JDK 17 ~ 21 Release, 제대로 이해하기
본 포스팅은 openJDK 17 부터 21 까지의 변경 사항을 확인하고, JDK 21을 사용할 때 개발자로서 알아두면 좋을 내용을 학습합니다.
Previous Series:
📌 JDK 11 ~ 17 Release, 제대로 이해하기
👉🏻 JDK 17 ~ 21 Release, 제대로 이해하기 (current)
지난 9월 19일 (2023년), Open JDK LTS인 JDK 21 가 프로덕션에 적용 목적의 General Availability로 릴리즈되었습니다.
General Availability: Final release, ready for production use
JDK 21에서는 아래 15개의 새로운 기능들을 발표했는데요.
크게 네 개의 카테고리로 분류해보면 아래와 같습니다.
Core Java Library
JEP 431: Sequenced Collections
JEP 442: Foreign Function & Memory API (Third Preview)
JEP 444: Virtual Threads
JEP 446: Scoped Values (Preview)
JEP 448: Vector API (Sixth Incubator)
JEP 453: Structured Concurrency (Preview)
Java Language Specification:
JEP 430: String Templates (Preview)
JEP 440: Record Patterns
JEP 441: Pattern Matching for switch
JEP 443: Unnamed Patterns and Variables (Preview)
JEP 445: Unnamed Classes and Instance Main Methods (Preview)
HotSpot:
JEP 439: Generational ZGC
JEP 449: Deprecate the Windows 32-bit x86 Port for Removal
JEP 451: Prepare to Disallow the Dynamic Loading of Agents
Security Library:
JEP 452: Key Encapsulation Mechanism API
이 중, 본 포스팅에서는 아래 내용과 함께, 두 가지의 수정된 버그 사항을 확인합니다.
- Virtual Threads
- Record Patterns
Sequenced Collections
📑 JEP 431: Sequenced Collections
JDK 21 버전에서 SequencedCollection Interface가 새로 정의되었습니다.
Sequence 가 요소들을 특정한 순서로 배열한다는 의미를 갖고 있으며,
Sequenced Collection는 서로 연쇄된 요소들을 갖는 Collection 을 의미합니다.
✔️ History
Sequenced Collection가 등장한 이유는 Open JDK의 공식 문서에 있는 Issue 8280836 를 살펴보면,
결론적으로, 특정 순서를 갖는 collection을 나타내는 정해진 형식이 없다는 것입니다.
일련의 순서를 갖는다는 동일한 특성을 갖는 collection 임에도 불구하고
이를 사용하는 연산들은 아래 표와 같이 제각각이라 일정 형식이 반복되기도, 많은 불만을 일으키기도 했습니다.
| First element | Last element | |
| List | list.get(0) | list.get(list.size() - 1) |
| Deque | deque.getFirst() | deque.getLast() |
| SortedSet | sortedSet.first() | sortedSet.last() |
| LinkedHashSet | linkedHashSet.iterator().next() | // missing |
실제로, List와 Deque는 둘 다 특정된 순서를 갖지만 일반화된 supertype 없이 Collection을 super type으로 갖습니다.
Set은 이런 순서를 특정짓지 않는데 동일하게 Collection을 확장합니다.
그 하위의 HashSet 또한 순서가 필요없죠.
하지만, SortedSet이나 LinkedHashSet 은 순서가 필요합니다.
이제, 특정 순서를 가진 특별한 Collection 만을 위한 API가 필요하다는 것을 이해할 수 있습니다.
그렇다고 해서, 기존의 Collection이나 List를 변경하고자 하니,
Collecion은 너무 범용적이고 List는 너무 구체화된 클래스입니다.
이런 이유로, Sequenced Collection 가 등장하게 됩니다.
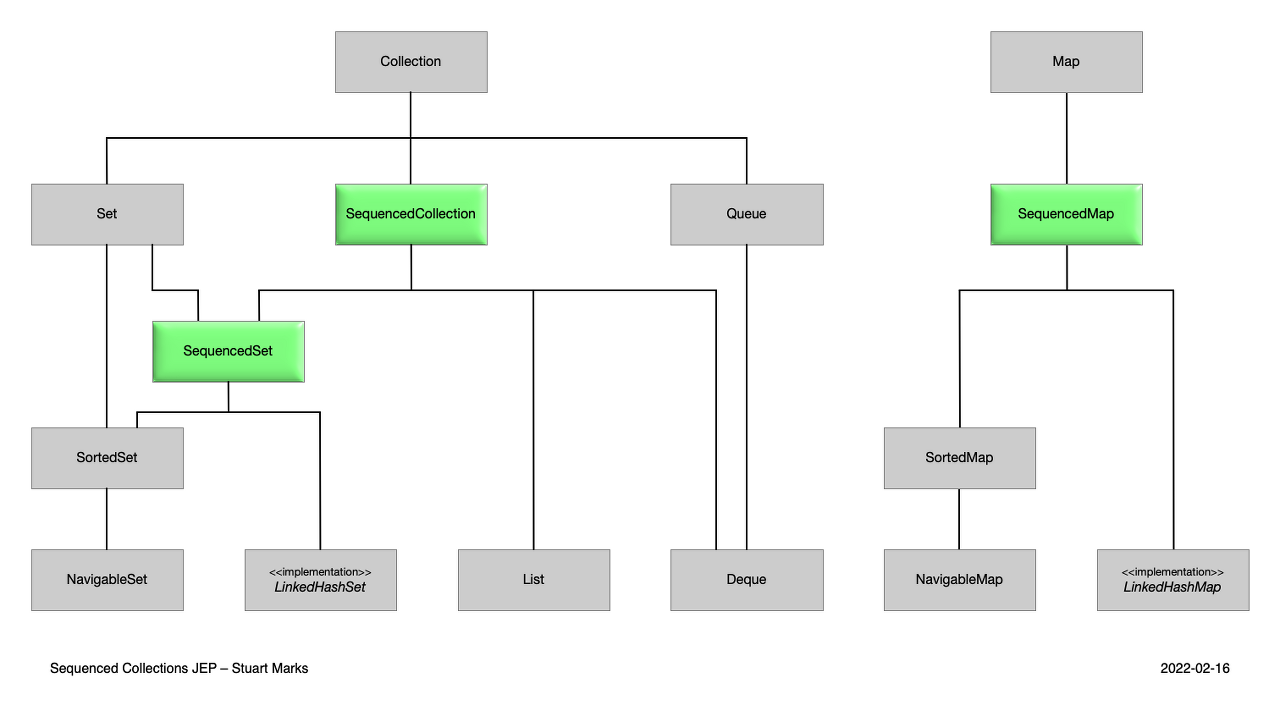
위와 같이 SequencedCollection와 SequencedSet, SequencedMap을 Interface로 추가하여 개조된 구조를 확인할 수 있습니다.
✔️ Sequenced Collection?
Sequenced Collection 는 아래와 같은 API를 가지는 Interface입니다.

Sequenced Collection 는 첫 번째와 마지막 요소를 통해 접근하며,
Collection 연산을 사용할 때 처음뿐만 아니라 끝에서도 처리를 진행할 수 있습니다.
즉, 처음부터 끝의 순서로 차례대로 처리하거나 forward, 반대 순서 reverse 로 처리할 수 있습니다.
중간 요소들은 바로 이 전의 요소 predecessors 와 바로 다음 요소 successors 를 가리키고 있습니다.
실제, 아래와 같은 방식으로 첫 번째, 마지막 요소에 접근합니다.
새로운 reversed() 메소드는 원래 순서였던 collection을 반대 순서로 보이도록 합니다.
시간이 된다면, 한 번 코드를 살펴 보는 것도 좋을 것 같은데요.
List interface에 default method 로 구현된 reversed() 메소드를 확인해보면 ReverseOrderListView를 생성하는 것을 확인할 수 있습니다.
ReverseOrderListView.of()의 두 번째 인자는 새로 생성할 리스트의 변경 가능 여부를 나타내는데,
기본이 true (modifiable=true) 임을 알 수 있습니다.
public interface List<E> extends SequencedCollection<E> {
// ...
default List<E> reversed() {
return ReverseOrderListView.of(this, true); // we must assume it's modifiable
}
}
✔️ Caution
기존의 시스템을 JDK 21로 업데이트할 때 주의해서 살펴볼 점이 있습니다.
