
2022. 7. 21. 23:28ㆍBACKEND/AWS
본 포스팅은 AWS EKS의 실습 과정을 기록한 내용입니다.
좋은 기회를 얻어 AWS EKS를 학습하고 실습하는 시간을 가졌습니다.
AWS ECR로 Docker image를 올려 관리하고, EKS를 직접 실습하는 시간을 가졌습니다.
좋은 기회를 그대로 끝내기는 아쉬워서, 따로 기록한 내용을 정리했습니다.
참고 영상은 링크를 통해 확인할 수 있습니다.
기술의 기초 지식인 Docker와 관련된 이전 포스팅을 참고하셔도 좋을 듯 합니다.
📌 Docker Series
Docker Engine, 제대로 이해하기 (1) - docker engine deep dive
Docker Engine, 제대로 이해하기 (2) - namespace, cgroup
Docker Network, 제대로 이해하기 (1) - libnetwork
Docker Network, 제대로 이해하기 (2) - bridge, host, none drivers
AWS EKS - Web Application (1)에서는 생성한 Kubernetes Cluster에 Ingress Controller를 달아서 요청을 내부로 인입시켜 적절한 Pod Service를 찾게까지 하게끔 설정했습니다.
AWS EKS - Web Application (2)에서는 각 Pod를 올려서 사용자의 요청이 ALB -> Ingress -> Service -> Pod 에 도달하여 Web Application을 접근할 수 있게 설정했습니다.
이번 포스팅에서는 컨테이너형 애플리케이션에 대한 모니터링, 트러블 슈팅 등을 살펴볼 수 있는 Container Insight와 오토 스케일링 기능을 클러스터에 적용하면 보다 탄력적이고 확장이 가능한 환경을 구성해보겠습니다.
CloudWatch agent, Fluent Bit
먼저, 앞으로의 매니페스트 파일을 관리하기 위해 폴더를 만들어 줍니다.
cd ~/environment
mkdir -p manifests/cloudwatch-insight && cd manifests/cloudwatch-insight
아래의 명령어를 이용하여 amazon-cloudwatch라는 네임스페이스를 생성합니다.
$ kubectl create ns amazon-cloudwatch
정상적으로 생성되었다면 아래의 명령어에 대한 결과 값으로 해당 네임스페이스가 목록에 존재하게 됩니다.
$ kubectl get ns
일부 설정 값을 명명한 후, CloudWatch 에이전트 및 Fluent Bit를 설치합니다. 한줄씩 복사, 붙여넣기 작업을 수행하면 됩니다.
ClusterName=eks-demo
RegionName=ap-northeast-2
FluentBitHttpPort='2020'
FluentBitReadFromHead='Off'
[[ ${FluentBitReadFromHead} = 'On' ]] && FluentBitReadFromTail='Off'|| FluentBitReadFromTail='On'
[[ -z ${FluentBitHttpPort} ]] && FluentBitHttpServer='Off' || FluentBitHttpServer='On'
$ wget https://raw.githubusercontent.com/aws-samples/amazon-cloudwatch-container-insights/latest/k8s-deployment-manifest-templates/deployment-mode/daemonset/container-insights-monitoring/quickstart/cwagent-fluent-bit-quickstart.yaml
위의 yaml을 확인해보면 대치를 위한 변수가 정의되어있습니다.
해당 변수는 {{variable}} 형태로 지정되어 있으며, sed 명령어를 통해 정의한 환경변수 값으로 대치하겠습니다.
그 다음, 환경 변수 값을 해당 파일에 적용합니다.
$ sed -i 's/{{cluster_name}}/'${ClusterName}'/;s/{{region_name}}/'${RegionName}'/;s/{{http_server_toggle}}/"'${FluentBitHttpServer}'"/;s/{{http_server_port}}/"'${FluentBitHttpPort}'"/;s/{{read_from_head}}/"'${FluentBitReadFromHead}'"/;s/{{read_from_tail}}/"'${FluentBitReadFromTail}'"/' cwagent-fluent-bit-quickstart.yaml
✔️ SED, 스트림 편집기
stream editor, ed 명령어와 grep 명령어 기능의 일부를 합친 명령어
: 기본적으로 grep 명령어와 비슷하지만, ed처럼 대화식처리는 불가능하며 한 라인씩 읽어 표준 출력으로 출력합니다.
더 자세한 설명은 본 포스팅의 목적과 멀기 때문에 다루지 않으며 위의 명령어만 해석해보면 아래와 같습니다.
-i : insert
# "s/replace_from/replace_to" 을 의미합니다.
s/{{cluster_name}}/'${ClusterName}' : {{cluster_name}} -> ${ClusterName}
s/{{region_name}}/'${RegionName}' : {{region_name}} -> ${RegionName}
s/{{http_server_toggle}}/"'${FluentBitHttpServer}'" : {{http_server_toggle}} -> ${FluentBitHttpServer}
s/{{http_server_port}}/"'${FluentBitHttpPort}'" : {{http_server_port}} -> ${FluentBitHttpPort}
s/{{read_from_head}}/"'${FluentBitReadFromHead}'" : {{read_from_head}} -> ${FluentBitReadFromHead}
s/{{read_from_tail}}/"'${FluentBitReadFromTail}'" : {{read_from_tail}} -> ${FluentBitReadFromTail}
cwagent-fluent-bit-quickstart.yaml : 해당 파일의 이름으로 저장합니다.
해당 파일에서 kind: DaemonSet, metadata.name: fluent-bit 설정 부분에 spec.template.spec.affinity ~ 처럼 아래 설정을 추가해주어야 합니다.
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: eks.amazonaws.com/compute-type
operator: NotIn
values:
- fargate
붙여 넣은 일부를 발췌한 결과는 아래와 같습니다. 들여쓰기에 주의하세요.

파일을 디플로이합니다
$ kubectl apply -f cwagent-fluent-bit-quickstart.yaml
아래의 명령어를 사용하여 정상적으로 설치되었는지 확인합니다.
