
2022. 4. 17. 22:10ㆍBACKEND/Database
Execution Plan을 읽고 해석할 수 있는 것이 이 포스팅의 목표입니다.
본 포스팅은 사용된 코드나 데이터는 직접 테스트 한 내용으로,
만약 직접 테스트 해보고 싶다면 아래의 내용을 참고해주세요.
Mysql Version: 8.0.26
Test DB: employees
테스트 DB는 해당 링크의 'Example Databases > employee data'에서 다운받으실 수 있습니다.
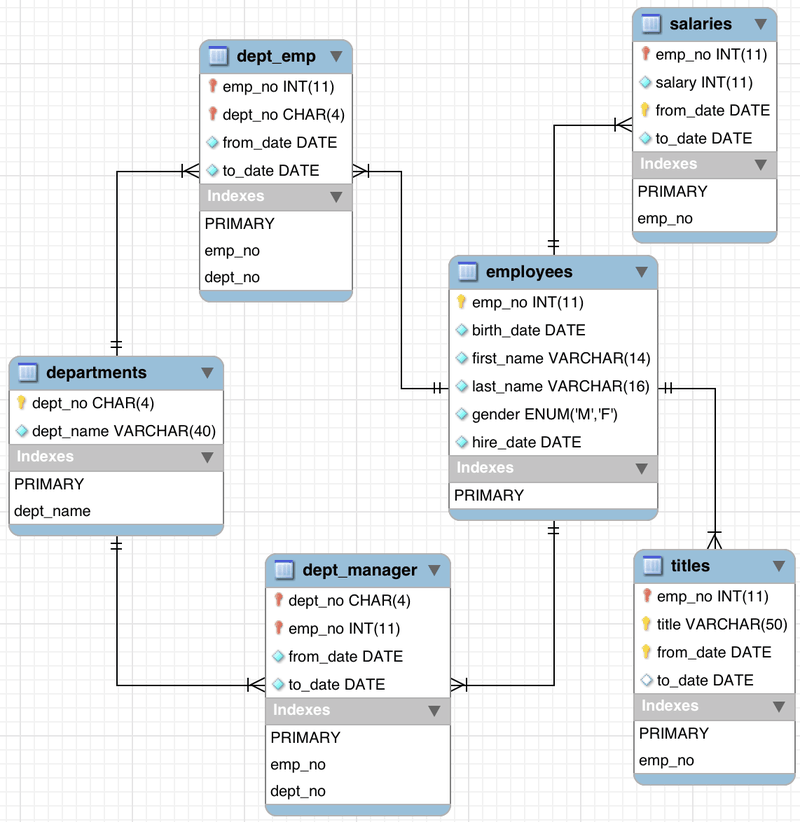
해당 테스트 DB는 아래와 같은 구조로 구성되어 있습니다.
Execution Plan?
실행 계획이란, 말 그대로 SQL 문으로 요청한 데이터를 어떻게 불러올 것인지에 관한 계획, 즉 경로를 의미합니다.
지름길을 사용해 데이터를 빠르게 찾아낼 것인지, 지름길이 있어도 멀리 돌아가서 찾을 것인지 미리 확인할 수 있습니다.
실행 계획을 확인하는 키워드로는 EXPLAIN, DESCRIBE, DESC 가 있는데, 해당 결과는 모두 같습니다.
mysql> DESC SELECT * FROM employees WHERE emp_no BETWEEN 100001 AND 200000;
+----+-------------+-----------+------------+-------+---------------+---------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+---------------+---------+---------+------+-------+----------+-------------+
| 1 | SIMPLE | employees | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 20080 | 100.00 | Using where |
+----+-------------+-----------+------------+-------+---------------+---------+---------+------+-------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
간단한 내용을 실행해본 결과입니다.
필자는 MySQL을 통해 실행한 결과이며, MariaDB에서는 partitions와 filtered 필드가 없습니다.
지금부터 위의 12가지 필드에 대해 하나씩 살펴볼 예정입니다.
많은 내용이기 때문에 외운다기 보다는 필요할 때마다 찾아보며 익히는 것을 추천드립니다.