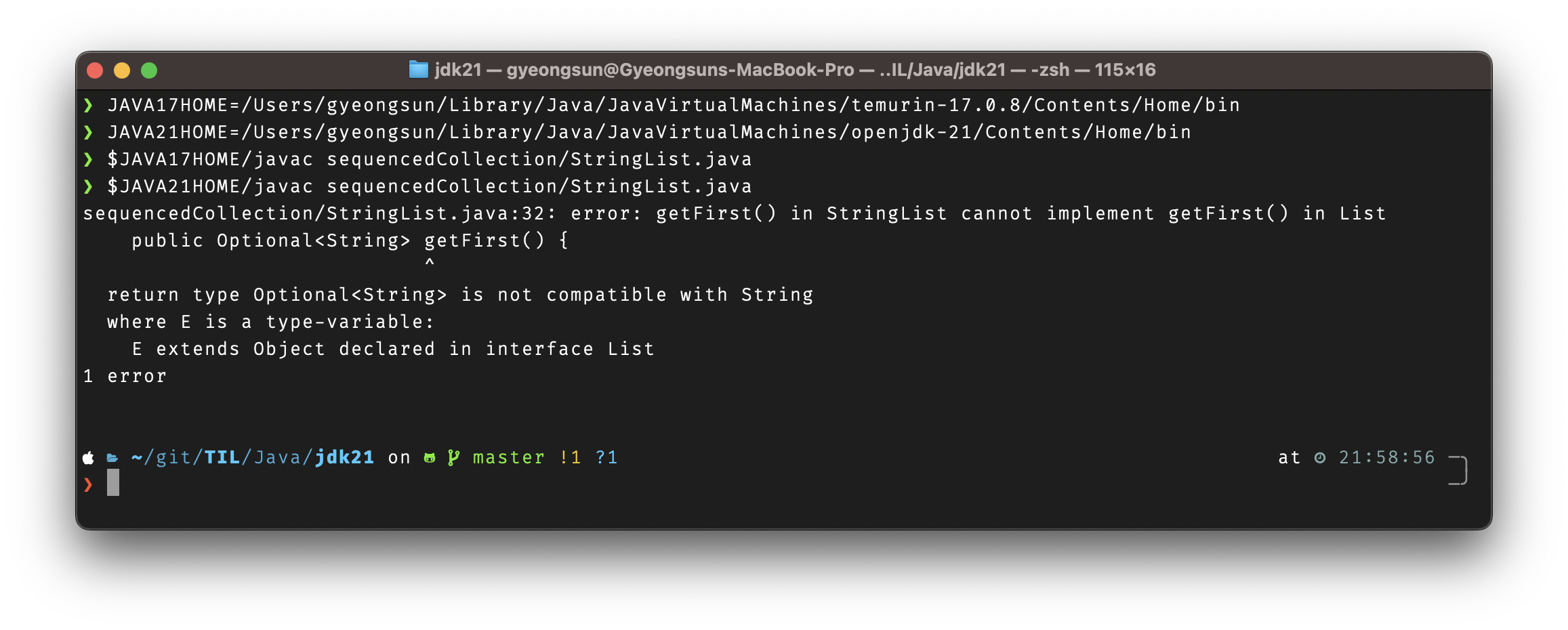
만약, JDK 21 이전에 List를 확장한 클래스에 getFirst() 라는 이름의 메소드를 정의해서 사용하고 있을 경우,
JDK 21에서는 overload method가 되어 컴파일 오류가 발생합니다.
public class StringList extends AbstractList<String> implements List<String> {
/* [...] */
// ✅ up to Java 20: compiles successfully
// ❌ since Java 21: error
public Optional<String> getFirst() {
return size() == 0 ? Optional.empty() : Optional.of(get(0));
}
}
실제로 위의 StringList 를 JDK 17 과 JDK 21을 사용해서 compile 하려고 시도하면,
아래와 같이 JDK 21에서만 오류가 발생하게 됩니다.
Virtual Threads
Virtual Thread가 많은 주목 속에 JDK 21에서 정식 적용 되었습니다.
JDK 19 - JEP 425: Virtual Threads (Preview)
JDK 20 - JEP 436: Virtual Threads (Second Preview)
Mutli-thread 기반인 Java는 여러 실행이 한 번에 일어나기 때문에,
Thread는 Java의 동시성 단위로 볼 수 있으며, 다른 스레드와 거의 독립적으로 동시에 실행됩니다.
Virtual Thread는 매번 실행되는 바로 이 Thread를 경량화하여 처리량을 높이기 위한 기술입니다.
✔️ Problems: Platform Thread
JDK는 기본적으로 Plarform Thread 라고도 불리는 Java Thread 와 OS Thread 가 일대일 관계로 동작합니다.

이 말은 Thread 가 IO 연산이 완료될 때까지 대기할 때까지,
Thread의 근간이 되는 OS Thread는 사용되지 않는 상태인 Block 상태로 대기한다는 의미입니다.
이를 이해하기 위해, 일반적인 Java Thread가 어떻게 동작하는지 먼저 살펴보겠습니다.
#1. Thread가 Thread Pool 에 생성
#2. Thread가 새로운 요청을 위해 Pool에서 대기
#3. 새 요청이 오면 스레드는 요청을 수신하고, 이 요청을 처리하기 위한 데이터베이스를 호출
#4. Thread가 데이터베이스로 부터 응답이 오기까지 대기
#5. 데이터베이스로 부터 응답이 오면 해당 Thread가 이를 처리하고, 사용자에게 응답을 반환
#6. Thread는 Thread Pool로 반환
Application이 종료되기 전까지 1 단계부터 6 단계가 반복됩니다.
위의 처리 과정을 살펴보면, 사실상 Thread가 실행되는 구간은 3 번째와 5번째가 전부입니다.
나머지는 모두 대기하는 단계죠.
OS Thread 의 사용 가능 여부에 의존해서 Application이 한계를 갖기 때문에,
Java 생태계의 확장성의 측면에서 큰 문제가 되어왔습니다.
#1. Async Programming
Thread 가 Block 되는 동안 비효율적으로 사용되는 자원 문제를 해결하기 위해,
비동기 Asynchronous 사용을 위해 Future를 사용하는 등의 시도를 해왔습니다.
비동기 프로그래밍이 Thread 문제를 극복하기 위한 방식이 될 수 있겠지만,
비동기 프로그래밍을 작성하는 과정이 상당히 복잡하고 어렵습니다.
또 하나의 큰 문제는 디버깅이 어렵다는 것입니다.
들어오는 요청이 여러 스레드에 의해 처리될 수 있기 때문에
Debugging, Logging, Stack Trace의 분석 등에 어려움을 겪곤 합니다.
#2. Expensive Creation of Threads
Java Thread는 새로 생성과 유지 비용이 비쌉니다.
Thread 메모리를 할당하고, Thread 스택을 초기화한 후, OS Thread를 등록하기 위해 OS 호출을 하는 등
많은 무거운 작업이 필요하기 때문에 비용이 많이 듭니다.
때문에 Thread가 필요할 때마다 스레드를 새로 만들기보다는, Thread를 미리 생성하고 Thread Pool에 저장합니다.
하지만 OS Thread가 제한적이고 Java Thread를 만들 때의 비용을 고려해야 해서
애플리케이션을 안전하게 실행하려면 제한된 스레드 풀이 필요합니다.
#3. Expensive Context Switching
마지막으로, OS Thread 레벨의 Context Switching으로, 많은 CPU 사이클을 수반하여 큰 비용이 듭니다.
Context Switching 발생 시, OS Thread가 하나의 Java Thread에서 다른 Java Thread로 전환하려면,
OS는 로컬 데이터와 메모리 포인터를 현재 Thread에 저장하고, 새로운 Java Thread에 대한 포인터를 로드해야 합니다.
이를 위해서는 OS가 Thread를 일시 중지하고, 스택을 저장하고, 새로운 Thread를 할당하는 일을 처리하는데,
Thread 스택을 로드하고 언로딩해야 하기 때문에 비용이 많이 듭니다.
이러한 문제를 해결하기 위해, Project Loom과 Virtual Thread 이 등장했습니다.
✔️ Virtual Threads
자바의 Virtual Thread는 Virtual Memory와 유사해서 그 이름을 가져왔습니다.
Virtual Thread가 가상 메모리가 동작하는 방식과 유사하게,
거의 무한의 스레드를 사용할 수 있다는 착각illusion을 하도록 의도하기 때문입니다.
가상 스레드는 시스템에 최소한의 오버헤드를 가하기 때문에 한 애플리케이션에 수천 개의 스레드를 가질 수 있습니다.
모든 가상 스레드는 작업을 수행하기 위해 OS thread가 필요하지만,
리소스를 위한 대기 상태동안 Java thread 처럼 OS thread를 붙잡고 있지는 않습니다.
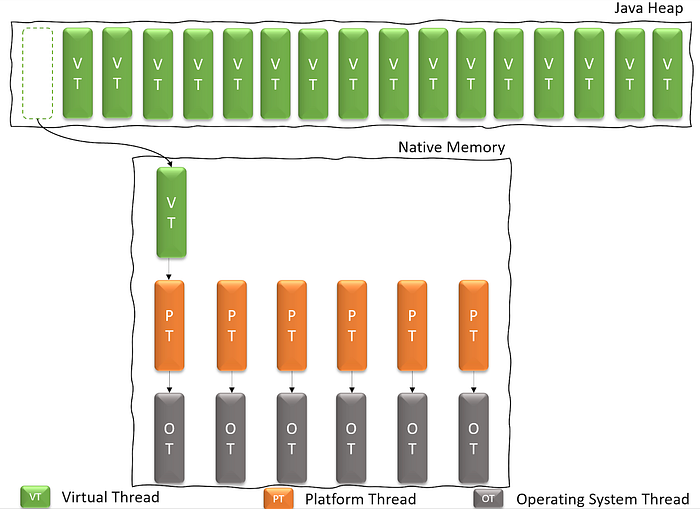
가상 스레드가 I/O를 위해 대기할 수 있는데,
이 때, 사용중이던 Java thread는 풀어줘서 다른 Virtual Thread가 사용하여 다른 일을 할 수 있게 합니다.