# cloudwatch-agent pod 및 fluent-bit pod가 각각 3개씩
$ kubectl get po -n amazon-cloudwatch
# OR
# 2개의 Daemonset이 출력
$ kubectl get daemonsets -n amazon-cloudwatch
CloudWatch Conrainer Insight
Amazon CloudWatch 콘솔창을 확인해보면 왼쪽 사이드바에서 Container Insights 에서 다양한 정보를 확인할 수 있습니다.
Performance monitoring이 표시된 select 박스에 Resources로 통해 모든 리소스 리스트를 확인할 수 있습니다.
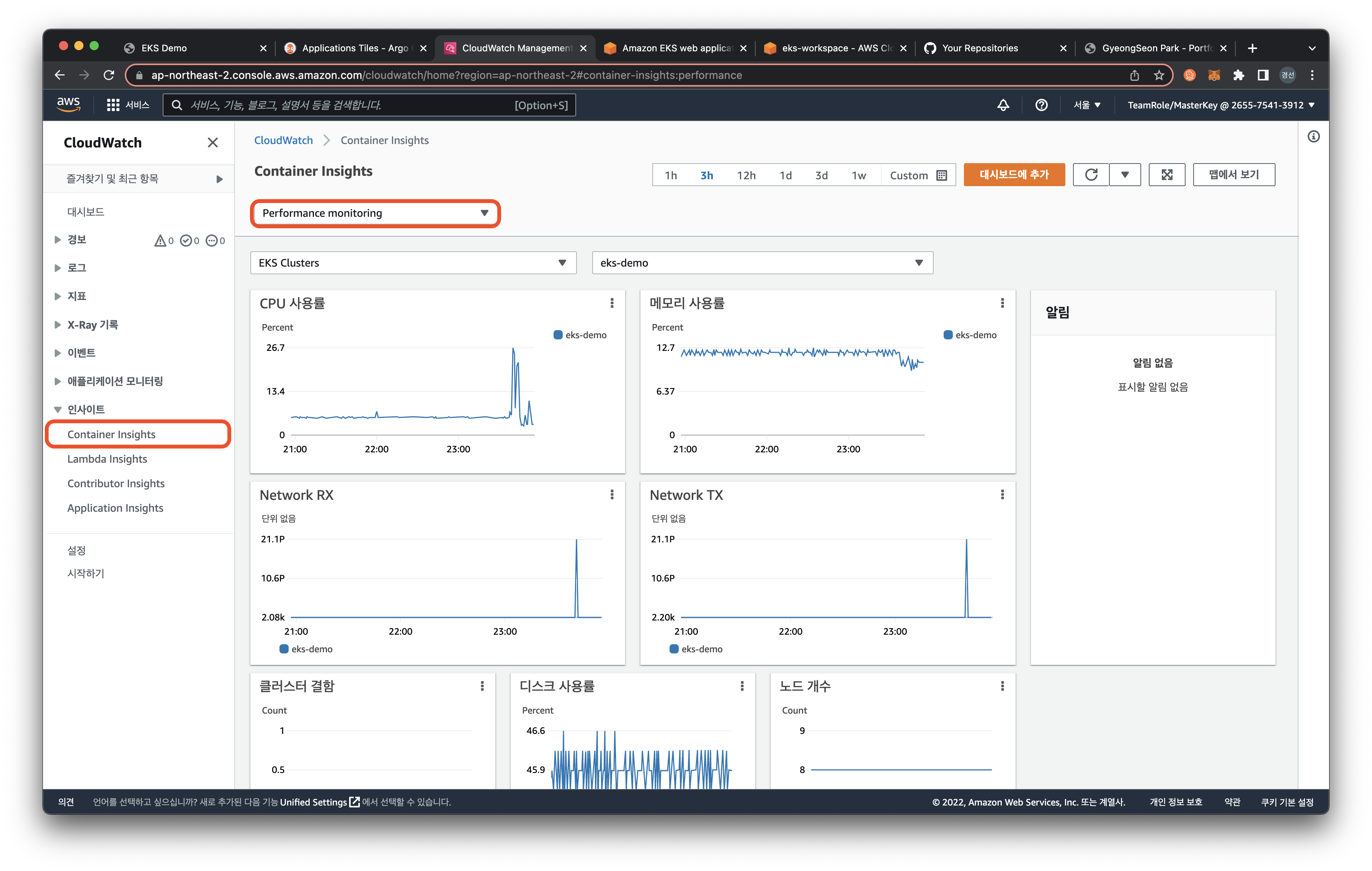
Resources의 Map View를 통해 리소스가 트리 형태로 확인할 수 있습니다.
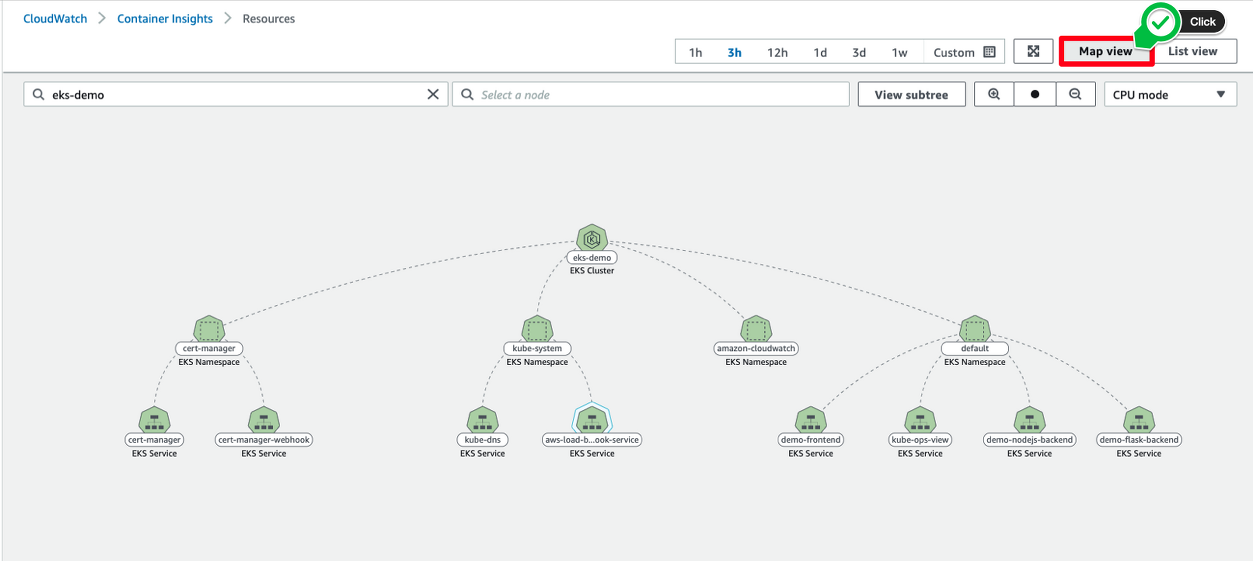
Performance monitoring에서는 EKS Services로 아래처럼 서비스 단위로 메트릭 값을 확인할 수 있습니다.