먼저, 각 필드의 의미를 간단히 살펴보면 아래와 같습니다.
| FILED | DESC |
| id | Select 아이디로 Select를 구분하는 번호 |
| select_type | Select에 대한 타입 |
| table | 참조하는 테이블 |
| type | 조인 혹은 조회 타입 |
| possible_keys | 데이터를 조회할 때 DB에서 사용할 수 있는 인덱스 리스트 |
| key | 실제로 사용할 인덱스 |
| key_len | 실제로 사용할 인덱스의 길이 |
| ref | Key 안의 인덱스와 비교하는 칼럼(상수) |
| rows | 쿼리 실행 시 조사하는 행 수 |
| extra | 추가 정보 |
이제 항목별로 알아보도록 하겠습니다.
📌 id
실행 순서
SQL 문이 수행되는 차례를 ID로 표기한 것으로, 조인 시 동일한 ID가 표시됩니다.
즉, ID가 작을수록 먼저 수행된 것이고, ID가 같으면 조인되었다는 의미가 되죠.
mysql> EXPLAIN SELECT e.emp_no, e.first_name, e.gender, s.salary,
-> (SELECT MAX(dept_no) FROM dept_emp WHERE dept_emp.emp_no = e.emp_no)
-> FROM employees e, salaries s
-> WHERE e.emp_no = s.emp_no AND e.emp_no = 10001;
+----+--------------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+------------------------------+
| 1 | PRIMARY | e | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
| 1 | PRIMARY | s | NULL | ref | PRIMARY | PRIMARY | 4 | const | 17 | 100.00 | NULL |
| 2 | DEPENDENT SUBQUERY | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Select tables optimized away |
+----+--------------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+------------------------------+
3 rows in set, 2 warnings (0.01 sec)
첫 번째와 두 번째로 나온 항목의 id가 같고, 숫자가 가장 작기 때문에 조인되었다는 것을 알 수 있습니다.
이렇게 실행 순서는 위에서 아래 순서대로 표시되며,
위쪽에 출력된 결과일수록(id가 작을수록) 쿼리의 바깥(Outer)부분이거나 먼저 접근한 테이블에 해당됩니다.
📌 select_type
SQL문을 구성하는 SELECT 문의 유형을 출력하는 항목
SELECT문이 단순히 FROM 절에 위치한 것인지, 서브쿼리인지, UNION 절로 묶인 SELECT문인지 등의 정보를 제공합니다.
해당 항목에서 나타날 수 있는 값은 아래와 같습니다.
✔️ SIMPLE : 단순한 SELECT 구문
UNION이나 내부 쿼리가 없는 SELECT 문이라는 걸 의미하는 유형입니다.
말 그대로 단순한 SELECT 구문으로만 작성된 경우를 가리킵니다
mysql> EXPLAIN SELECT emp_no, first_name, gender
-> FROM employees WHERE emp_no = 10001;
+----+-------------+-----------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | employees | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+-----------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
✔️ PRIMARY : 서브쿼리나 UNION 절 내의 가장 바깥쪽 SELECT 문
서브쿼리가 포함된 SQL문이 있을 때 첫 번째 SELECT 문에 해당하는 구문에 표시되는 유형입니다.
즉, 서브쿼리를 감싸는 외부 쿼리이거나, UNION이 포함된 SQL 문에서 첫 번째로 SELECT 키워드가 작성된 구문에 표시됩니다.
mysql> EXPLAIN SELECT e.emp_no, e.first_name, e.gender,
-> (SELECT MAX(dept_no) FROM dept_emp WHERE dept_emp.emp_no = e.emp_no)
-> FROM employees e
-> WHERE e.emp_no = 10001;
+----+--------------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+------------------------------+
| 1 | PRIMARY | e | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
| 2 | DEPENDENT SUBQUERY | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Select tables optimized away |
+----+--------------------+-------+------------+-------+---------------+---------+---------+-------+------+----------+------------------------------+
2 rows in set, 2 warnings (0.01 sec)
✔️ SUBQUERY : 독립적으로 수행되는 서브쿼리
일반적으로 서브쿼리라고하면 여러가지를 이야기하지만
여기서 SUBQUERY라고하는 것은 FROM 절 이외에서 사용되는 서브 쿼리만을 의미합니다.
