을 받겠다고 설정해봅시다. 처음에는 Bucket에 Token이 3개 들어있고, 첫 요청이 들어오면 2개로 바뀌고 또 하나가 더 들어본다면 1개로 줄어듭니다. 1분 내에 3개의 요청이 들어와서 토큰이 0개가 되면 다음 refill할 시기(다음 1분)까지 요청을 받아들이지 않습니다.
이 알고리즘은 메모리 효율적이지만, 분산 환경에서 동시에 들어오는 요청에 대해 Race condition이 발생할 수 있다는 문제가 있습니다.
Leaky Bucket
: FIFO 형식의 Bucket(Queue)에 요청을 차례로 담아 크기가 다 차면 요청 제한
Leaky Bucket은 단어에서 느껴지듯이 버켓에 요청을 담고, 가득 차면 더 담지 못하여 새어 나간다leaky는 개념을 가집니다. Leaky Bucket 알고리즘의 예시로 1분에 3개의 요청을 받는다고 가정해보겠습니다.
이 때 Bucket들은 Queue라고 생각하면 됩니다. 인입되는 요청을 FIFO 형식으로 처리합니다. 인입되는 요청은 순서대로 큐에 추가되고 그 크기만큼 요청을 받을 수 있습니다. 현재 2개의 Bucket으로 가정했기 때문에 두 번째까지 요청들이 큐에 순서대로 쌓입니다. 만약 1분이 지나지 않은 상태에서 3개 이상의 요청이 들어오면 이후 요청들은 버려지게spilled out 됩니다. 만약 1분 내에 6개의 요청이 왔다고 한다면 Bucket은 모두 담지 못하겠죠Burst? 3개의 요청은 Bucket에 담고 나머지 3개의 요청을 버립니다. 이 상태에서 1분이 지나면 가장 먼저 들어온 요청을 버리고Leaky 7번 째 요청을 Bucket에 담습니다.
Fixed Window Counter
: 고정된 크기 내에 일정 요청 개수만을 허용
Fixed Window 기술은 굉장히 간단합니다. 고정된 크기 내에 일정 요청 개수만을 허용하는 규칙을 지정합니다. 예를 들어 특정 API에 10분 동안 5개의 요청만을 받는다고 지정해두고, 15분 동안 5개의 요청을 받고 나서 해당 API의 접근을 차단시키는 것입니다. 이 때 10동안의 요청 Window Size를 5로 지정한다고 말할 수 있습니다. Twitter API에서 실제 예시를 확인해볼 수 있습니다.
