
2022. 7. 13. 23:54ㆍBACKEND/Database
본 포스팅의 목표는 Spring - Mabatis 에서 ON DUPLICATE KEY UPDATE를 이용한 대량의 데이터를 추가/업데이트하는 것입니다.
안녕하세요.
이번 포스팅은 대량의 데이터를 업데이트할 때 효과적인 두 번째 방법 소개하고자 합니다.
MySQL 이나 MariaDB에서 INSERT와 UPDATE를 여러 개를 한 번에 실행할 수 있는 ON DUPLICATE KEY UPDATE 구문입니다.
테스트를 통해 어느정도의 시간이 걸리는지를 확인해보겠습니다.
첫 번째 방법은 지난 포스팅에서 다룬 MySQL의 Temporary Table를 사용하는 것이었는데요.
Temporary Table과의 속도 비교도 같이 진행할 예정입니다.
ON DUPLICATE KEY UPDATE를 이용한 UPSERT는 MyBatis에서 Bulk Update를 구현해야 할 때 유용하게 사용할 수 있습니다.
UPSERT
MySQL, MariaDB에서는 INSERT와 UPDATE를 동시에 실행할 수 있는 구문인 'ON DUPLICATE KEY UPDATE'를 지원합니다.
INSERT ... ON DUPLICEKE KEY UPDATE 구문은 MySQL, MariaDB 에서의 INSERT 문의 확장이며
단지 SQL 표준 INSERT문의 확장일 뿐, ANSI 표준은 아닙니다.
MySQL 4.1버전 이상부터 지원합니다.
동일한 Primary Key 혹은 Unique Key가 존재하면 UPDATE 문을 실행합니다.
먼저 기본적인 구문 형식을 살펴보겠습니다.
INSERT INTO tbl_name (col1, col2) VALUES (val1, val2)[,(...),...]
ON DUPLICATE KEY UPDATE col=expr[, col=expr]
INSERT 문의 확장이기 때문에 BULK, ... SELECT ... FROM 등과 같이 모든 INSERT 구문의 특성을 사용할 수 있습니다.
이해를 위해 예시를 들어볼게요.
/* a: unique key */
INSERT INTO t1 (a,b,c) VALUES (1,2,3)
ON DUPLICATE KEY UPDATE c=c+1;
t1이라는 테이블의 unique key가 a 라고 할 때, 위의 구문은 INSERT를 할지 UPDATE를 할지를 바로 a 값을 통해 실행합니다.
만약, 이미 t1이라는 테이블에 a가 1일 데이터가 존재하지 않는다면 INSERT, 존재한다면 UPDATE 를 실행합니다.
간단히 풀어보면 아래와 같습니다.
$if (a=1) ∈ t1$, INSERT INTO t1 (a, b, c) VALUES (1, 2, 3);
$else$ , UPDATE t1 SET c=c+1 WHERE a=1;
이제 조금 더 효과적인 BULK UPSERT를 알아보도록 하겠습니다.
INSERT를 할 때, 높은 성능을 위해서 BULK INSERT를 사용하곤 합니다.
만약, BULK INSERT에 대한 설명은 'Bulk Insert, 성능 테스트'를 참고해주세요.
ON DUPLICATE KEY UPDATE 구문의 형식은 아래와 같습니다.
INSERT INTO t1 (a,b,c) VALUES (1,2,3),(4,5,6) AS new
ON DUPLICATE KEY UPDATE c = new.a + new.b;
UPDATE ... VALUES
UPDATE 구문에서 VALUES 를 사용하여 INSERT를 시도했던 데이터를 가져올 수 있는데요.
MySQL 공식 문서를 확인하면 아래와 같이 소개합니다.
In assignment value expressions in the ON DUPLICATE KEY UPDATE clause, you can use the VALUES(col_name) function to refer to column values from the INSERT portion of the INSERT ... ON DUPLICATE KEY UPDATE statement. In other words, VALUES(col_name) in the ON DUPLICATE KEY UPDATE clause refers to the value of col_name that would be inserted, had no duplicate-key conflict occurred. This function is especially useful in multiple-row inserts.