또, I/O 작업이 완료되면 이전 작업을 이어서 처리합니다.
Cheap Context Switching
자바에서 Context Switching은 스레드 스택이 발생할 때마다 저장하고 로드해야 하기 때문에 비용이 매우 많이 들었었는데요.
Virtual Thread는 JVM의 통제 하에 있기 때문에 Thread stack은 Stack에 저장되지 않고 힙 메모리에 저장됩니다.
활성 중인 Virtual Thread에 Thread stck을 할당하는 것이 훨씬 저렴해진다는 것을 의미합니다.
Virtual Thread의 데이터 스택을 캐리어에 할당할 때 "carrier" Thread stack에 로드하는 과정을 마운팅 mounting 이라고 하며,
내리는 과정을 언마운팅 unmounting 이라고 합니다.
✔️ Motivation
Virtual thread를 사용하기 위해 새로운 개념을 따로 학습할 필요는 없습니다.
다만, 기존에 사용하던 고비용 Java Thread를 효율적으로 사용하려고 작성하던 코드 습관들을 버릴 필요는 있습니다.
Virtual Thread 의 개발 방향성을 이해하는 것도 참고로 알아두시면 좋을 텐데요.
JEP 444의 Motivation 섹션을 간략히 요약해본 내용입니다.
✔️ 자원을 효율적으로 관리하면서, 확장 가능한 Thread-per-Request 스타일로 작성합니다.
✔️ java.lang.thread API 수정을 최소화하면서 가상 스레드 사용할 수 있게 합니다.
✔️ 기존 JDK 툴을 사용하여 가상 스레드의 troubleshooting, debugging, profiling 지원합니다.
The thread-per-request style
각 사용자마다의 요청을 처리하기 위해, 각 요청을 처리하기 위한 전용 스레드를 할당하는 방식입니다.
이를 통해, 코딩 작업 뿐만 아니라 디버깅, 프로파일링이 용이하게 하며 이해하기 쉽게 만듭니다.
Requesting-handling code
하나의 요청의 시작과 끝은 하나의 thread가 처리하는 대신,
다른 I/O 연산을 기다릴 때마다 Java Thread를 Pool에 반환해서 다른 요청을 처리합니다.
Preserving the thread-per-request style with virtual threads
가상 스레드는 OS 스레드와 일대일 대응되지 않으며, 자바 런타임에서 구현되도록 합니다.
애플리케이션 코드는 가상 스레드에서 실행되며, CPU 연산 중일 시에만 OS thread를 소비합니다.
Implications of virtual threads
Virtual thread는 저비용으로 생성되기 때문에 pool로 저장해놓고 관리하지 않습니다.
대부분 짧은 수명과 얕은 호출 스택을 갖고 있으며,
주로 하나의 HTTP 요청이나 JDBC 쿼리와 같은 작업 수행합니다.
✔️ How to Use
Virtual Thread 는 Thread를 많이 만들어 로직을 처리하는 동작에서 큰 효과를 볼 수 있습니다.
사용법은 간단히 아래와 같이 사용할 수 있습니다.
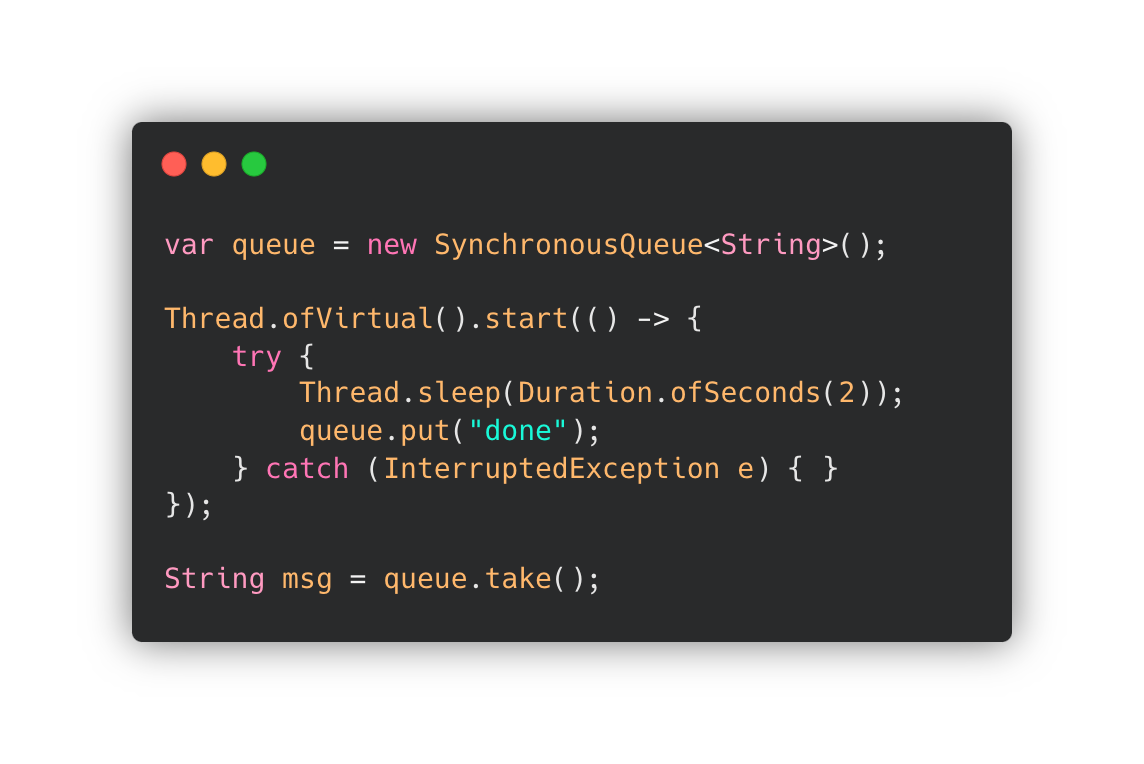
기존의 Java Thread 와 시간 차이를 위한 테스트를 진행해보았습니다.
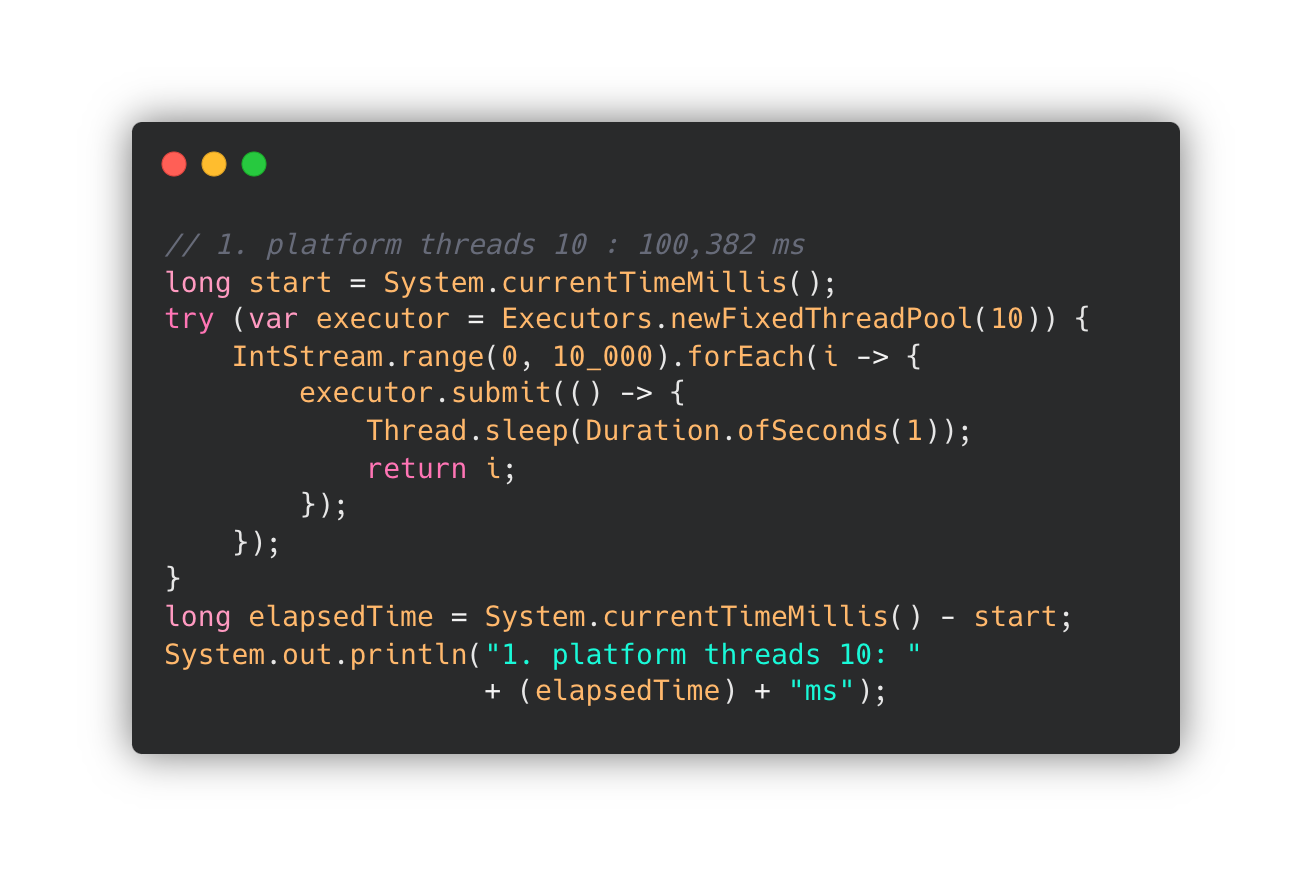

실제 실행에서도 100,382 ms / 1,024 ms 의 차이를 확인할 수 있었습니다.