위의 그림에서 볼 수 있듯이, 15분을 기준으로 각 제공 API의 요청 횟수를 제한한 것을 확인할 수 있습니다.
앱Per App과 유저Per user에 따라 따로 명시하지 않는 한 15분의 간격으로Requests per 15-minute window unless otherwise stated 조회, 작성, 삭제 등의 호출 제한을 지정했으며, API 마다 설정할 요청 횟수를 예상하고 제각각 다르게 설정한 것을 확인할 수 있습니다.
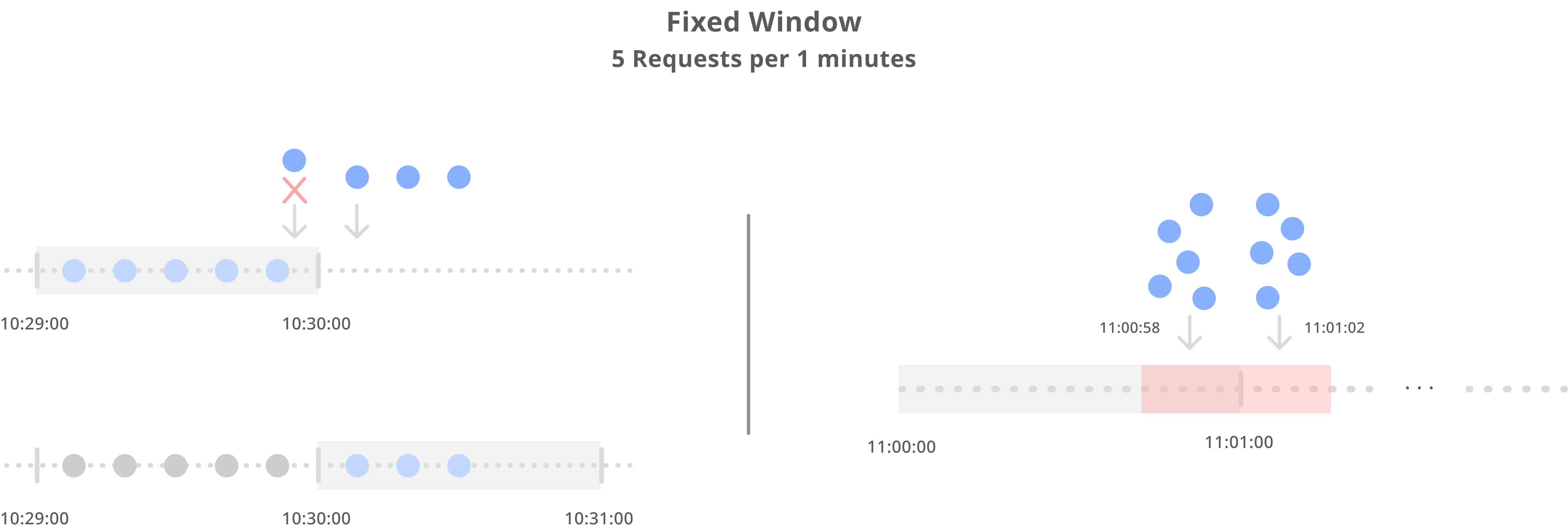
하지만 이 방법은 특정 간격 사이에서 부하가 올 가능성이 있습니다.
1분에 5개의 요청을 받는다고 가정 해보겠습니다. 만약 11:00:00에서 11:01:00로 넘어갈 때를 생각해볼게요. 11:00:58 초에 5개의 요청이 들어오고 11:01:02 에 5개의 요청이 들어왔을 때와 같이 4초 안에 10개의 요청이 들어올 수 있습니다. 굉장히 편향된 시간에 요청이 들어올 수 있다는 것입니다.
Sliding Logs
: 모든 요청을 타임스탬프로 기록하고 현재 시점을 기준으로 시간 범위 내의 요청 개수에 따라 요청 제한
모든 요청은 인입된 타임스탬프로 저장됩니다. 로그를 이용한 슬라이딩 윈도우는 모든 요청을 타임스탬프로 기록하고 현재 시점을 기준으로 윈도우 크기 만큼의 시분초 전의 요청 시간을 확인해서 그 개수를 확인합니다. 가령 1분에 10개의 요청을 받는다고 가정해봅시다. 현재 시간이 10:30:30일 때 1분을 기준으로 판별하기 때문에 슬라이딩 윈도우로 판별할 크기는 10:29:30부터 10:30:30의 크기를 가집니다. 이 때 로그는 요청자 명을 key로 설정하고 타임스탬프를 value로 갖는 쌍의 형태로, 원하는 key-value 자료 구조로 자유롭게 사용할 수 있습니다.
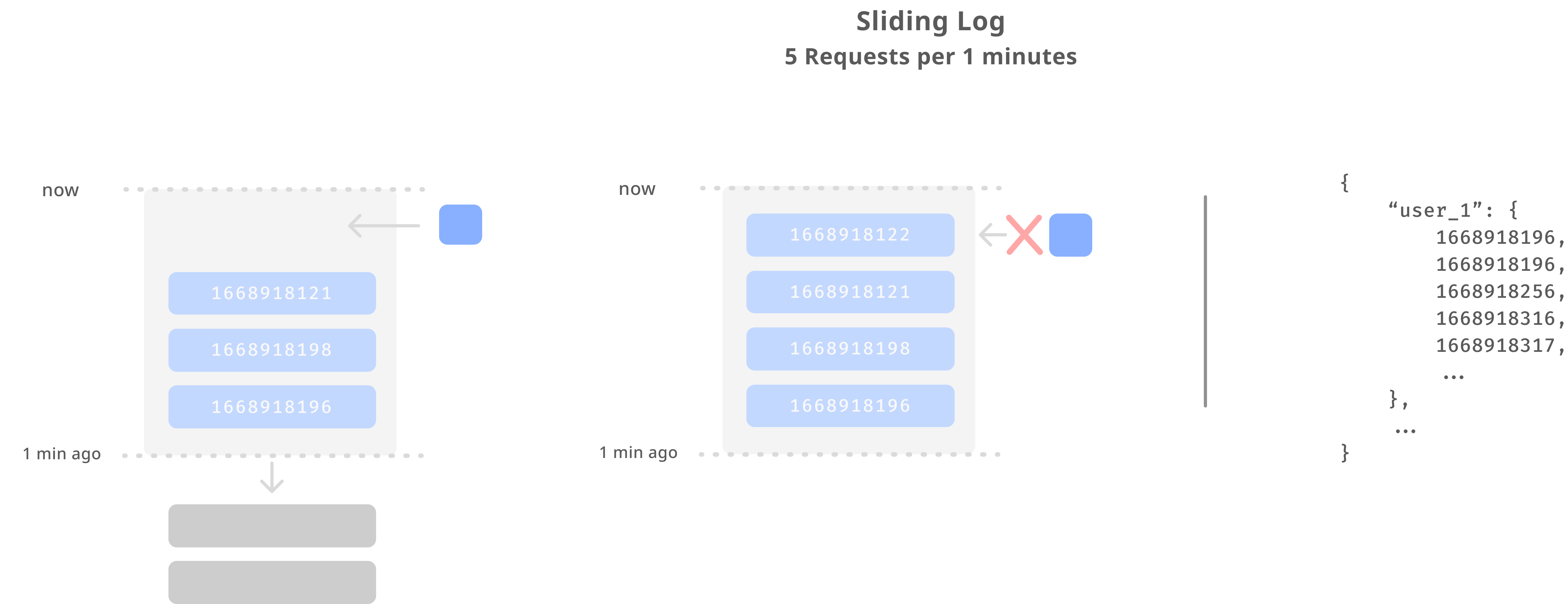
이 시간 범위의 요청을 확인할 때 만약 2개의 요청이 있다면 앞으로 3개의 요청을 더 받아들일 수 있습니다. 만약 5개 이후에 요청이 더 들어온다면 그 이후의 요청을 막습니다. 하지만 이런 방법은 유저 별로 로깅해야 하기 때문에 상당한 메모리를 소비해야합니다.