번역해보면 아래와 같습니다.
ON DUPLICE KEY UPDATE 절의 할당 값 식에서 VALUES(col_name) 함수를 사용하여 INSERT ... ON DUPLICATE KEY UPDATE 문의 INSERT 부분에서 해당 열 값을 참조할 수 있습니다. 즉, ON DUPLICE KEY UPDATE 절의 VALUES(col_name)는 중복 키 충돌이 발생하지 않은 경우 삽입될 col_name 값을 참조합니다. 해당 기능은 다중 행 삽입에서 특히 유용합니다.
아래 아주 간단한 예시를 보면 바로 이해하실 거예요.
INSERT INTO user_tbl (name, email, type)
VALUES ('name1', 'email1', 'type1'), ('name2', 'email2', 'type2'), ...
ON DUPLICATE KEY UPDATE
email = VALUES(email),
type = VALUES(type)
위와 같이 ON DUPLICE KEY UPDATE 절에서 user_tbl의 email, type 컬럼 명을 VALUES로 참조할 수 있다는 의미입니다.
하지만, 다중 행의 데이터를 UPDATE 하려고 할 때, MySQL 8.0.20부터 VALUES를 사용하면 warning을 줍니다.
대신 아래와 같이 사용하라고 안내하고 있어요.
INSERT INTO t1 (a,b,c) VALUES (1,2,3),(4,5,6) AS new
ON DUPLICATE KEY UPDATE c = new.a+new.b;
-- or
INSERT INTO t1 (a,b,c) VALUES (1,2,3),(4,5,6) AS new(m,n,p)
ON DUPLICATE KEY UPDATE c = m+n;
하지만 MariaDB를 사용하는 환경에서는 VALUES 외에 다른 방법이 없어보입니다.
Multiple Unique Index
해당 기능 사용할 때 주의 점이 있습니다.
만약, Unique Key 가 여러개면 어떻게 될까요?
공식 문서를 확인해보면 다음과 같은 문구가 있습니다.
you should try to avoid using an ON DUPLICATE KEY UPDATE clause on tables with multiple unique indexes.
만약, Unique Index를 여러개 사용하고 있다면 ON DUPLICATE KEY UPDATE 구문을 피하라는 내용입니다.
왜 일까요?
만약 unique1, unique2, data 라는 필드가 있다고 해봅시다.
| unique1 | unique2 | data |
| 1 | 1 | abc |
| 2 | 2 | def |
| 3 | 3 | ghi |
데이터를 (1, 2, 'hey'), (4, 1, 'hi'), (5, 3, 'hello') 를 넣을 때 아래와 같은 결과가 나옵니다.
| unique1 | unique2 | data |
| 1 | 1 | hi |
| 2 | 2 | def |
| 3 | 3 | hello |
제가 추측한 내용은 아래와 같습니다.
먼저, (1, 2, 'hey')가 실행되고 첫 번째 행의 unique1 값이 동일하므로 가 'abc' 👉🏻 'hey'
(4, 1, 'hi')가 실행되고 첫 번째 행의 unique2 값이 동일하므로 'hey' 👉🏻 'hi'
(5, 3, 'hello')가 실행되고 세 번째 행의 unique2 값이 동일하므로 'ghi' 👉🏻 'hello'
다른 가능성이 있을지 떠오르지 않네요.
정리하자면, unique 값이 여러 개일 때 하나라도 동일하면 대상 데이터가 update 되고,
이 때 동일하지 않은 다른 unqiue 값은 업데이트 할 수 없습니다.
만약, 이러한 상황이 생긴다면 Temporary Table을 사용하세요.
Set Up
테스트를 본격적으로 실행하기 전, 미리 세팅해야할 조건들을 살펴보겠습니다.