Record Patterns
JDK 16의 JEP 394: Pattern Matching for instanceof 에서는
"JDK 11 ~ 17 Release, 제대로 이해하기" 참고
instanceof 연산자가 타입을 비교해서 ﹣ type pattern,
특정 객체의 내부 값을 매칭시켜 바로 가져오는 ﹣pattern matching 기능을 수행했습니다.
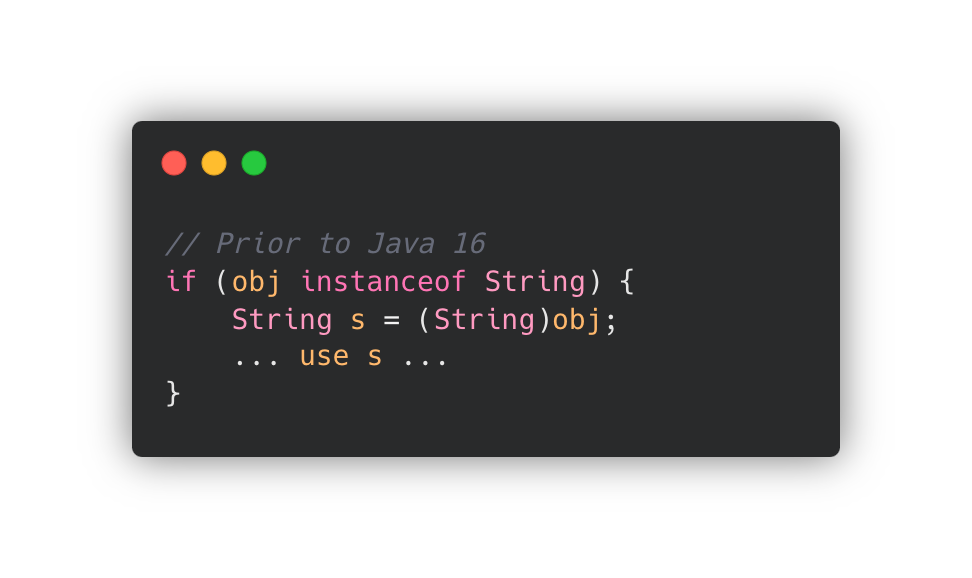
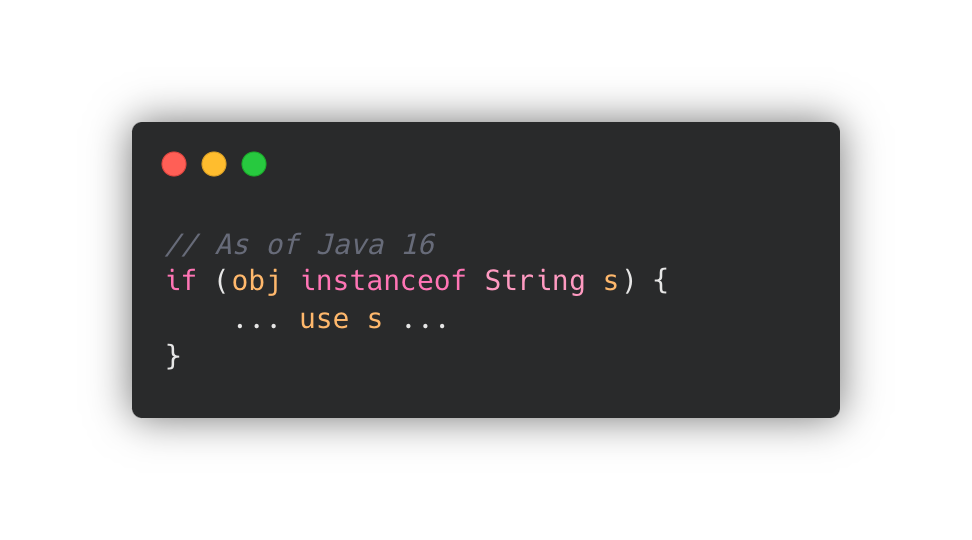
✔️ Type Pattern
위의 예제에서 obj 변수를 String이라는 '타입'으로 비교해서 s 변수로 할당하는데요.
이렇게 특정 대상을 타입으로 비교해서 할당하는 패턴을 Type Pattern 이라고 합니다.
fyi. dev.java: pattern-matching
이러한 Type Pattern은, 빈번하게 발생하는 캐스팅을 제거해서 많은 코드를 간결하게 줄여 줍니다.
TIP. String Type은 CharSequence Type을 확장하기 때문에 CharSequence 으로도 할당 받을 수 있습니다.
Type Pattern 을 Record 타입에도 활용할 수 있도록,
JDK 21 에서는 Records Patterns를 제공합니다.
✔️ Record Patterns
Records(JEP 395)는 데이터 처리를 위한 목적의 데이터 운반을 역할을 하는 데이터 클래스입니다.
Record 클래스의 인스턴스는 getter와 같은 접근 제어 컴포넌트만을 통해 데이터를 제공합니다.
Type Pattern을 사용하여 값이 Record 클래스의 인스턴스인지 확인하고,
맞다면, 해당 Record 의 내부 필드 값을 추출할 수 있습니다.

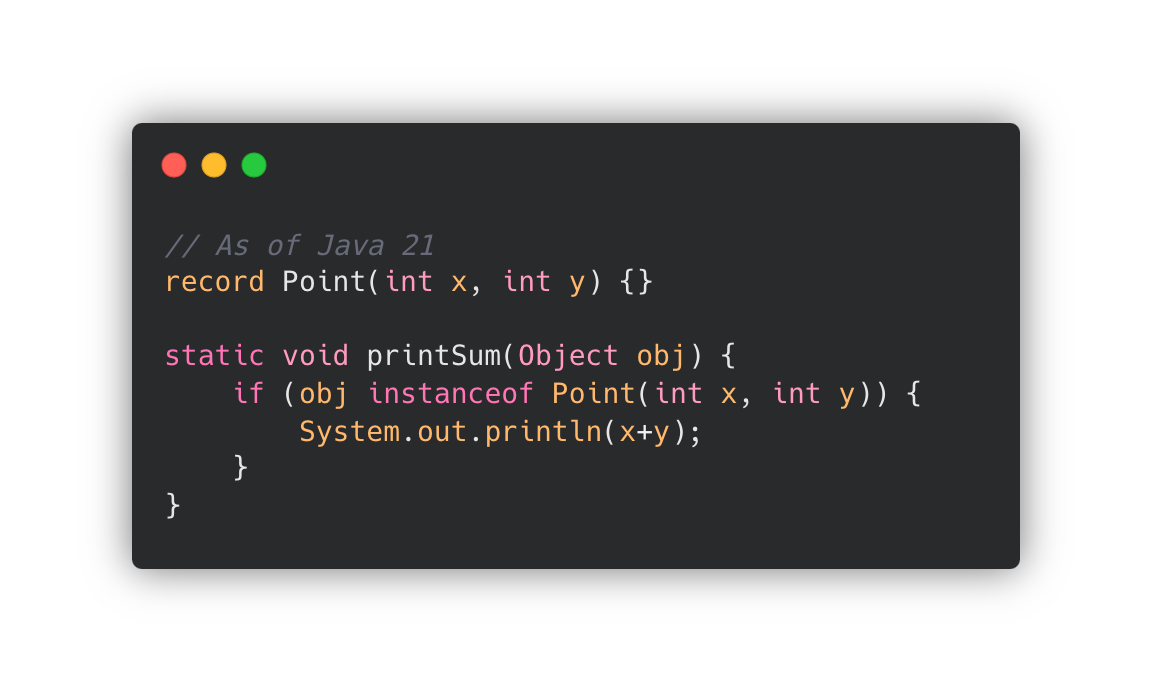
obj가 Point record 타입이라면, obj record의 컴포넌트를 x 와 y 값으로 추출해서 할당하라는 의미입니다.
JDK 16인 왼쪽 코드와 동일한 의미가 되죠.
Record 인스턴스가 중첩되어 있어도 Type Pattern을 모두 적용할 수 있습니다.