서브 쿼리는 사용되는 위치와 따라 아래와 같이 각각 다른 이름을 지니고 있습니다.
중첩된 쿼리(Nested Query) : SELECT 되는 칼럼에 사용된 서브 쿼리
서브 쿼리(Sub Query) : WHERE 절에 사용된 서브 쿼리
파생 테이블(Derived) : FROM 절에 사용된 서브 쿼리 (= 인라인 뷰Inline View 또는 서브 셀렉트Sub Select)
mysql> EXPLAIN SELECT
-> (SELECT COUNT(*) FROM dept_emp),
-> (SELECT MAX(salary) FROM salaries);
+----+-------------+----------+------------+-------+---------------+---------+---------+------+---------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+-------+---------------+---------+---------+------+---------+----------+----------------+
| 1 | PRIMARY | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used |
| 3 | SUBQUERY | salaries | NULL | ALL | NULL | NULL | NULL | NULL | 2838426 | 100.00 | NULL |
| 2 | SUBQUERY | dept_emp | NULL | index | NULL | dept_no | 16 | NULL | 331143 | 100.00 | Using index |
+----+-------------+----------+------------+-------+---------------+---------+---------+------+---------+----------+----------------+
3 rows in set, 1 warning (0.00 sec)
✔️ DERIVED : FROM 절에 작성된 서브쿼리
즉, FROM 절의 별도 임시 테이블인 인라인 뷰를 말합니다.
FROM절에 사용된 서브 쿼리로 SELECT 쿼리의 결과로 메모리나 디스크에 임시 테이블을 만드는 경우를 의미합니다.
mysql> EXPLAIN
-> SELECT emp.emp_no, sal.salary
-> FROM employees as emp,
-> (SELECT MAX(salary) as salary
-> FROM salaries
-> WHERE emp_no BETWEEN 10001 AND 20000
-> ) as sal;
+----+-------------+------------+------------+--------+---------------+---------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+---------------+---------+---------+------+--------+----------+-------------+
| 1 | PRIMARY | <derived2> | NULL | system | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
| 1 | PRIMARY | emp | NULL | index | NULL | PRIMARY | 4 | NULL | 299246 | 100.00 | Using index |
| 2 | DERIVED | salaries | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 185516 | 100.00 | Using where |
+----+-------------+------------+------------+--------+---------------+---------+---------+------+--------+----------+-------------+
3 rows in set, 1 warning (0.03 sec)
✔️ UNION : UNION 및 UNION ALL 구문의 첫 번째 SELECT 구문 이후의 SELECT 구문
UNION 및 UNION ALL 구문으로 합쳐진 SELECT 문에서
첫 번째 SELECT 구문을 제외한 이후의 SELECT 구문에 해당한다는 것을 의미합니다.
mysql> EXPLAIN
->
-> SELECT employee1.emp_no, employee1.first_name, employee1.last_name
-> FROM employees employee1
-> WHERE employee1.emp_no = 10001
->
-> UNION ALL
->
-> SELECT employee2.emp_no, employee2.first_name, employee2.last_name
-> FROM employees employee2
-> WHERE employee2.emp_no = 10002;
+----+-------------+-----------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | PRIMARY | employee1 | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
| 2 | UNION | employee2 | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+-----------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
2 rows in set, 1 warning (0.00 sec)
✔️ UNION RESULT : UNION ALL이 아닌 UNION 구문으로 SELECT 절을 결합했을 경우
mysql> EXPLAIN
-> SELECT all_emp.*
-> FROM (
-> SELECT MAX(hire_date) FROM employees emp WHERE gender = 'M'
-> UNION
-> SELECT MIN(hire_date) FROM employees emp WHERE gender = 'M'
-> ) as all_emp;
+----+--------------+------------+------------+------+---------------+------+---------+------+--------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------+------------+------------+------+---------------+------+---------+------+--------+----------+-----------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 100.00 | NULL |
| 2 | DERIVED | emp | NULL | ALL | NULL | NULL | NULL | NULL | 299246 | 50.00 | Using where |
| 3 | UNION | emp | NULL | ALL | NULL | NULL | NULL | NULL | 299246 | 50.00 | Using where |
| NULL | UNION RESULT | <union2,3> | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary |
+----+--------------+------------+------------+------+---------------+------+---------+------+--------+----------+-----------------+
4 rows in set, 1 warning (0.00 sec)
✔️ DEPENDENT SUBQUERY : FROM절 이외의 서브쿼리가 메인 테이블의 영향을 받는 경우
서브쿼리가 메인 테이블의 영향을 받는 경우 FROM절 이외에 사용된 서브 쿼리가 바깥쪽 SELECT 쿼리에서 정의된 컬럼을 사용하는 경우에 해당 서브 쿼리에 표기됩니다.