지난 포스팅과 동일한 세팅을 하면 됩니다.
Test Table
먼저 사용할 쿼리를 살펴보도록 할게요.
테이블은 아주 간단하게 정의했습니다.
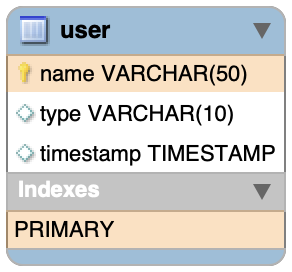
Create Data Set
업데이트가 될 데이터를 테이블에 저장하겠습니다.
@BeforeEach
void setUp() {
// ① 테이블 초기화
userDAO.truncate();
List<UserVO> insertList = new ArrayList<>(TEST_SIZE);
// ② 데이터 Type을 "Init"으로 설정해서 Update와 구별 (e.g. UserVO("UserVO078", "Init"))
for (int i = 1; i <= TEST_SIZE; i++) {
insertList.add(new UserVO(String.format("UserVO%03d", i), "Init"));
}
// ③ 데이터 저장
int cnt = userDAO.insertInit(insertList);
}
내용은 주석으로 달아두었습니다.
TEST_SIZE 만큼의 데이터를 먼저 테이블에 저장하는 코드입니다.
어려운 내용은 아니니, 자세한 설명은 생략하겠습니다.
MyBatis
MyBatis 내의 쿼리는 아래와 같이 작성했습니다.
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="demo.bulkUpsert">
<insert id="bulkUpsertUserList" parameterType="com.gngsn.demo.bulkUpsert.UserVO">
INSERT INTO user (name, type) VALUES
<foreach collection="list" item="item" separator=",">
(#{item.name}, #{item.type})
</foreach>
ON DUPLICATE KEY UPDATE
type = VALUES(type)
</insert>
</mapper>
Mybatis의 foreach 구문을 사용해서 업데이트하는 구문입니다.
Upsert Test
Upsert Test는 기존 키가 없는 데이터를 INSERT하고,
기존 키가 있는 데이터를 UPDATE 시켜 정상적으로 동작하는지와
각 INSERT, UPDATE 수행 별 속도 차이를 비교할 예정입니다.
해당 테스트를 위해 아래와 같은 테스트 케이스를 준비했습니다.
Scenario
CASE 1. Insert 100%
CASE 2. Insert 80%, Update 20%
CASE 3. Insert 20%, Update 80%
CASE 4. Update 100%
테스트 시나리오는 위와 같이 구분했습니다.
위의 상황에 따라서 테스트 데이터를 잘 생성해야 할텐데요.
아래와 같이 테스트 데이터를 생성했습니다.
Insert/Update Test Set
INSERT UPDATE 구문을 둘 다 텍스트해야 하기 때문에 두 데이터 값을 구분해서 생성합니다.
List<UserVO> createTestData(int insertSize) {
List<UserVO> testSet = new ArrayList<>(TEST_SIZE);
int outOfTestSizeNum = TEST_SIZE * 2;
// ① Insert Test Data 생성
for (int i = 1; i <= insertSize; i++) {
testSet.add(new UserVO(String.format("UserVO%05d", (outOfTestSizeNum + i)), "Insert"));
}
// ② Update Test Data 생성
for (int i = 1; i <= (TEST_SIZE - insertSize); i++) {
testSet.add(new UserVO(String.format("UserVO%05d", i), "Update"));
}
return testSet;
}
① Insert Test Data
Insert 하려는 데이터는 기존 데이터, 즉 type이 "Init" 이 아닌 값과 Unique 값이 겹쳐서는 안됩니다.
그래서 TEST_SIZE의 2배의 값을 더해서 항상 새로운 Unique 값을 가진 데이터를 생성합니다.
가령, TEST_SIZE가 1000일 때, Init data의 범위는 [1, 1000] 이며 Insert data는 [2001, 3000] 이 되는 것입니다.