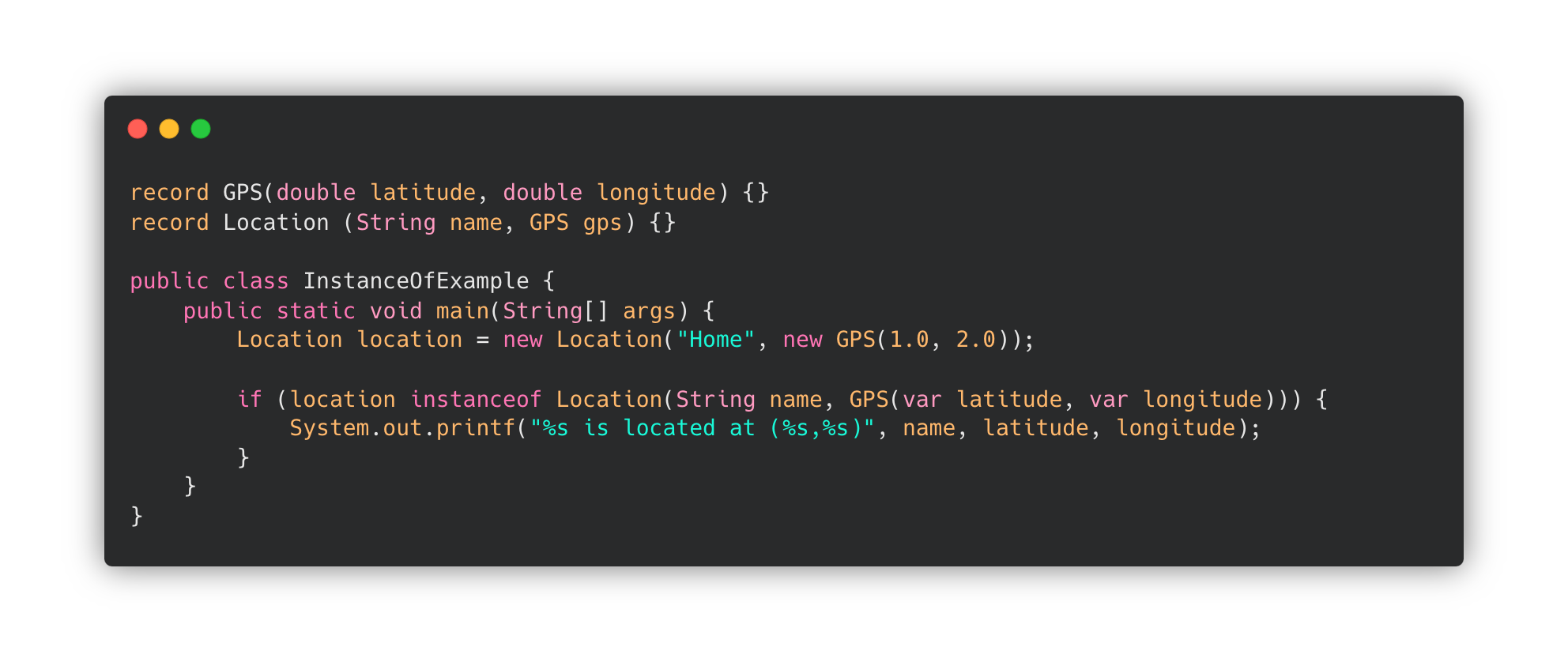
Pattern Matching for Switch
🔗 JEP 441: Pattern Matching for switch
위의 Record Pattern과 함께 진행되었으며, Pattern Matching을 Switch 문에서 사용할 수 있도록 지원합니다.
✔️ Overview
Pattern Matching은 가장 처음 JEP 406 (JDK 17) 을 시작으로 JEP 420 (JDK 18), 427 (JDK 19), and 433 (JDK 20)를 거쳐
위에서 본 Record Patterns 와 함께 점점 다듬어져 왔습니다.
instanceof 사용 시 if ... else 문의 Pattern Matching으로 간편하게 사용하고 코드를 줄일 수 있습니다.
하지만 아래 코드와 같이 체인처럼 많은 비교를 하게 될 수도 있습니다.
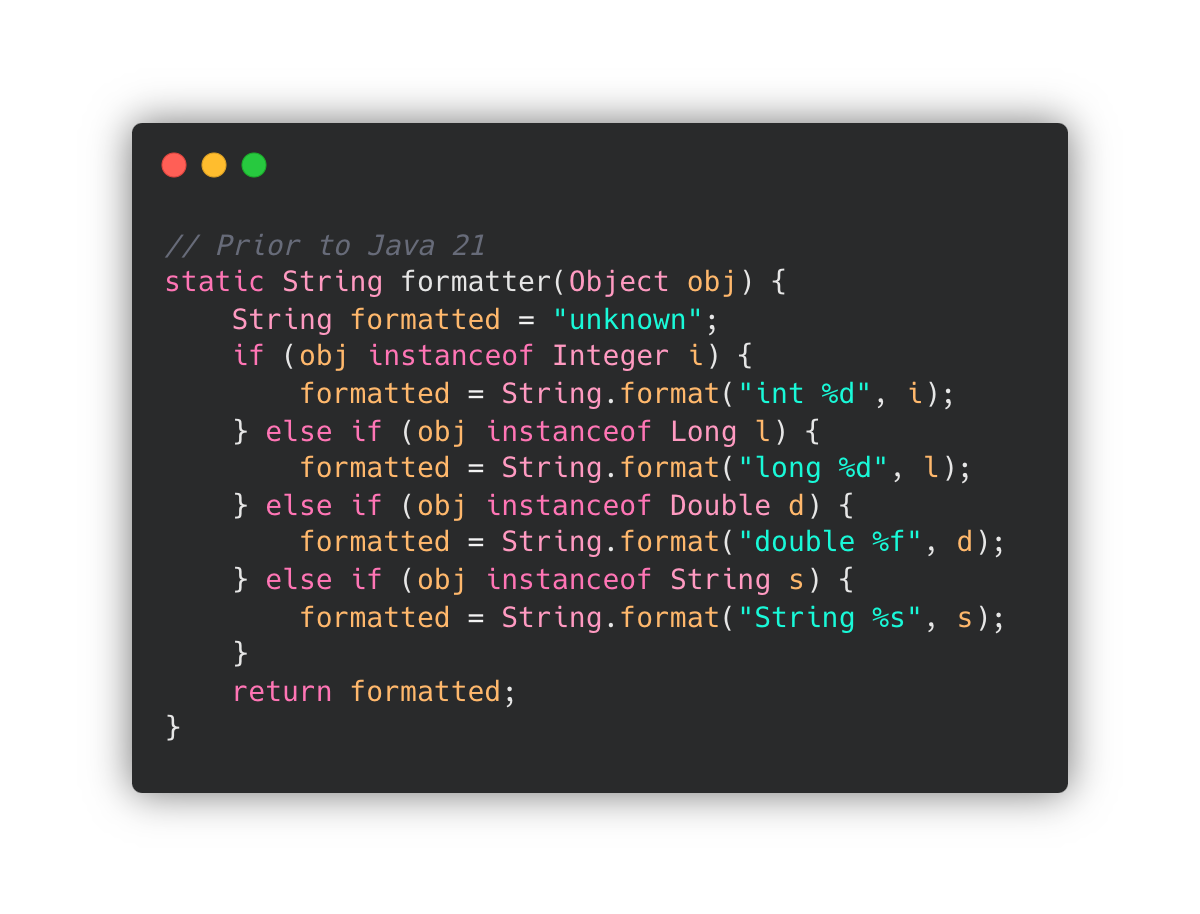
위 코드의 목적은 formatted 변수에 해당 타입을 넣는 시도를 하지만,
어떤 타입도 매칭되지 않으면 할당되지 않게 됩니다.
또, 큰 문제는 실제로 변수에 문자열을 할당하는 시간 복잡도는 O(1) 임에도 불구하고,
타입 수가 n 개 일 때 O(n) 시간 복잡도를 갖게 합니다.