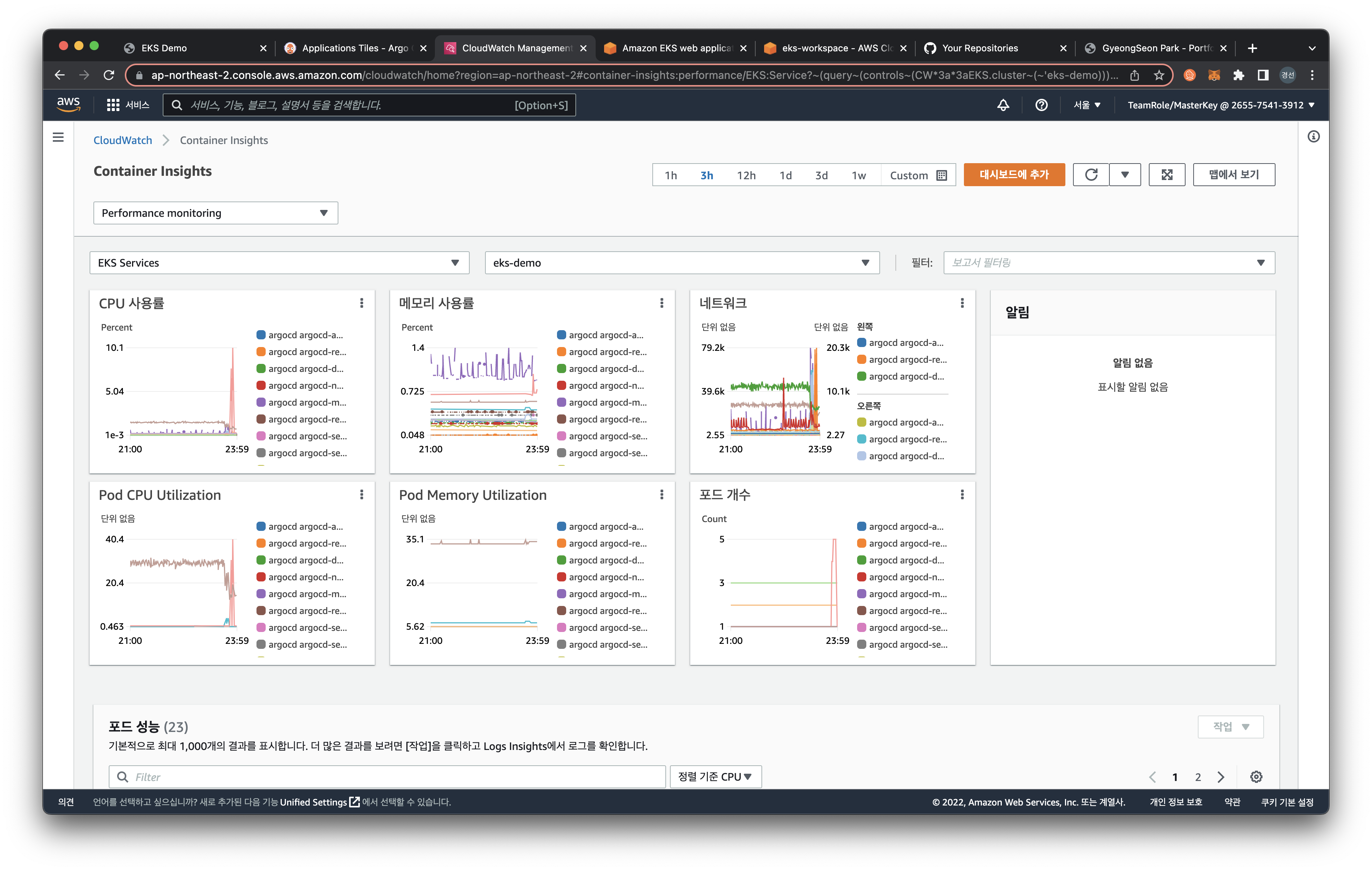
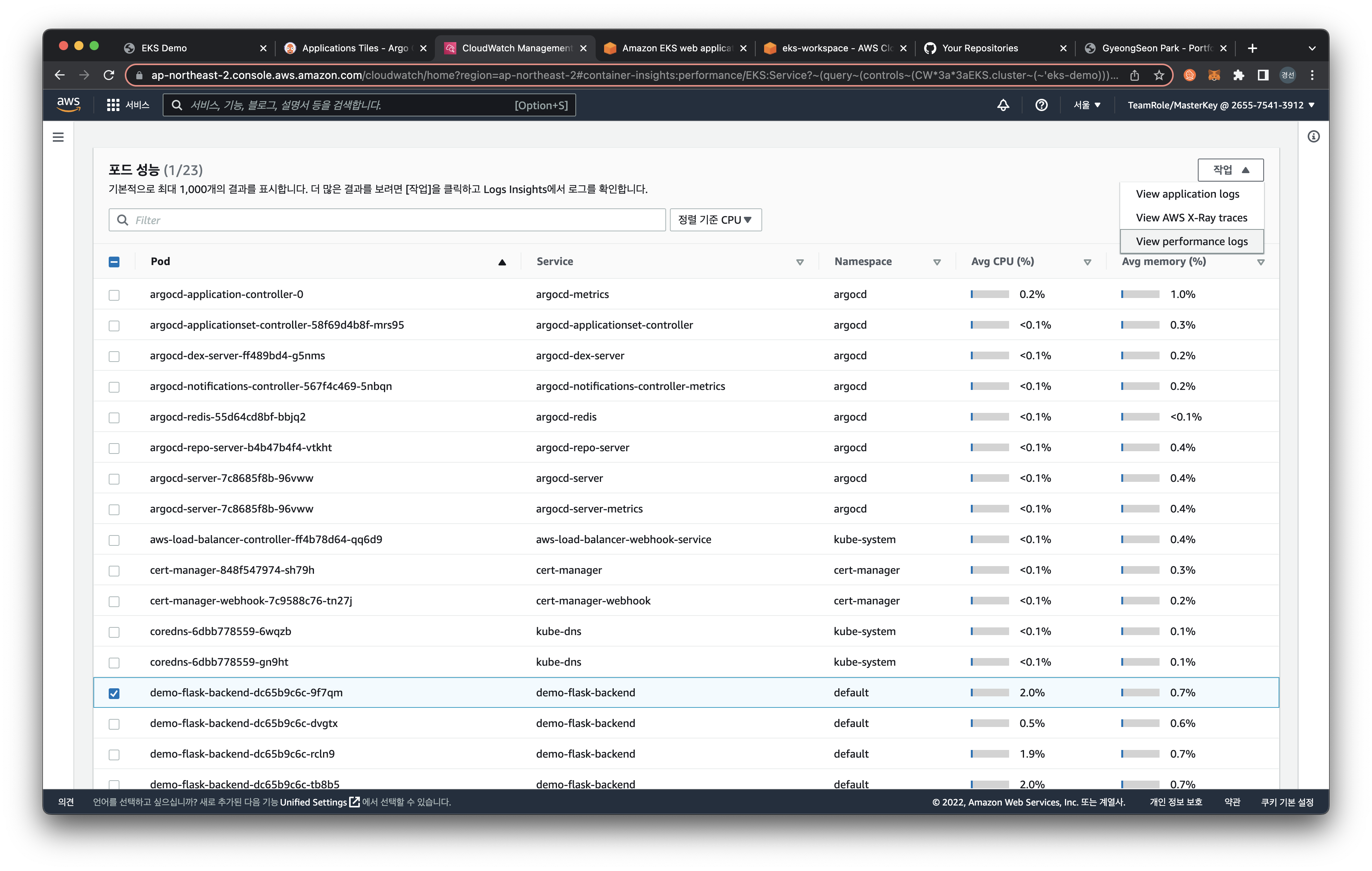
또한, 아래의 Pod performance에서 특정 파드를 선택 후, 우측 드롭박스에서 View performance logs를 클릭하면 아래와 같이 CloudWatch Logs Insights 화면으로 리다이렉션됩니다. 쿼리를 통해, 원하는 로그를 확인할 수 있습니다.
Autoscaling Pod & Cluster
오토 스케일링 서비스는 사용자가 정의한 주기 및 이벤트에 따라 서버를 자동으로 생성하거나 삭제하는 기능을 의미합니다. 오토 스케일링을 사용함으로써 애플리케이션은 트래픽에 따라 탄력적으로 대응할 수 있습니다.
쿠버네티스에는 크게 두 가지의 오토 스케일링 기능이 있습니다.
✔️ HPA(Horizontal Pod AutoScaler)
✔️ Cluster Autoscaler
HPA는 CPU 사용량 또는 사용자 정의 메트릭을 관찰하여 파드 개수를 자동으로 스케일합니다. 그러나 해당 파드가 올라가는 EKS 클러스터 자체 자원이 모자라게 되는 경우, Cluster Autoscaler를 고려해야 합니다.
이러한 오토 스케일링 기능을 클러스터에 적용하면 보다 탄력적이고 확장이 가능한 환경을 구성할 수 있습니다.
HPA
HPA를 사용하여 파드 스케일링 적용하기
HPA(Horizontal Pod Autoscaler) 컨트롤러는 메트릭 값에 값에 따라 파드의 개수를 할당합니다.
파드 스케일링을 적용하기 위해 컨테이너에 필요한 리소스 양을 명시하고, HPA를 통해 스케일할 조건을 작성해야 합니다.
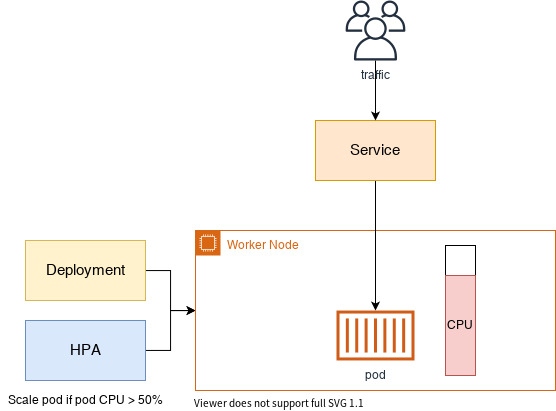
쿠버네티스 metrics server를 생성합니다. Metrics Server는 쿠버네티스 클러스터 전체의 리소스 사용 데이터를 집계합니다. 각 워커 노드에 설치된 kubelet을 통해서 워커 노드나 컨테이너의 CPU 및 메모리 사용량 같은 메트릭을 수집합니다.
$ kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
아래의 명령어를 통해, metrics server가 정상적으로 생성되었는지 확인합니다.
$ kubectl get deployment metrics-server -n kube-system
그 다음, 지난 포스팅에서 만들었던 flask deployment yaml 파일을 아래와 같이 수정합니다.
해당 작업을 통해, 레플리카를 1로 설정하고 컨테이너에 필요한 리소스 양을 설정합니다.
$ cd /home/ec2-user/environment/manifests
cat <<EOF> flask-deployment.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo-flask-backend
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: demo-flask-backend
template:
metadata:
labels:
app: demo-flask-backend
spec:
containers:
- name: demo-flask-backend
image: $ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com/demo-flask-backend:latest
imagePullPolicy: Always
ports:
- containerPort: 8080
resources:
requests:
cpu: 250m
limits:
cpu: 500m
EOF
1vCPU = 1000m(milicore)
yaml 파일을 적용하여 변경 사항을 반영합니다.