② Update Test Data
Update 하려는 데이터는 기존 데이터와 겹치는 범위를 가집니다.
Insert 하려는 크기에 따라서 나머지 크기만큼을 생성합니다.
가령, TEST_SIZE가 1000일 때, Init data의 범위는 [1, 1000] 이며
Insert data의 비율을 80이라고 한다면 그 범위는 [2001, 2080] 이고
Update data의 비율은 20이 될테니 그 범위는 [1, 20]이 되는 것입니다.
이제 실제 테스트를 진행해보겠습니다.
Insert 100%
모든 데이터를 INSERT만 실행합니다.
BULK INSERT만을 실행하니, 속도가 가장 빠를 것 같다고 예상되네요.
@Test
public void given_insert100() {
// given
List<UserVO> testSet = createTestData(TEST_SIZE);
// when
double beforeTime = System.currentTimeMillis();
int cnt = userDAO.bulkUpsertUserList(testSet);
double afterTime = System.currentTimeMillis();
// then
Assertions.assertEquals(TEST_SIZE, cnt);
log.info("### run time : {}s", (afterTime-beforeTime) / 1000);
}
INSERT size는 TEST_SIZE를 그대로 주어서 100%를 설정했습니다.
결과는 아래와 같습니다.
==> Preparing: TRUNCATE user;
==> Parameters:
<== Updates: 0
==> Preparing: INSERT INTO user (name, type) VALUES (?, ?) , (?, ?) , ...
==> Parameters: UserVO00001(String), Init(String), UserVO00002(String), ...
<== Updates: 10000
==> Preparing: INSERT INTO user (name, type) VALUES (?, ?) , (?, ?) , ...
==> Parameters: UserVO20001(String), Insert(String), UserVO20002(String), ...
<== Updates: 10000
### run time : 0.585s
Insert 80%, Update 20%
데이터의 80%를 INSERT, 나머지 20%를 UPDATE로 실행합니다.
Assertions를 보면 예상 실행 쿼리문 수가 기존 테스트 셋에 업데이트 사이즈를 더한 값인데요.
예상컨데, INSERT를 시도하고 만약 "Duplicate entry for key 'PRIMARY'" 등과 같이
Unique가 동일하면 UPDATE를 수행하지 않을지 짐작합니다.
아시는 분은 댓글 부탁드립니다 🙏🏻
@Test
public void given_insert80update20() {
// given
int insertSize = (int) (TEST_SIZE * 0.8);
List<UserVO> testSet = createTestData(insertSize);
// when
double beforeTime = System.currentTimeMillis();
int cnt = userDAO.bulkUpsertUserList(testSet);
double afterTime = System.currentTimeMillis();
// then
Assertions.assertEquals(TEST_SIZE + (TEST_SIZE - insertSize), cnt);
log.info("### run time : {}s", (afterTime-beforeTime) / 1000);
}
결과는 아래와 같습니다.
==> Preparing: TRUNCATE user;
==> Parameters:
<== Updates: 0
==> Preparing: INSERT INTO user (name, type) VALUES (?, ?) , (?, ?) , (?, ?), ...
==> Parameters: UserVO00001(String), Init(String), UserVO00002(String), ...
<== Updates: 10000
==> Preparing: INSERT INTO user (name, type) VALUES (?, ?) , (?, ?) , ...
==> Parameters: UserVO20001(String), Insert(String), UserVO20002(String), ...
<== Updates: 12000
### run time : 0.896s
Insert 20%, Update 80%
데이터의 20%를 INSERT, 나머지 80%를 UPDATE로 실행합니다.