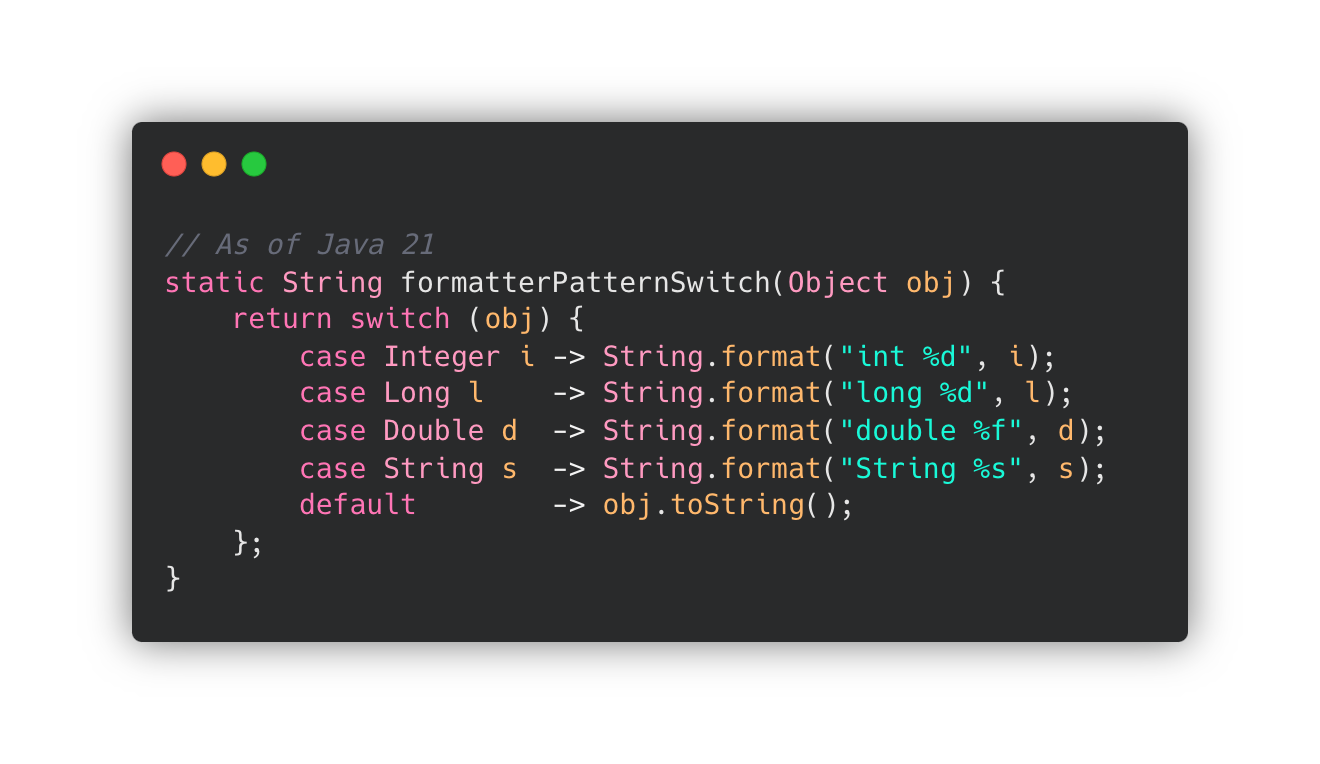
이런 불만은 switch 를 이용한 pattern matching이 가장 적합하게 해결해줄 수 있습니다.
Switch 문을 이용해 간단하게 expression 을 확장하고 Pattern Matching을 이용해서 값을 할당해 사용할 수 있습니다.
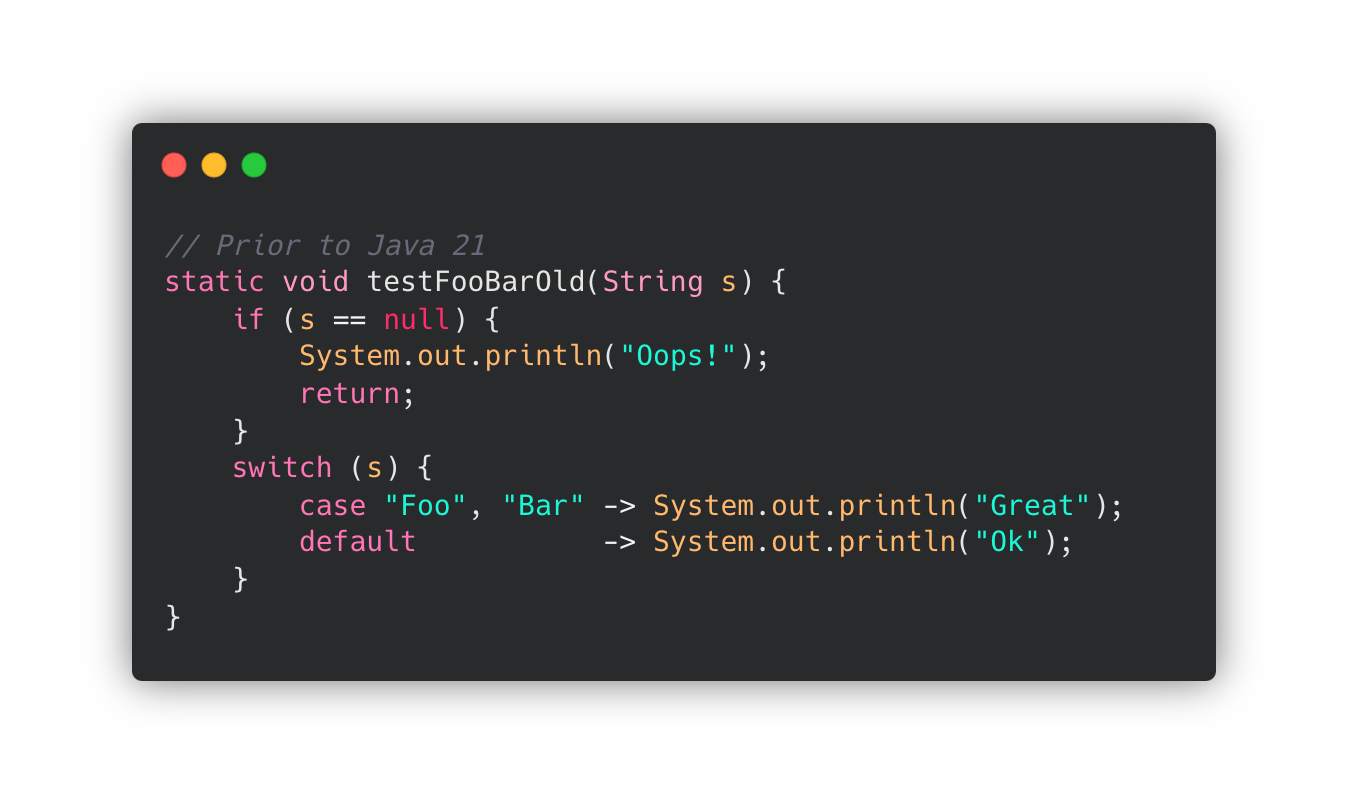
✔️ Switches and null
이전까지는, switch 문에 입력한 변수 expression 가 null 이라면, NullPointerException을 던졌는데요.
JDK 21 이후부터는 null label을 추가하여 스위치에 결합하여 사용할 수 있습니다.

✔️ Case refinement
Switch label 을 Pattern case 로 구분하다 보면, 아래 좌측 코드와 같이 실행 블록에 더 많은 조건문을 요구할 때가 생깁니다.
이는 사실상 아쉬운 확장성을 가지고 하나의 조건을 분기처리하는 것과 동일합니다.
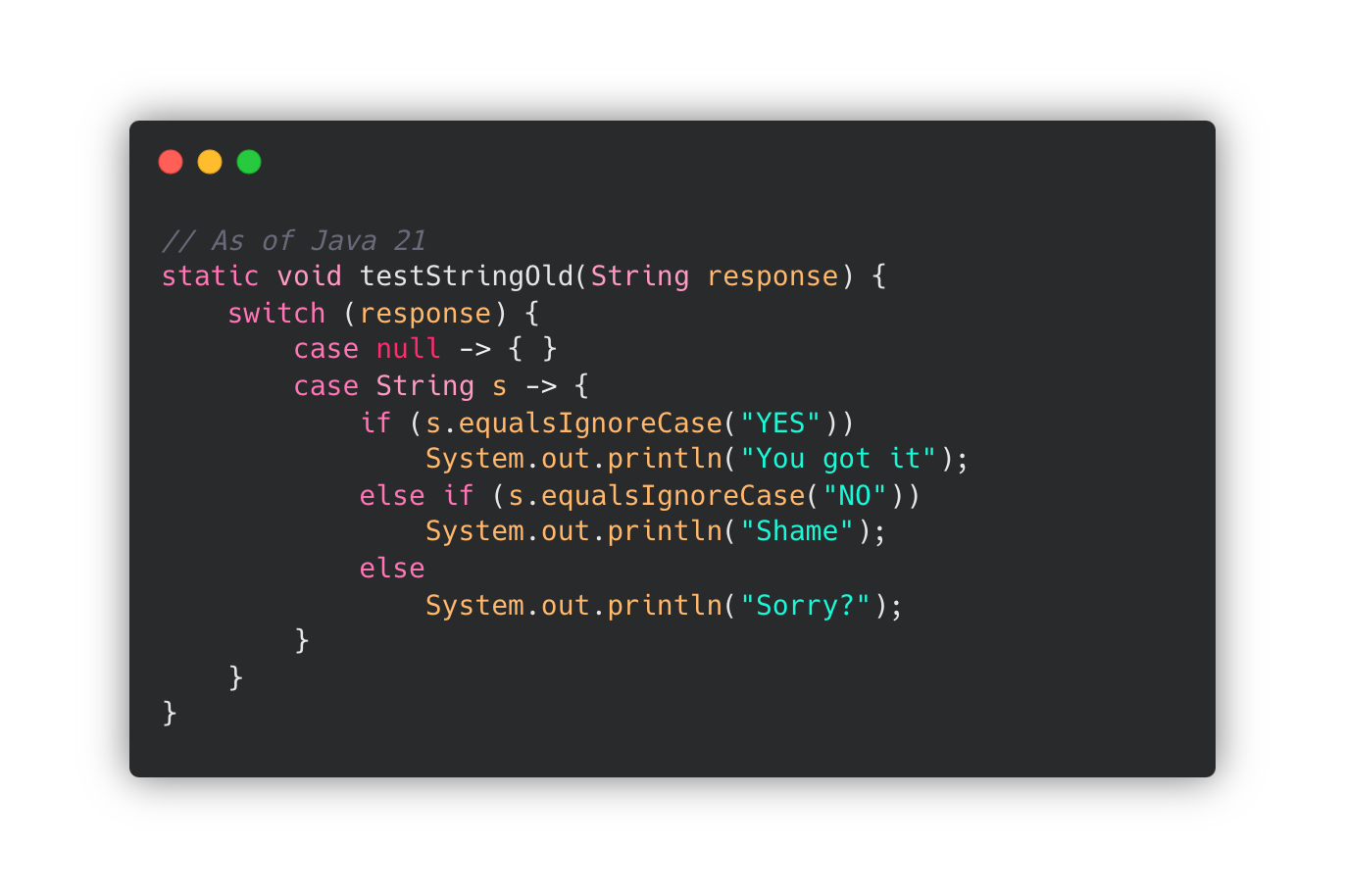

이 때, 아래 우측 코드와 같이 when 구문을 사용할 수 있습니다.
when 구문을 사용해서 명확하고 확장가능한 구문을 작성할 수 있습니다.