Sliding Window Counter
: Fixed Window + Sliding Log, 타임스탬프를 모두 저장하지 않고 카운터를 세어 요청 개수에 따라 요청 제한
Fixed Window의 단점인 경계값 부하를 Sliding Log와 같이 범위를 조금씩 움직이는 시간 단위로 측정하고, Sliding Log의 단점인 메모리 소비를 줄이게끔 만든 알고리즘입니다. Fixed Window와 동일하게 각 고정된 윈도우마다 Counter가 존재하며, 타임스탬프을 기준으로 카운팅되는 요청 수를 집계해 이전 윈도우와의 가중치를 고려하여 요청을 제한하는 형식입니다.

가령, 1 분당 10건 처리한다고 가정해볼게요. 동시에, 11시 정각과 11시 1분 사이에는 9건, 11시 1분과 2분 사이에는 5건의 요청이 들어온다고 가정합니다.
이 때, 11:01:15에 요청이 인입됩니다. 그럼 해당 시점에 요청을 받을지 말지를 판별해야하는데요. 11:01:00 ~ 11:01:15 사이의 요청은 시간 범위로 따졌을 때 25%의 지점이며, 그 이전의 시간인 11:00:00 ~ 11:01:00 사이에서의 비중은 75% (1 - 25%)가 됩니다.
요청 제한을 위해서 다음과 같은 계산을 진행합니다.
9×0.75+5=14.75 이고 10건의 제한을 넘었기 때문에 11:01:15에 들어온 요청은 거부됩니다.
마찬가지로 11:01:30에 요청이 인입되면 9×0.5+5=9.5 로 계산할 수 있습니다.
'BACKEND' 카테고리의 다른 글
| HTTP/3, 제대로 이해하기 (0) | 2023.01.01 |
|---|---|
| Circuit Breaker, 제대로 이해하기 (0) | 2022.12.28 |
| Shenyu API Gateway, 어렵지 않게 시작하기 2 (0) | 2022.10.24 |
| Shenyu API Gateway, 어렵지 않게 시작하기 1 (0) | 2022.10.23 |
| Shenyu API Gateway, 어렵지 않게 이해하기 (0) | 2022.10.23 |

Backend Software Engineer
𝐒𝐮𝐧 · 𝙂𝙮𝙚𝙤𝙣𝙜𝙨𝙪𝙣 𝙋𝙖𝙧𝙠