@Test
public void given_insert20update80() {
// given
int insertSize = (int) (TEST_SIZE * 0.2);
List<UserVO> testSet = createTestData(insertSize);
// when
double beforeTime = System.currentTimeMillis();
int cnt = userDAO.bulkUpsertUserList(testSet);
double afterTime = System.currentTimeMillis();
// then
Assertions.assertEquals(cnt, TEST_SIZE + (TEST_SIZE-insertSize));
log.info("### run time : {}s", (afterTime-beforeTime) / 1000);
}
결과는 아래와 같습니다.
==> Preparing: TRUNCATE user;
==> Parameters:
<== Updates: 0
==> Preparing: INSERT INTO user (name, type) VALUES (?, ?) , (?, ?) , ...
==> Parameters: UserVO00001(String), Init(String), UserVO00002(String), ...
<== Updates: 10000
==> Preparing: INSERT INTO user (name, type) VALUES (?, ?) , (?, ?) , ...
==> Parameters: UserVO20001(String), Insert(String), UserVO20002(String), ...
<== Updates: 18000
### run time : 0.924s
Update 100%
모든 데이터를 UPDATE만 실행합니다.
모든 데이터를 UPDATE 로만 실행하니 속도가 가장 느릴 것 같다고 예상되네요.
@Test
public void given_update100() {
// given
List<UserVO> testSet = createTestData(0);
// when
double beforeTime = System.currentTimeMillis();
int cnt = userDAO.bulkUpsertUserList(testSet);
double afterTime = System.currentTimeMillis();
// then
Assertions.assertEquals(cnt, TEST_SIZE + TEST_SIZE);
log.info("### run time : {}s", (afterTime-beforeTime) / 1000);
}
결과는 아래와 같습니다.
==> Preparing: TRUNCATE user;
==> Parameters:
<== Updates: 0
==> Preparing: INSERT INTO user (name, type) VALUES (?, ?) , (?, ?) , ...
==> Parameters: UserVO00001(String), Init(String), UserVO00002(String), ...
<== Updates: 10000
==> Preparing: INSERT INTO user (name, type) VALUES (?, ?) , (?, ?) , ...
==> Parameters: UserVO00001(String), Update(String), UserVO00002(String), ...
<== Updates: 20000
### run time : 0.948s
Result
표로 정리하면 아래와 같습니다.
| INSERT, UPDATE RATIO \ TEST SIZE | 10_000 (1) | 10_000 (2) | 10_000 (3) | 10_000 (4) | 10_000 (5) |
| 100, 0 | 🥇 0.585s | 🥇 0.463s | 🥇 0.454s | 🥇 0.483s | 🥇 0.521s |
| 80, 20 | 🥈 0.896s | 🥈 0.816s | 🥈 0.879s | 🥉 0.928s | 🥉 0.712s |
| 20, 80 | 🥉 0.924s | 🥉 0.912s | 🥉 1.195s | 🥈 0.693s | 🥈 0.649s |
| 0, 100 | 🥉 0.948s | 🥈 0.855s | 🥈 0.848s | 🥉 0.9s | 🥉 0.711s |
조금 더 명확한 결과가 나왔으면 했는데, 그렇지 않았는데요.
테스트 데이터가 적어서 차이가 안보일 수도 있을 것 같아 크기를 키워보았습니다.
| INSERT, UPDATE RATIO \ TEST SIZE | 50_000 (1) | 50_000 (2) | 50_000 (3) | 100_000 (1) | 100_000 (2) |
| 100, 0 | 🥇 2.233s | 🥇 1.795s | 🥇 2.158s | 🥇 6.325s | 🥇 5.587s |
| 80, 20 | 🥉 4.647s | 🥈 2.9s | 🥈 2.84s | 🥉 8.213s | 🥈 5.466s |
| 20, 80 | 🥈 3.164s | 🥉 3.449s | 🥈 2.704s | 🥈 6.958s | 🥉 7.932s |
| 0, 100 | 🥉 4.52s | 🥉 3.29s | 🥉 3.225s | 🥉 7.156s | 🥉 10.468s |
INSERT 문만 실행하면 확연히 빠른 것을 확인할 수 있고,
UPDATE 문만을 실행하면 확연히 느린 것이 보이네요.