또한 Switch Pattern을 사용하면 모든 경우를 남김없이 처리하도록 Exhaustive 컴파일이 검증한다는 장점이 있습니다.
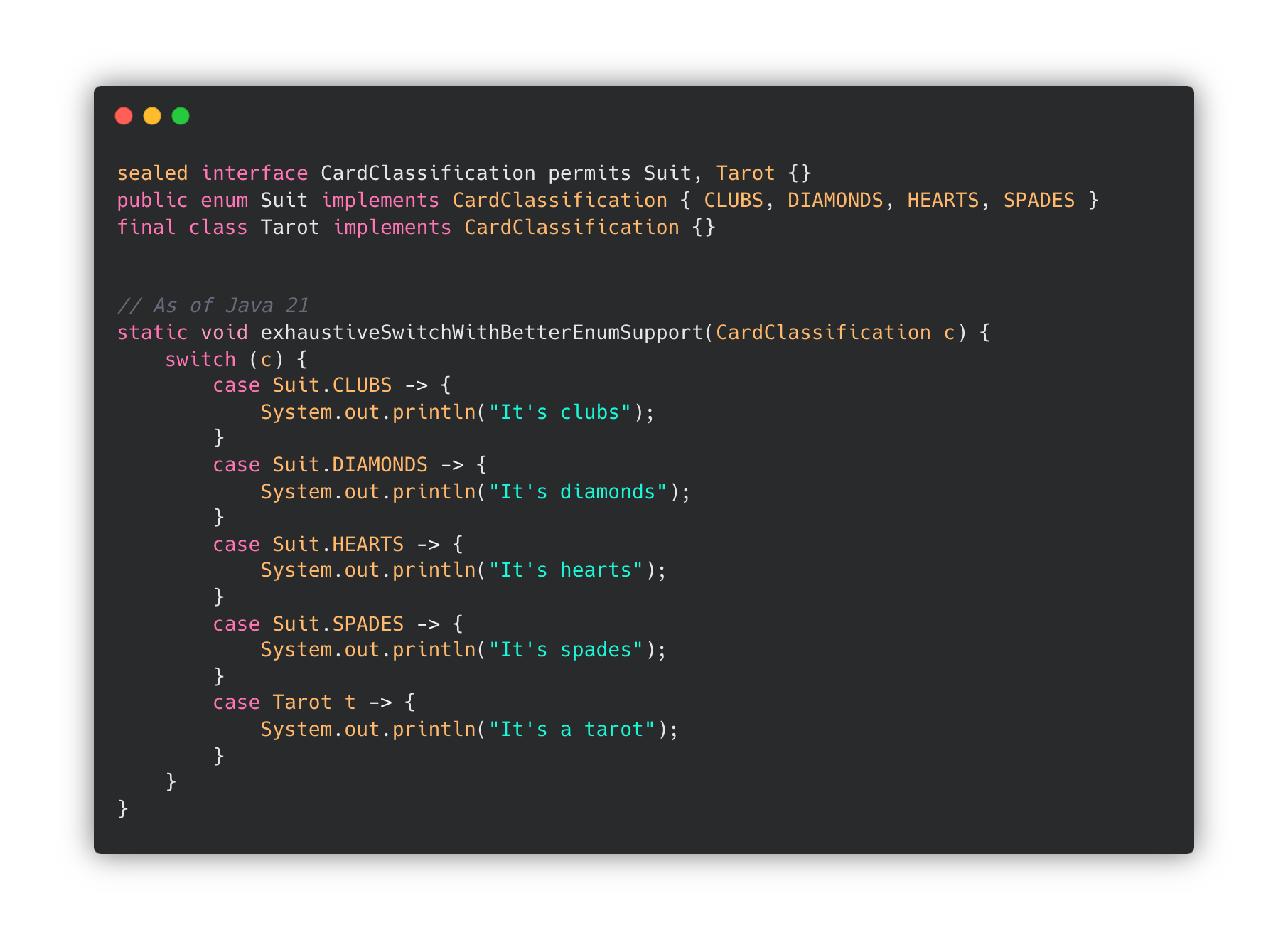
CardClassification 이 sealed 가 아닌 interface CardClassification {} 라면 다음과 같은 컴파일 오류가 발생합니다.
error: the switch statement does not cover all possible input values
항상 break 문을 추가해야하거나 아쉬움이 있던 비교 구문들을 개선하면서
switch 문이 점차 개선되고 있다는 것을 알 수 있었습니다.
ZGC
JVM은 Serial GC, Parallel GC, CMS GC, G1 GC 등 다양한 Garbage Collector를 연구하고 개발해왔습니다.
Garbage Collector에 대한 자세한 내용은 "Garbage Collector, 제대로 이해하기" 를 참고하실 수 있습니다.
ZGC(Z Garbage Collector)는 이 흐름에 이어 새롭게 등장한 Java의 garbage collector입니다.
가장 최근까지 사용되던 G1 GC는 메모리를 region이라는 논리적인 단위로 구분했습니다.
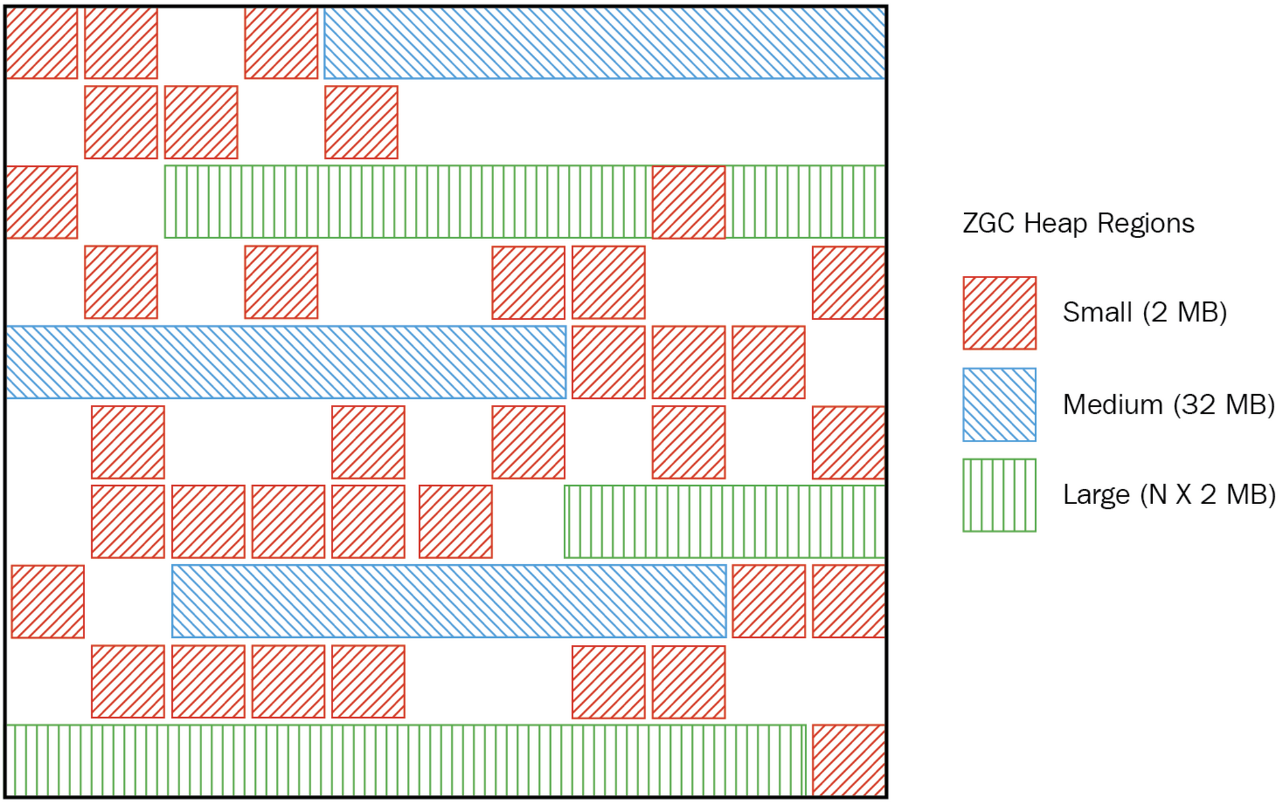
이 번에 기본 Garbage Collector로 채택된 ZGC는 메모리를 ZPage라는 논리적인 단위로 구분합니다.