mysql> EXPLAIN
-> SELECT manager.dept_no, (
-> SELECT emp.first_name
-> FROM employees emp
-> WHERE gender = 'F' AND emp.emp_no = manager.emp_no
-> ) as name
-> FROM dept_manager as manager;
+----+--------------------+---------+------------+--------+---------------+---------+---------+--------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------------+---------+------------+--------+---------------+---------+---------+--------------------------+------+----------+-------------+
| 1 | PRIMARY | manager | NULL | index | NULL | dept_no | 16 | NULL | 24 | 100.00 | Using index |
| 2 | DEPENDENT SUBQUERY | emp | NULL | eq_ref | PRIMARY | PRIMARY | 4 | employees.manager.emp_no | 1 | 50.00 | Using where |
+----+--------------------+---------+------------+--------+---------------+---------+---------+--------------------------+------+----------+-------------+
2 rows in set, 2 warnings (0.00 sec)
✔️ DEPENDENT UNION : UNION 또는 UNION ALL을 사용하는 서브쿼리가 메인 테이블의 영향을 받는 경우
UNION 또는 UNION ALL을 사용하는 서브쿼리가 메인 테이블의 영향을 받는 경우로,
UNION으로 연결된 단위 쿼리들 중에서 처음으로 작성한 단위 쿼리에 해당되는 경우에 해당됩니다.
즉, UNION으로 연결되는 첫 번째 단위 쿼리가 독립적으로 수행하지 못하고 메인 테이블로부터 값을 하나씩 공급받는 구조이므로 성능상 불리하기 때문에, 튜닝 대상의 SQL문이 됩니다.
UNION을 사용한 경우 중에서도 UNION으로 결합된 쿼리가 외부 쿼리에 의해 영향을 받는 것을 표기합니다.
내부 쿼리가 외부의 값을 참조해서 처리될 때 DEPENDENT 키워드가 추가됩니다.
mysql> EXPLAIN
-> SELECT manager.dept_no, (
-> SELECT emp.first_name FROM employees emp WHERE gender = 'F' AND emp.emp_no = manager.emp_no
-> UNION
-> SELECT emp.first_name FROM employees emp WHERE gender = 'M' AND emp.emp_no = manager.emp_no
-> ) as name
-> FROM dept_manager as manager;
+----+--------------------+------------+------------+--------+---------------+---------+---------+--------------------------+------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------------+------------+------------+--------+---------------+---------+---------+--------------------------+------+----------+-----------------+
| 1 | PRIMARY | manager | NULL | index | NULL | dept_no | 16 | NULL | 24 | 100.00 | Using index |
| 2 | DEPENDENT SUBQUERY | emp | NULL | eq_ref | PRIMARY | PRIMARY | 4 | employees.manager.emp_no | 1 | 50.00 | Using where |
| 3 | DEPENDENT UNION | emp | NULL | eq_ref | PRIMARY | PRIMARY | 4 | employees.manager.emp_no | 1 | 50.00 | Using where |
| NULL | UNION RESULT | <union2,3> | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary |
+----+--------------------+------------+------------+--------+---------------+---------+---------+--------------------------+------+----------+-----------------+
4 rows in set, 3 warnings (0.00 sec)
✔️ UNCACHABLE SUBQUERY : 메모리에 상주하여 재활용되어야 할 서브쿼리가 재사용되지 못했을 경우
👉🏻 해당 서브쿼리 안에 사용자 정의 함수나 사용자 변수가 포함되는 경우
👉🏻 RAND(), UUID() 함수 등을 사용하여 매번 조회 시마다 결과가 달라지는 경우
메모리에 상주하여 재활용되어야 할 서브쿼리가 재사용되지 못했을 때 출력되는 유형입니다.