$ kubectl apply -f flask-deployment.yaml
HPA를 설정하기 위해, 아래의 yaml 파일도 생성합니다.
$ cat <<EOF> flask-hpa.yaml
---
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: demo-flask-backend-hpa
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: demo-flask-backend
minReplicas: 1
maxReplicas: 5
targetCPUUtilizationPercentage: 30
EOF
해당 yaml 파일을 반영합니다.
$ kubectl apply -f flask-hpa.yaml
$ kubectl autoscale deployment demo-flask-backend --cpu-percent=30 --min=1 --max=5
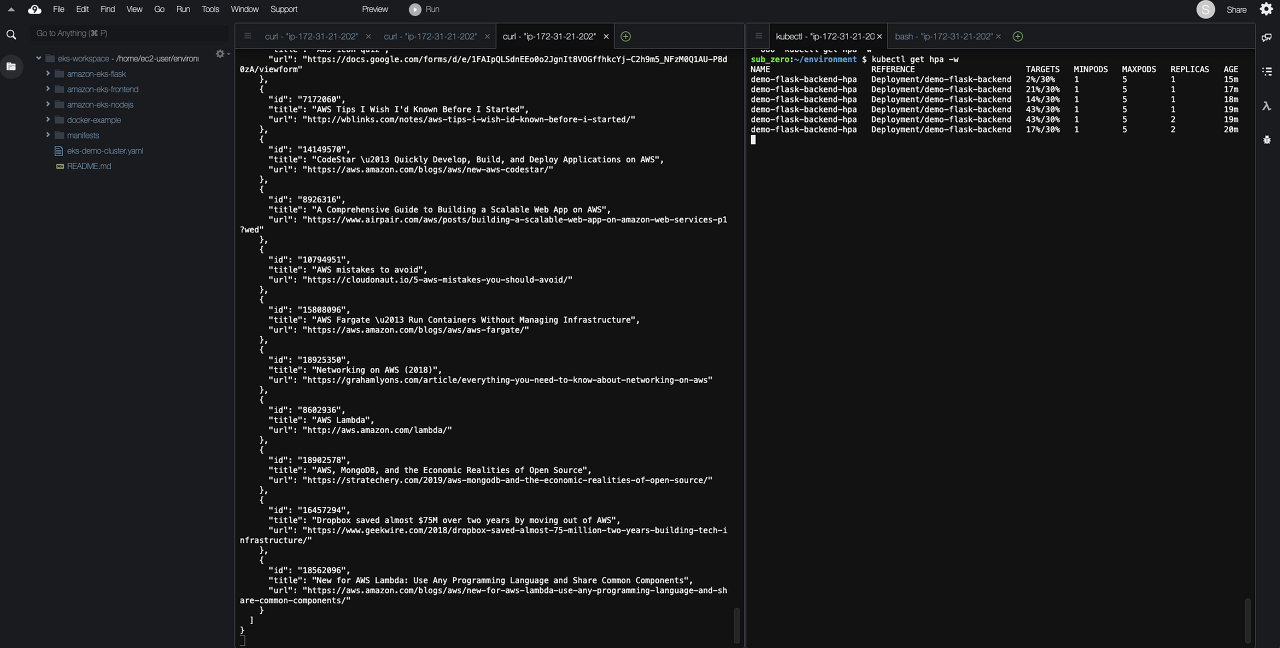
HPA를 생성한 다음, 아래의 명령어로 HPA 상태를 확인할 수 있습니다.
target에서 CPU 사용률이 unknown으로 나올 경우, 잠시 기다린 후, 확인합니다.
kubectl get hpa
부하테스트
오토스케일링 기능이 정상적으로 작동하는지 확인하기 위해 간단한 부하 테스트를 진행합니다.
먼저, 파드의 변화량을 파악하기 위해 아래의 명령어를 입력합니다. 새로운 터미널을 추가로 생성하여 부하 테스트를 진행합니다.
# Terminal 1
$ kubectl get hpa -w
# Terminal 2
ab -c 200 -n 200 -t 30 http://$(kubectl get ingress/backend-ingress -o jsonpath='{.status.loadBalancer.ingress[*].hostname}')/contents/aws
아래의 화면처럼 한쪽에서는 부하를 주고, 한쪽에서는 그에 따른 파드의 변화량을 관찰할 수 있습니다. 부하에 따라 REPLICAS 값이 최대 5까지 변경 됨을 파악할 수 있습니다.
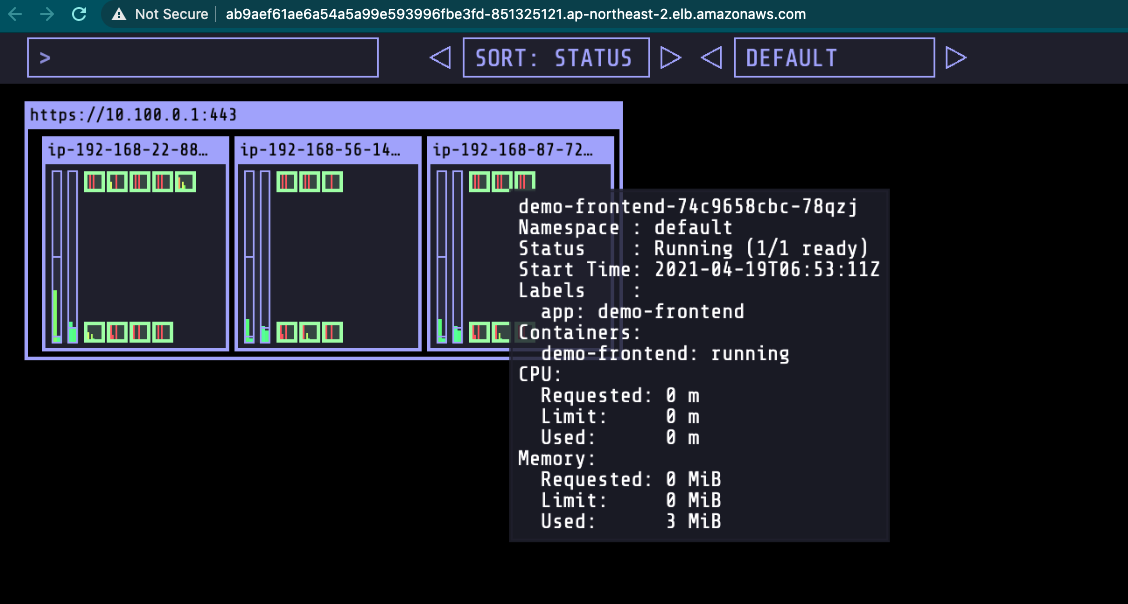
Kubernetes Operational View
Kubernetes Operational View 는 여러 쿠버네티스 클러스터의 상태를 시각적으로 볼 수 있는 간단한 페이지입니다. 모니터링 및 운영 관리의 목적으로 사용되진 않으나 9-2 Cluster Autoscaler와 같이 클러스터 오토스케일링 작업 시, 스케일 인/아웃의 과정을 시각적으로 관찰할 수 있습니다.