섞어서 사용하면 간혹 차이가 있는데, 확률적으로 판단할 수 없어 비교가 어려워보입니다.
vs Temporary Table
그렇다면, 이번에는 지난 번의 Temporary Table 과의 Bulk Update 비교를 진행해보겠습니다.
@Slf4j
@SpringBootTest
public class BulkUpdateCompareTests {
@Autowired
public BulkUpsertUserDAO userDAO;
public int TEST_SIZE = 100_000;
@BeforeEach
void setUp() {
userDAO.truncate();
List<UserVO> insertList = new ArrayList<>(TEST_SIZE);
for (int i = 1; i <= TEST_SIZE; i++) {
insertList.add(new UserVO(String.format("UserVO%05d", i), "Init"));
}
int cnt = userDAO.insertInit(insertList);
Assertions.assertEquals(TEST_SIZE, cnt);
}
@Test
public void when_TempTable() {
// Given
List<UserVO> updateList = createTestData(TEST_SIZE);
// When
double beforeTime = System.currentTimeMillis();
userDAO.bulkUpdateFromTempTable(updateList);
double afterTime = System.currentTimeMillis();
// Then
int updateUserCnt = userDAO.selectUpdateUserCnt();
Assertions.assertEquals(TEST_SIZE, updateUserCnt);
log.info("### run time : {}s", (afterTime-beforeTime) / 1000);
}
@Test
public void when_Upsert() {
// Given
List<UserVO> updateList = createTestData(TEST_SIZE);
// When
double beforeTime = System.currentTimeMillis();
int cnt = userDAO.bulkUpsertUserList(updateList);
double afterTime = System.currentTimeMillis();
// Then: 2 * TEST_SIZE -> select + update
Assertions.assertEquals(2 * TEST_SIZE, cnt);
log.info("### run time : {}s", (afterTime-beforeTime) / 1000);
}
List<UserVO> createTestData(int UPDATE_SIZE) {
List<UserVO> updateList = new ArrayList<>(UPDATE_SIZE);
for (int i = 1; i <= TEST_SIZE; i++) {
updateList.add(new UserVO(String.format("UserVO%05d", i), "Update"));
}
return updateList;
}
}
Result
결과는 아래와 같습니다.
| UPDATE_SIZE | Temporary Table | Upsert |
| 10_000 | 🥇 0.806s | 🥈 1.171s |
| 50_000 | 🥇 3.542s | 🥈 4.333s |
| 100_000 | 🥇 10.112s | 🥈 10.95s |
| 500_000 | 🥇 67.49s | 🥈 96.095s |
Temporary Table이 조금 더 빠른 속도를 보이고 있습니다.
10만건 이상을 UPDATE 하는 것이 아니라면, 둘 중 아무거나 사용해도 괜찮을 듯 합니다.
호기심으로 시작했다가 궁금한게 계속 추가되면서 새벽 3시까지 테스트로 달리고 있네요 🤣
이상으로 Bulk Upsert 방법과 성능에 대해서 다뤘습니다.
오타나 잘못된 내용은 댓글 부탁드립니다.
감사합니다 ☺️
'BACKEND > Database' 카테고리의 다른 글
| Paging Optimization - Covering Index (2) | 2022.08.01 |
|---|---|
| Covering Index, 성능 테스트 (0) | 2022.07.27 |
| Bulk Update, Temporary Table 성능 테스트 - Spring (4) | 2022.07.10 |
| MySQL, DATETIME VS TIMESTAMP (0) | 2022.05.05 |
| MySQL Ngram, 제대로 이해하기 (6) | 2022.04.25 |

Backend Software Engineer
𝐒𝐮𝐧 · 𝙂𝙮𝙚𝙤𝙣𝙜𝙨𝙪𝙣 𝙋𝙖𝙧𝙠