SUBQUERY, DEPENDENT SUBQUERY는 서브 쿼리 결과를 캐시할 수 있는데 특정 조건때문에 캐시를 이용할 수 없을 때 표기됩니다.
사용자 변수가 서브 쿼리에 들어갔다거나 UUID(), RAND() 같이 결과값이 호출할 때마다 변경되는 함수가 서브 쿼리에 들어갔다거나 NOT-DETERMINISTIC 속성의 스토어드 함수가 서브 쿼리에 들어간 경우가 이에 해당하는 특정 조건입니다.
mysql> EXPLAIN SELECT * FROM employees
-> WHERE emp_no = (SELECT ROUND(RAND()*1000000));
+----+----------------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+----------------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
| 1 | PRIMARY | employees | NULL | ALL | NULL | NULL | NULL | NULL | 299246 | 100.00 | Using where |
| 2 | UNCACHEABLE SUBQUERY | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used |
+----+----------------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
2 rows in set, 1 warning (0.00 sec)
✔️ MATERIALIZED : IN 절 구문에 연결된 서브쿼리가 임시 테이블을 생성한 뒤, 조인이나 가공 작업을 수행할 때 출력되는 유형
즉, IN절의 서브쿼리를 임시 테이블로 만들어서 조인 작업을 수행하는 것입니다.
FROM 절이나 IN (subquery) 형태의 쿼리에 사용된 서브 쿼리를 최적화할 때 사용됩니다.
이 경우에 보통 서브 쿼리보다 외부 쿼리의 테이블을 먼저 읽어서 비효율적으로 실행되기 마련인데 이렇게 실행하지 않고 서브 쿼리의 내용을 임시테이블로 구체화한 후 외부 테이블과 조인하는 형태로 최적화됩니다.
이 때, 서브 쿼리가 먼저 구체화되었다는 것을 표기할 때 사용됩니다.
뭔가 효율적으로 개선된 듯하지만 결국 임시테이블을 사용하므로 엄청 효율적이지는 않습니다.
mysql> EXPLAIN SELECT * FROM employees
-> WHERE emp_no IN (SELECT emp_no FROM salaries WHERE from_date > '2020-01-01' AND salary > 200000);
+----+--------------+-------------+------------+--------+---------------+------------+---------+----------------------------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------+-------------+------------+--------+---------------+------------+---------+----------------------------+---------+----------+-------------+
| 1 | SIMPLE | employees | NULL | ALL | PRIMARY | NULL | NULL | NULL | 299246 | 100.00 | Using where |
| 1 | SIMPLE | <subquery2> | NULL | eq_ref | <auto_key> | <auto_key> | 4 | employees.employees.emp_no | 1 | 100.00 | NULL |
| 2 | MATERIALIZED | salaries | NULL | ALL | PRIMARY | NULL | NULL | NULL | 2838426 | 11.11 | Using where |
+----+--------------+-------------+------------+--------+---------------+------------+---------+----------------------------+---------+----------+-------------+
3 rows in set, 1 warning (0.00 sec)
📌 type
테이블의 데이터를 어떻게 찾을지에 관한 정보를 제공하는 항목
테이블을 처음부터 끝까지 전부 확인할지 아니면 인덱스를 통해 바로 데이터를 찾아갈지 등을 해석할 수 있습니다.
이제부터 타입으로 올 수 있는 값을 다룰 텐데요.
위에서 아래로 내려올수록 좋지 않습니다.
즉, 가장 위에 소개된 system과 가까울수록 가장 좋은 성능을, 가장 아래 all과 가까울 수록 나쁜 성능을 뜻합니다.
✔️ system : 테이블에 데이터가 없거나 한 개만 있는 경우. 성능상 최상의 type
✔️ const : 조회되는 데이터가 단 1건일 때 출력되는 유형
const 타입은 성능상 유리한 방식입니다.