본 실습에서는 Helm 을 통해, kube-ops-view를 배포합니다. Helm은 쿠버네티스 차트를 관리하기 위한 도구로 차트는 사전 구성된 쿠버네티스 리소스 패키지를 의미합니다. Helm으로 차트를 관리하는 목적은 다양한 manifest 파일들을 손쉽게 관리하기 위함입니다.
Helm
먼저, helm cli 툴을 설치합니다.
$ curl https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 | bash
# 설치 확인
$ helm version --short
아래의 명령어를 통해, stable 저장소를 더해줍니다.
$ helm repo add stable https://charts.helm.sh/stable
그 다음 helm search repo stable 명령어를 통해, 차트 리스트들을 확인할 수 있습니다.
(옵션) helm 명령어를 위한 Bash completion을 구성합니다.
$ helm completion bash >> ~/.bash_completion
. /etc/profile.d/bash_completion.sh
. ~/.bash_completion
source <(helm completion bash)
kube-ops-view
아래의 명령어를 통해, helm을 통해 kube-ops-view를 설치합니다.
$ helm install kube-ops-view \
stable/kube-ops-view \
--set service.type=LoadBalancer \
--set rbac.create=True
# 설치 확인
$ helm list
아래의 결과 값에서 EXTERNAL-IP 항목에 있는 도메인 주소를 웹 브라우저에서 실행하면 현재 구축한 클러스터 상태를 파악할 수 있습니다.
$ kubectl get svc kube-ops-view
Cluster Autoscaler
이전 페이지에서 파드에 오토 스케일링을 적용하였습니다. 하지만 트래픽에 따라 파드가 올라가는 워커 노드 자원이 모자라게 되는 경우도 발생하게 됩니다. 즉, 워커 노드가 가득 차서 파드가 스케줄될 수 없는 상태가 되는 것이죠.
이때, 사용하는 것이 Cluster Autoscaler(CA) 입니다.
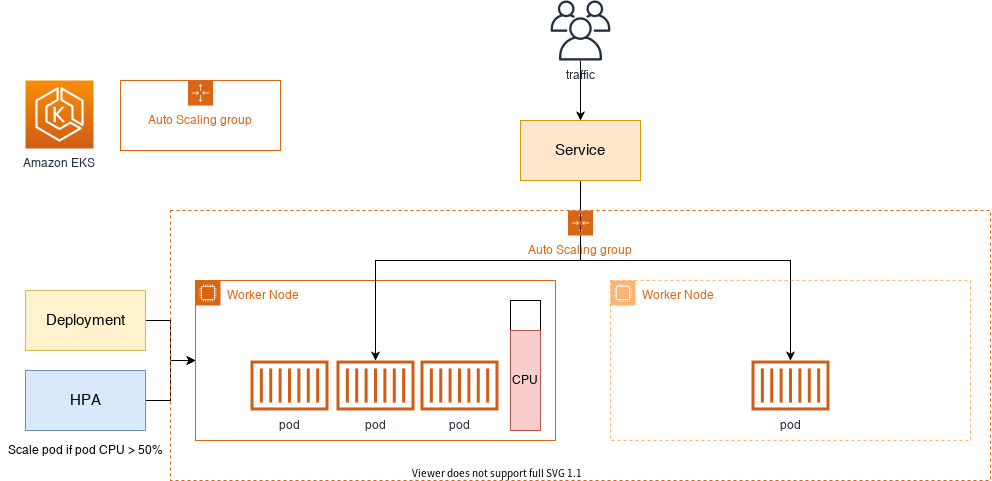
Cluster Autoscaler(CA)는 pending 상태인 파드가 존재할 경우, 워커 노드를 스케일 아웃합니다. 특정 시간을 간격으로 사용률을 확인하여 스케일 인/아웃을 수행합니다. 그리고 AWS에서는 Auto Scaling Group을 사용하여 Cluster Autoscaler를 적용합니다.
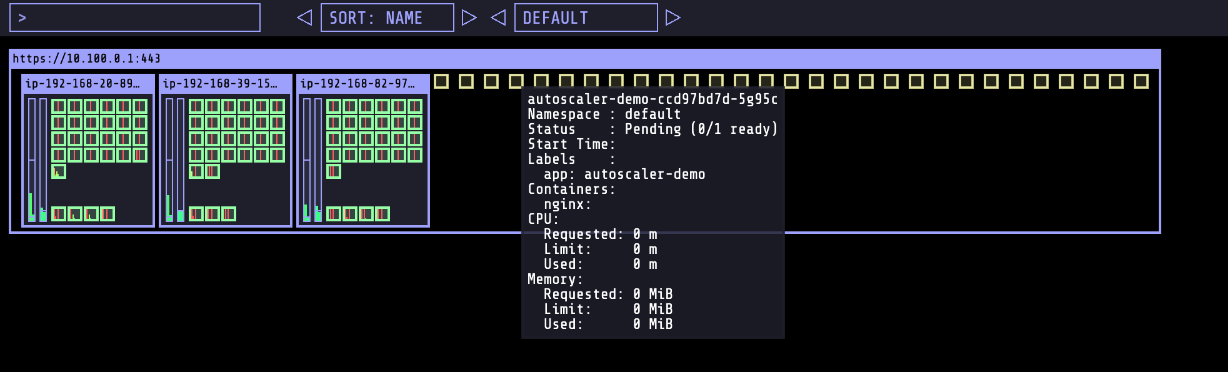
(선택) 위의 이미지처럼 현재 클러스터의 상태를 시각화하기 위해선 kube-ops-view 를 참고합니다.