OpenJDK의 ZPage 구조는 Github 링크를 통해 확인할 수 있습니다.
ZGC는 다룰 내용이 많기 때문에 해당 포스팅에서 자세한 내용은 생략하겠습니다.
다만, Naver D2에서 정리한 내용이 상세하여, 한 번 읽어보길 추천드립니다.
Bug Fixed
이번엔, JDK 21까지 수정된 버그들을 살펴보도록 하겠습니다.
✔️ Double.toString()
Double.toString(double) 은 최대한 작은 자릿수를 포함하는 실수를 문자열로 변환하도록 설계되었습니다.
하지만, 실제로 그렇지 않은 상황들이 있었습니다.
가령, 1e23과 9.999999999999E22가 같은 double인데,
1e23을 Double.toString(double)를 통해 문자열로 변경하려고 하면 "9.9999999999E22"를 반환했습니다.
JDK 19 에서 이를 업데이트 했습니다.
그 결과, JDK 19부터 생성된 문자열 중 일부가 이전보다 짧아졌습니다.
가령, 이전 JDK 릴리즈에서 "9.99999999999999E22" 를 반환했다면, JDK 19부터는 "1.0E23"이 반환합니다.
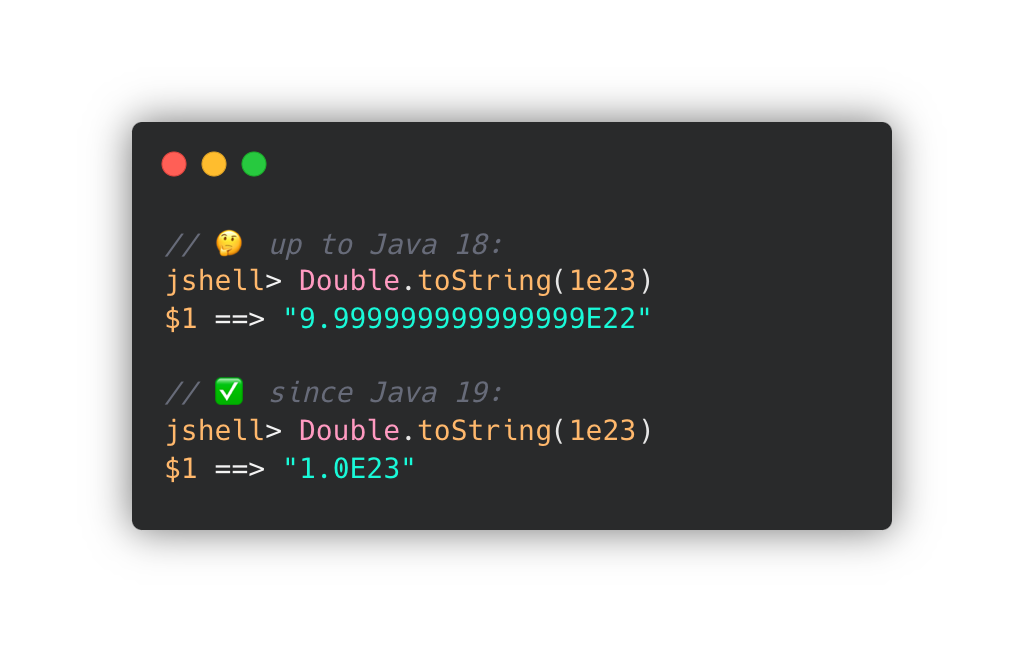
또, JDK 19 이후, Double.toString(double) 메서드에 9.99999999999999E22를 전달하면 동일한 값인 "1.0E23"을 반환합니다.
이밖의 다른 double과 float 의 문자열을 표현하는 형식들 또한, 위의 형식으로 통일되어 변경되었습니다.
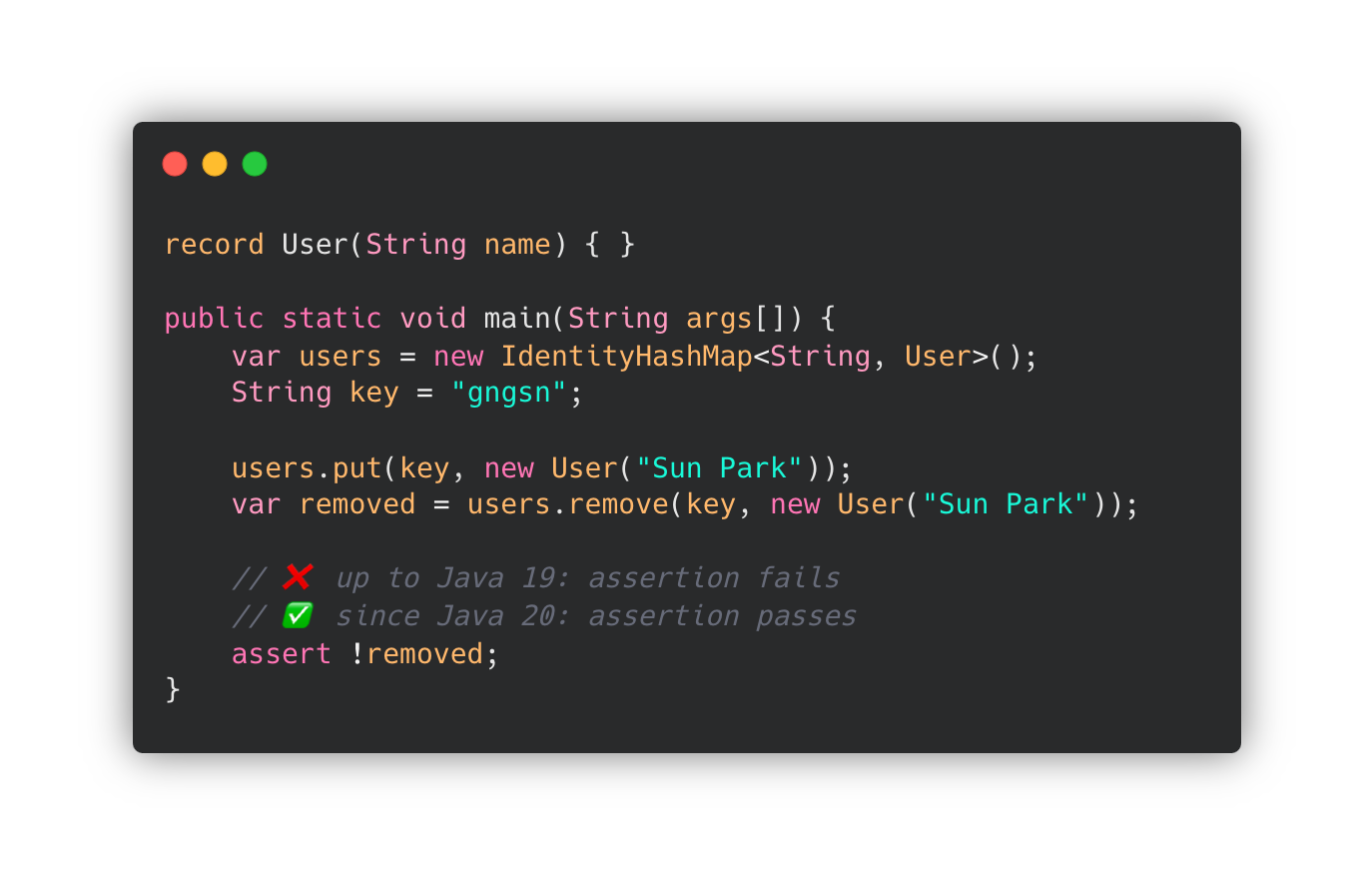
✔️ IdentityHashMap
IdentityHashMap의 메소드 remove(key, value)와 replace(key, value, newValue)는
"Identity" HashMap임에도 불구하고 value 값을 equals() 로 비교했습니다.
때문에, IdentityHashMap의 Value 값을 비교를 통한 remove(..) / replace(..) 메소드를 실행하면,
해당 String를 문자열 값(compared by identity) 이 아닌,
객체의 주소 값(compared by equality)으로 비교해서 원하는 동작을 하지 않았습니다.
JDK 20에서 부터는 이를 "Identity" 기반 비교로 수정하여 의도된 동작하도록 수정되었습니다.
📌 FYI. Identity vs Equality
Identity
For example:
Integer a = new Integer(1); Integer b = a;
a 는 b 와 일치 identity
Java 에서는, identity 를 == 기호로 비교합니다. (ex. a == b )
Equality
Integer c = new Integer(1); Integer d = new Integer(1);
c 는 d 와 동등 equality 하지만 일치 identity 하지는 않음
Java 에서는, equality 를 equals() 로 비교합니다. (ex. a.equals(b) )
그럼 지금까지 JDK 21까지의 릴리즈 노트를 확인해보았습니다.
| Reference |
https://openjdk.org/projects/jdk/21/
https://wiki.openjdk.org/display/zgc/Main#Main-JDK21
https://www.youtube.com/watch?v=5jIkRqBuSBs
https://www.infoq.com/news/2023/09/java-21-so-far/
https://theboreddev.com/understanding-java-virtual-threads/
https://medium.com/@RamLakshmanan/java-virtual-threads-easy-introduction-44d96b8270f8