고유 인덱스나 기본 키를 사용하여 단 1건의 데이터에만 접근하면 되므로 속도나 리소스 측면에서 지향해야 할 타입
✔️ eq_ref : 조인 시 Primary Key 혹은 Unique Key로 매칭
조인이 수행될 때 드리븐 테이블의 데이터에 접근하며,
고유 인덱스 또는 기본 키로 단 1건의 데이터를 조회하는 방식입니다.
mysql> EXPLAIN
-> SELECT dept_emp.emp_no, dept.dept_no, dept.dept_name
-> FROM dept_emp,
-> departments as dept
-> WHERE dept_emp.dept_no = dept.dept_no
-> AND dept_emp.emp_no BETWEEN 10001 AND 10010;
+----+-------------+----------+------------+--------+-----------------+---------+---------+----------------------------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+--------+-----------------+---------+---------+----------------------------+------+----------+--------------------------+
| 1 | SIMPLE | dept_emp | NULL | range | PRIMARY,dept_no | PRIMARY | 4 | NULL | 11 | 100.00 | Using where; Using index |
| 1 | SIMPLE | dept | NULL | eq_ref | PRIMARY | PRIMARY | 16 | employees.dept_emp.dept_no | **1** | 100.00 | NULL |
+----+-------------+----------+------------+--------+-----------------+---------+---------+----------------------------+------+----------+--------------------------+
2 rows in set, 1 warning (0.01 sec)
rows(SQL 문의 결과 row 수 예측 항목) 가 1인 것을 확인할 수 있습니다.
드라이빙 테이블과의 조인 키가 드리븐 테이블에 유일하므로 조인이 수행될 때 성능상 가장 유리한 경우입니다.
✔️ ref : 조인 시 Primary Key 혹은 Unique Key가 아닌 Key로 매칭
조인이 수행될 때 드리븐 테이블의 데이터에 접근하며, 고유 인덱스 또는 기본 키로 2개 이상의 데이터를 조회하는 방식입니다.
앞에서 설명한 eq_ref 유형과 유사한 방식으로, 조인을 수행할 때 드리븐 테이블의 데이터 접근 범위가 2개 이상일 경우에 해당합니다.
mysql> EXPLAIN
-> SELECT emp.emp_no, sal.salary
-> FROM employees as emp,
-> salaries as sal
-> WHERE emp.emp_no = sal.emp_no;
+----+-------------+-------+------------+-------+---------------+---------+---------+----------------------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+----------------------+--------+----------+-------------+
| 1 | SIMPLE | emp | NULL | index | PRIMARY | PRIMARY | 4 | NULL | 299246 | 100.00 | Using index |
| 1 | SIMPLE | sal | NULL | ref | PRIMARY | PRIMARY | 4 | employees.emp.emp_no | 9 | 100.00 | NULL |
+----+-------------+-------+------------+-------+---------------+---------+---------+----------------------+--------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
✔️ ref_or_null : ref 유형과 비슷하지만 IS NULL 구문에 대해 인덱스를 활용하도록 최적화된 방식
테이블 검색 시 NULL 데이터양이 적다면 효율적, 하지만 많다면 SQL 튜닝의 대상이 됩니다.
MySQL과 MariaDB는 NULL에 대해 인덱스를 활용하여 검색할 수 있으며, 이때 NULL은 가장 앞쪽에 정렬됩니다.
✔️ index_merge: 두 개의 인덱스가 병합되어 검색이 이뤄지는 경우
즉, 특정 테이블에 생성된 두 개 이상의 인덱스가 병합되어 동시에 적용됩니다.