아래의 명령어로 현재 클러스터의 워커노드에 적용된 ASG(Auto Scaling Group)의 값을 확인합니다.
$ aws autoscaling \
describe-auto-scaling-groups \
--query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='eks-demo']].[AutoScalingGroupName, MinSize, MaxSize,DesiredCapacity]" \
--output table
본 실습에서는 EKS 클러스터를 배포할 때, auto scaling과 관련된 IAM policy를 붙여주는 작업을 미리 수행하였습니다.
하지만 해당 작업을 수행하지 않은 경우, 아래의 숨은 폴더를 클릭하여 관련 IAM 정책을 생성하고 IAM 역할에 붙이는 작업을 수행합니다.
Auto Scaling IAM
Auto Scaling Groups페이지에서 워커노드에 적용된 ASG를 클릭한 후, Group details 값을 아래와 같이 업데이트합니다.
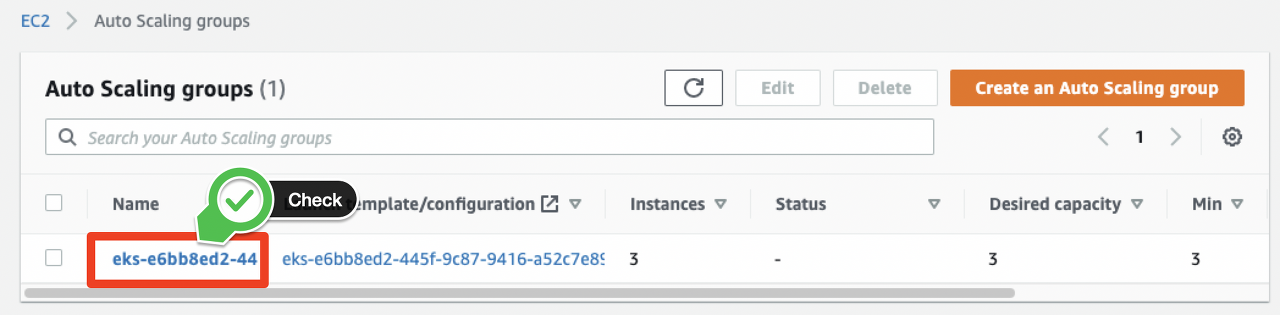
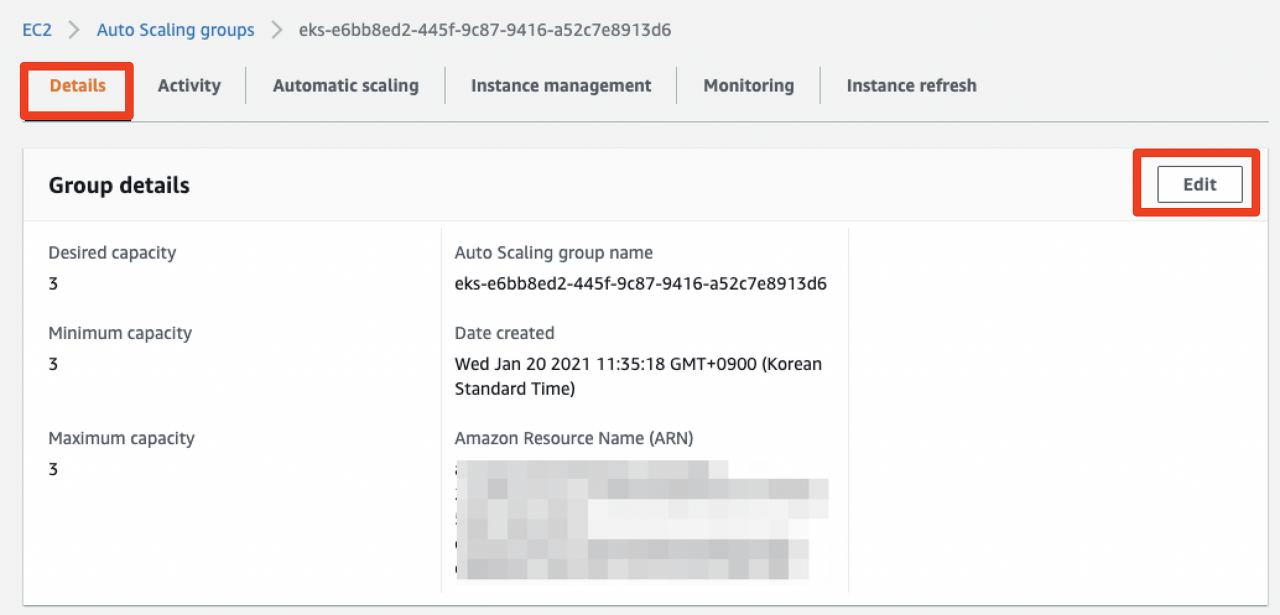
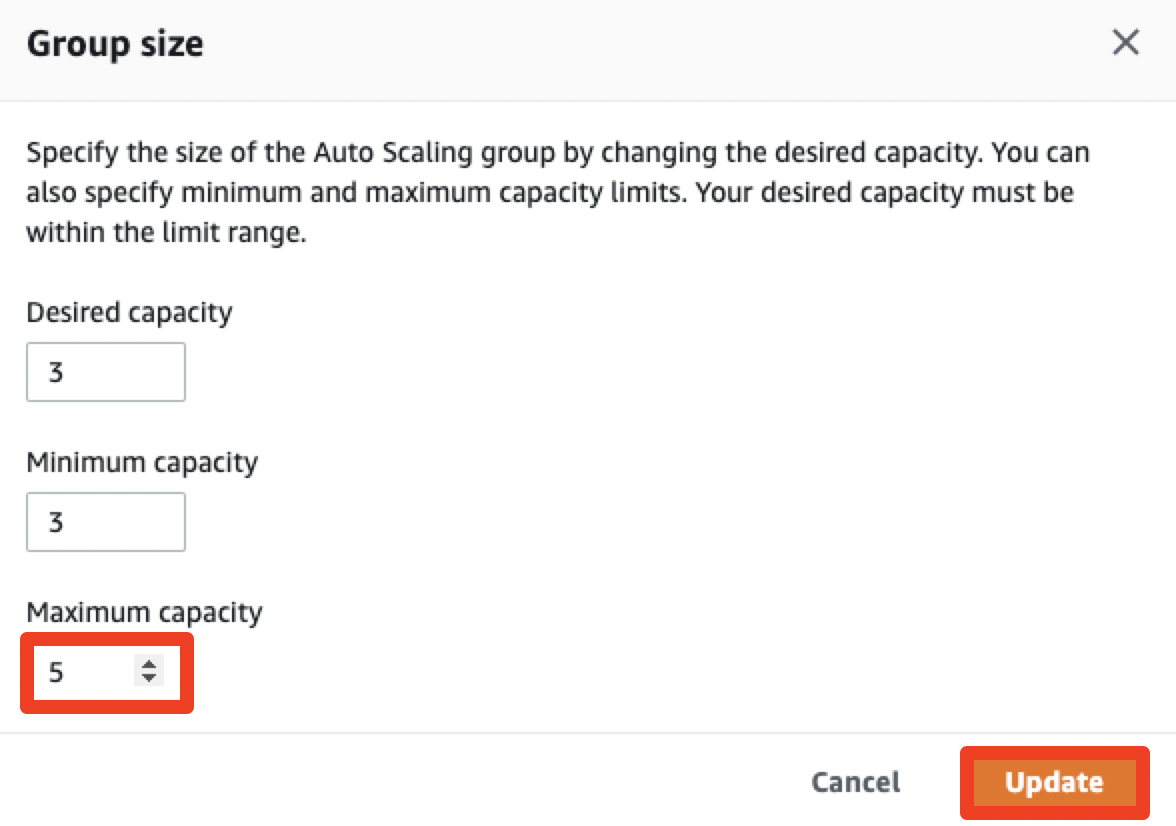
이제 다시 Cluster Atuoscaler 프로젝트에서 제공하는 배포 예제 파일을 다운로드합니다.
$ wget https://raw.githubusercontent.com/kubernetes/autoscaler/master/cluster-autoscaler/cloudprovider/aws/examples/cluster-autoscaler-autodiscover.yaml
다운로드한 yaml 파일을 열고 클러스터 이름(eks-demo)을 설정한 후, 배포합니다.
...
command:
- ./cluster-autoscaler
- --v=4
- --stderrthreshold=info
- --cloud-provider=aws
- --skip-nodes-with-local-storage=false
- --expander=least-waste