mysql> CREATE INDEX IDX_hire_date ON employees (hire_date);
Query OK, 0 rows affected (0.36 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show index from employees;
+-----------+------------+---------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+-----------+------------+---------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| employees | 0 | PRIMARY | 1 | emp_no | A | 299246 | NULL | NULL | | BTREE | | | YES | NULL |
| employees | 1 | IDX_hire_date | 1 | hire_date | A | 5093 | NULL | NULL | | BTREE | | | YES | NULL |
+-----------+------------+---------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
2 rows in set (0.00 sec)
mysql> EXPLAIN SELECT * FROM employees WHERE emp_no BETWEEN 10001 AND 100000 AND hire_date = '1985-11-21';
+----+-------------+-----------+------------+-------------+-----------------------+-----------------------+---------+------+------+----------+-----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------------+-----------------------+-----------------------+---------+------+------+----------+-----------------------------------------------------+
| 1 | SIMPLE | employees | NULL | index_merge | PRIMARY,IDX_hire_date | IDX_hire_date,PRIMARY | 7,4 | NULL | 15 | 100.00 | Using intersect(IDX_hire_date,PRIMARY); Using where |
+----+-------------+-----------+------------+-------------+-----------------------+-----------------------+---------+------+------+----------+-----------------------------------------------------+
1 row in set, 1 warning (0.00 sec)
✔️ unique_subquery: 다음과 같이 IN절 안의 서브쿼리에서 Primary Key가 오는 특수한 경우
SELECT * FROM tab01
WHERE col01 IN (
SELECT Primary_Key FROM tab01
)
✔️ range : 테이블 내의 연속된 데이터 범위를 조회하는 유형
=, <>, >, >=, <=, IS NULL, <=>, BETWEEN 또는 IN 연산을 통해 범위 스캔을 수행하는 방식입니다.
주어진 데이터 범위 내에서 행 단위로 스캔하지만, 스캔할 범위가 넓으면 성능 저하의 요인이 될 수 있습니다.
✔️ index: 인덱스를 처음부터 끝까지 찾아서 검색하는 경우 (= 인덱스 풀스캔)
일반적으로 인덱스 풀스캔이라고 부르며, 물리적인 인덱스 블록block을 처음부터 끝까지 훑는 방식을 말합니다.
데이터를 스캔하는 대상이 인덱스라는 점이 다를 뿐, 이어서 설명할 ALL 유형(테이블 풀 스캔 방식)과 유사합니다.
mysql> EXPLAIN SELECT emp_no FROM titles WHERE title='Staff';
+----+-------------+--------+------------+-------+---------------+---------+---------+------+--------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+---------+---------+------+--------+----------+--------------------------+
| 1 | SIMPLE | titles | NULL | index | PRIMARY | PRIMARY | 209 | NULL | 442486 | 10.00 | Using where; Using index |
+----+-------------+--------+------------+-------+---------------+---------+---------+------+--------+----------+--------------------------+
1 row in set, 1 warning (0.00 sec)
✔️ all: 테이블을 처음부터 끝까지 검색하는 경우 (= 테이블 풀스캔)
일반적으로 테이블 풀스캔이라고 합니다.
ALL 유형일 때는 인덱스를 새로 추가하거나 기존 인덱스를 변경하여 인덱스를 활용하는 방식으로 SQL 튜닝을 할 수 있지만, 전체 테이블 중 10~20% 이상 분량의 데이터를 조회할 때는 ALL 유형이 오히려 성능상 유리할 수 있습니다.
활용할 수 있는 인덱스가 없거나, 인덱스를 활용하는 게 오히려 비효율적이라고 옵티마이저가 판단했을 때 선택됩니다.
📌 possible_keys
옵티마이저가 SQL문을 최적화하고자 사용할 수 있는 인덱스 목록을 출력
다만 실제 사용한 인덱스가 아닌, 사용할 수 있는 후보군의 기본 키와 인덱스 목록만 보여주므로 SQL 튜닝의 효용성은 없습니다.
📌 key
옵티마이저가 SQL문을 최적화하고자 사용한 기본 키 (PK) 또는 인덱스명을 의미
어느 인덱스로 데이터를 검색했는지 확인할 수 있으므로, 비효율적인 인덱스를 사용했거나 인덱스 자체를 사용하지 않았다면 SQL 튜닝의 대상이 됩니다.
EXAMPLE CODE
mysql> EXPLAIN
-> SELECT emp_no
-> FROM titles
-> WHERE title = "Engineer";
+----+-------------+--------+------------+-------+---------------+---------+---------+------+--------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+---------+---------+------+--------+----------+--------------------------+
| 1 | SIMPLE | titles | NULL | index | PRIMARY | PRIMARY | 209 | NULL | 442486 | 10.00 | Using where; Using index |
+----+-------------+--------+------------+-------+---------------+---------+---------+------+--------+----------+--------------------------+
1 row in set, 1 warning (0.01 sec)
mysql> EXPLAIN SELECT emp_no FROM employees WHERE first_name = 'Parto';
+----+-------------+-----------+------------+------+----------------+----------------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+----------------+----------------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | employees | NULL | ref | IDX_first_name | IDX_first_name | 58 | const | 228 | 100.00 | Using index |
+----+-------------+-----------+------------+------+----------------+----------------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
📌 key_len
사용한 인덱스의 바이트bytes 수
인덱스를 사용할 때는 인덱스 전체를 사용하거나 일부 인덱스만 사용합니다.
key_len은 이렇게 사용한 인덱스의 바이트bytes 수를 의미합니다.
📌 ref
reference의 약자로, 테이블 조인을 수행할 때 어떤 조건으로 해당 테이블에 엑세스되었는지를 알려주는 정보
EXAMPLE CODE
mysql> EXPLAIN SELECT employees.emp_no, titles.title FROM employees, titles WHERE employees.emp_no=titles.emp_no AND employees.emp_no BETWEEN 10000 AND 10002;
+----+-------------+-----------+------------+--------+---------------+---------+---------+-------------------------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+--------+---------------+---------+---------+-------------------------+------+----------+--------------------------+
| 1 | SIMPLE | titles | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 2 | 100.00 | Using where; Using index |
| 1 | SIMPLE | employees | NULL | eq_ref | PRIMARY | PRIMARY | 4 | employees.titles.emp_no | 1 | 100.00 | Using index |
+----+-------------+-----------+------------+--------+---------------+---------+---------+-------------------------+------+----------+--------------------------+
2 rows in set, 1 warning (0.00 sec)
📌 rows
SQL 문을 수행하고자 접근하는 데이터의 모든 행row 수를 나타내는 예측 항목
즉, 디스크에서 데이터 파일을 읽고 메모리에서 처리해야 할 행 수를 예상하는 값이고,
수시로 변동되는 MySQL의 통계정보를 참고하여 산출하는 값이므로 수치가 정확하진 않습니다.
또한, 최종 출력될 행 수가 아니라는 점에 유의해야 합니다.
SQL문의 최종 결과 건수와 비교해 rows수가 크게 차이 날 때는
불필요하게 MySQL 엔진까지 데이터를 많이 가져왔다는 뜻이므로 SQL 튜닝의 대상이 될 수 있습니다.
📌 filtered
어느 비율로 데이터를 제거했는지를 의미하는 항목
SQL문을 통해 DB엔진으로 가져온 데이터 대상으로 필터 조건에 따라,
어느 정도의 비율로 데이터를 제거했는지를 의미하는 항목을 나타냅니다.
예를 들어 DB 엔진으로 100건의 데이터를 가져왔다고 가정한다면,
이후 WHERE 절의 emp_no BETWEEN 1 AND 10 조건으로 100건의 데이터가 10건로 필터링됩니다.
이처럼 100건에서 10건으로 필터링되었으므로 filtered에는 10(%)이라는 정보가 출력됩니다.
📌 extra
SQL문을 어떻게 수행할 것인지에 관한 추가 정보를 보여주는 항목
부가적인 정보들은 세미콜론(;)으로 구분하여 여러가지 정보를 나열할 수 있으며 30여가지 항목으로 정리할 수 있습니다.
자세한 내용은 해당 링크에서 확인해보실 수 있습니다.
Using index ←→ Using filesort, Using temporary
그럼 지금까지 Execution Plan에 대한 항목들을 살펴보았습니다.
오타나 잘못된 내용을 댓글로 남겨주세요!
감사합니다 ☺️
'BACKEND > Database' 카테고리의 다른 글
| MySQL Ngram, 제대로 이해하기 (6) | 2022.04.25 |
|---|---|
| MySQL FullText Search, 제대로 이해하기 (3) | 2022.04.24 |
| Bulk Insert, 성능 테스트 (6) | 2022.03.05 |
| Database Index, 제대로 알아보기 (5) | 2021.07.30 |
| SQL, Window Function (0) | 2020.11.29 |

Backend Software Engineer
𝐒𝐮𝐧 · 𝙂𝙮𝙚𝙤𝙣𝙜𝙨𝙪𝙣 𝙋𝙖𝙧𝙠