- --node-group-auto-discovery=asg:tag=k8s.io/cluster-autoscaler/enabled,k8s.io/cluster-autoscaler/eks-demo
...$ kubectl apply -f cluster-autoscaler-autodiscover.yaml
오토스케일링 기능이 정상적으로 작동하는지 확인하기 위해 간단한 부하 테스트를 진행합니다.
먼저, 워쿼 노드 수의 변화량을 파악하기 위해 아래의 명령어를 입력합니다.
$ kubectl get nodes -w
그 다음 새로운 터미널 창을 킨 다음, 워커 노드를 늘리기 위해, 100개의 파드를 배포하는 명령을 수행합니다.
$ kubectl create deployment autoscaler-demo --image=nginx
$ kubectl scale deployment autoscaler-demo --replicas=100
파드의 배포 진행 상태를 파악하기 위해 아래의 명령어를 수행합니다.
$ kubectl get deployment autoscaler-demo --watch
kube-ops-view 를 설치했다면 아래와 같은 결과를 시각적으로 확인할 수 있습니다. 이를 통해, 2개의 워커노드가 추가적으로 생성되었고, 100개의 파드가 올라간 것을 확인할 수 있습니다.
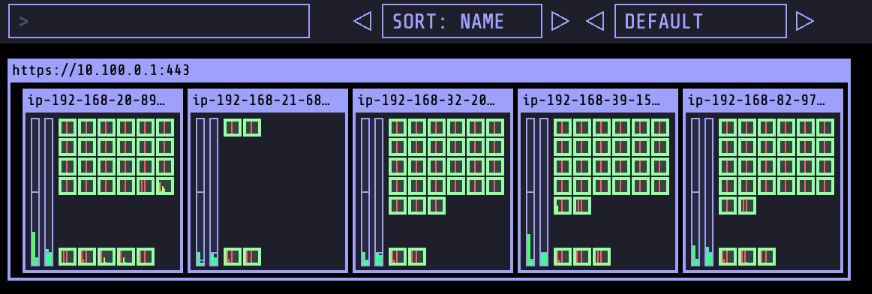
아래의 명령어로 이전에 생성한 파드를 삭제하면 워커 노드가 스케일인 되는 것을 확인할 수 있습니다.
$ kubectl delete deployment autoscaler-demo
'BACKEND > AWS' 카테고리의 다른 글
| AWS S3, 제대로 이해하기 - Storage Classes (0) | 2023.03.12 |
|---|---|
| AWS S3, 제대로 이해하기 - S3 Basics (2) | 2023.02.26 |
| AWS EKS - Web Application (2) (0) | 2022.07.19 |
| AWS EKS - Web Application (1) (0) | 2022.07.17 |
| AWS CodeDeploy VS AWS Elastic Beanstalk (0) | 2021.02.07 |

Backend Software Engineer
𝐒𝐮𝐧 · 𝙂𝙮𝙚𝙤𝙣𝙜𝙨𝙪𝙣 𝙋𝙖𝙧𝙠